Описание OneBridge
OneBridge - это система управления данными, разработанная для автоматизации сбора, преобразования и выгрузки данных в соответствии с заданными пользователем параметрами.
Система включает три основных компонента: Дизайнер, Сервер OneBridge и Панель администрирования.
- Дизайнер нужен для создания и редактирования сценариев обработки данных.
- Сервер Onebridge состоит из ядра и менеджера задач. Ядро управляет ресурсами и взаимодействует с внутренней базой данных, а менеджер задач нужен для оркестрации задач по выполнению сценариев обработки данных.
- Панель администрирования используется для наблюдения за употреблением ресурсов сервера, результатами обработки данных, настройкой отложенного выполнения сценариев, управления пользователями.
Набор готовых алгоритмов обработки упрощает процесс управления данными и ускоряет загрузку и выгрузку данных.
Система может взаимодействовать с различными источниками данных и позволяет проверить, очистить и получить качественные данные для дальнейшего использования.
Пользователи системы - разработчики, которые создают и поддерживают, например, корпоративные хранилища данных и нормативно-справочные информационные системы.
Схема работы Onebridge

Содержание раздела:
Функции OneBridge
Система выполняет графы по обработке данных (графы). Для запуска графа пользователю нужно выбрать файл с готовым набором алгоритмов обработки данных, указать параметры запуска и запустить граф в работу.
Взаимодействие пользователя с системой может происходить двумя способами:
- с помощью веб-приложения - Панель администрирования позволяет запустить графы в работу, отследить данные о состоянии сервера, настроить расписания запусков графов и обработчики событий;
- через локальное приложение Дизайнер - он используется для создания графов через визуальный редактор.
В обоих случаях после запуска графы обрабатываются в Сервер OneBridge.
Компоненты OneBridge
Дизайнер
Дизайнер - это локальное приложение для создания, редактирования, отладки и запуска графов. Подробное описание доступно в разделе Дизайнер.
Создание графов в дизайнере происходит с помощью графического интерфейса. Процесс создания графа описан в главе Создание графов.
Главные компоненты графов - узлы - представлены в виде прямоугольников, которые можно соединять друг с другом рёбрами и располагать в рабочей области нужным образом. С помощью дизайнера задаются параметры запуска, настраиваются соединения с базами данных, определяются метаданные.
Результатом создания, настройки и объединения компонентов является xml-файл с алгоритмом обработки данных, который можно запустить из дизайнера или из Панели администрирования. Обработка графов происходит на сервере Onebridge.
Панель администрирования
Панель администрирования предназначена для управления проектами, пользователями и ролями, для отслеживания истории выполнения графов и настройки расписаний их выполнения и обработчиков событий. Также возможно отслеживание данных о состоянии сервера системы. Подробнее об этом модуле в разделе Панель администрирования.
Панель администрирования состоит из нескольких компонентов:
- на странице «Ресурсы» отображаются показатели рабочего сервера системы и список графов, находящихся в процессе выполнения;
- страница «История выполнения» показывает историю запуска графов на выполнение и развёрнутую информацию о файлах графов;
- с помощью страницы «Проекты» можно увидеть дерево проектов, просмотреть подробную информацию о файлах графов и содержимое выбранного файла в текстовом или графическом виде.
- Расписания позволяют настраивать отложенный запуск графов.
- Обработчики событий могут совершать заданное действие в ответ на выполнение определённого пользователем условия.
- На странице "Пользователи" доступен просмотр и редактирование информации о пользователях.
Панель администрирования обеспечивает:
- отображение информации о ресурсах и производительности сервера;
- просмотр истории выполнения графов в виде таблицы;
- фильтрацию истории по времени выполнения графа, по названию файла исполняемого графа;
- просмотр информации о файле графа;
- просмотр алгоритма графа в графическом виде;
- просмотр журнала выполнения графа;
- отображение структуры хранения файлов с графами;
- выбор и запуск графа на выполнение;
- создание и редактирование расписаний и обработчиков событий;
- создание, редактирование и удаление проектов, папок и файлов с данными.
- создание, редактирование и удаление пользователей, их ролей и привилегий.
Сервер OneBridge
Сервер обрабатывает данные по алгоритму, который выбрал пользователь, и собирает статистику использования своих ресурсов. Сервер OneBridge состоит из инструкций по обработке данных и содержит программные интерфейсы для передачи необходимой информации в панель администрирования и взаимодействия с рабочими процессами. Подробнее про сервер в разделе Сервер OneBridge.
Сервер OneBridge обеспечивает:
- загрузку данных из источников - файлы CSV, базы данных;
- обработку данных по указанному алгоритму - сортировка, фильтрация, преобразование данных;
- отправку обработанных данных по указанному адресу - запись в файл, в базу данных, в корпоративное хранилище данных;
- администрирование расписаний и обработчиков событий;
- распределение нагрузки между рабочими процессами, которые загружают и обрабатывают данные.
Установка и активация OneBridge
- Установка сервера Onebridge
- Конфигурация сервера OneBridge
- Установка Дизайнера
- Активация OneBridge
- Установка ODBC
Установка сервера Onebridge
Все описанные ниже действия должны производиться на устройстве с операционной системой Ubuntu (поддерживается верси Ubuntu 22.04.3 LTS), либо на виртуальной машине с ОС Ubuntu.
Персонализированнную ссылку на скачивание вашей версии продукта вы получите после подписания лицензионного договора.
Перед началом работы необходимо установить Wget — (GNU Wget) свободную консольную программу для загрузки файлов по сети.
Затем:
- Открыть командную строку и выполнить команды:
- для скачивания приложения OneBridge с сайта modernsolution.ru:
wget *ссылка на актуальную версию OneBridge*
- для установки скачанных файлов приложения OneBridge:
sudo apt install ./onebridge.deb -y
Вместе с файлами приложения OneBridge будут установлены зависимости из следующего списка: build-essential, linux-libc-dev, pkg-config, libssl-dev, libssl3, libgcc-s1, libc6.
После установки файлы OneBridge будут размещены в директории /opt/OneBridge/bin/.
- Перейти в вышеуказанную директорию с помощью команды
cd /opt/OneBridge/bin/. - Запустить приложение из директории
/opt/OneBridge/bin/, введя команду:./startup.sh
В случае успешной установки будет получен ответ: Startup.
При первом запуске будет запущен сценарий активации вашей копии продукта. Подробнее процесс описан в разделе Активация OneBridge. После активации нужно запустить приложение повторно.
Для подключения к модулю управления нужно открыть браузер на этой же операционной системе и ввести в поисковую строку локальный ip-адрес и порт подключения вот таким образом: 127.0.0.1:8000.
Откроется начальная страница приложения, с которой можно перейти на любую другую страницу из меню.
Список рекомендуемых браузеров: Google Chrome, Яндекс Браузер, Opera.
Конфигурация сервера OneBridge
Параметры конфигурации системы указываются в файле config.toml в корневой папке проекта. Возможна настройка таких параметров как:
адрес подключения интерфейса, параметры авторизации, расположение файлов с логами запусков графов и других. В таблицах ниже все настраиваемые в конфиге параметры описаны более подробно.
http
| Имя параметра | Описание параметра | Пример значения параметра |
|---|---|---|
| addr | bind address (адрес интерфейса + порт), приоритет отдаётся значению переменной окружения ONEBRIDGE_HTTP_BIND_ADDRESS | addr = "127.0.0.1:8000" |
| ui_path | путь к папке с ui | ui_path = "../ui/dist" |
resources
| Имя параметра | Описание параметра | Пример значения параметра |
|---|---|---|
| interval | интервал сбора статистики сервера (равен горизонтальному интервалу между точками на графиках во вкладке ресурсов) | interval = 5 |
execution
| Имя параметра | Описание параметра | Пример значения параметра |
|---|---|---|
| run_storage.sqlite | путь к файлу с информацией о запусках графов | path = "../data/sqlite-storage/execution_run.sqlite" |
| run_params_storage.sqlite | путь к хранилищу параметров запусков | path = "../data/sqlite-storage/execution_run_params.sqlite" |
| worker.embedded | путь к хранилищу журнала выполнения запусков | job_logs_path = "../data/job-logs" |
projects
| Имя параметра | Описание параметра | Пример значения параметра |
|---|---|---|
| fs.mounted | путь к проектам | path = "../projects" |
auth
| Имя параметра | Описание параметра | Пример значения параметра |
|---|---|---|
| path | путь к хранилищу пользователей | path = "../data/sqlite-storage/users_storage.sqlite" |
| exp_long | экспирация длинного токена (рт), в секундах | exp_long = 86400 |
| exp_short | экспирация короткого токена (ат), в секундах | exp_short = 86400 |
| at_secret | сид для генерации токена доступа | at_secret = "87ac0287d16540e3f9cb307327411ffb39bb4008" |
| rt_secret | сид для генерации токена обновления | rt_secret = "390aed9f00981f4a4c9ae2c1a5e4c115d56f6101" |
| api_tokens | спецтокен для доступа ко всем апи | api_tokens = ["test"] |
| ldap_dn | параметры для подключения к базе ldap | ldap_dn = "uid={},ou=onebridge,dc=example,dc=org" |
| ldap_addr | ip и порт ldap сервера | ldap_addr = "127.0.0.1:389" |
| auth_tries | количество попыток авторизации (после использования всех попыток, пользователь блокируется) | auth_tries = 5 |
Установка Дизайнера
Дизайнер поставляется в zip-архиве. Архив содержит папки "cash", "config", "projects", "templates" и файл запуска приложения client.exe.
Для запуска достаточно распаковать архив в предпочитаемую директорию файловой системы и запустить файл client.exe.
Все проекты, скачиваемые с сервера и создаваемые локально по умолчанию будут устанавливаться в папку "projects". Файлы в "templates" содержат параметры и описания компонентов и настройки соединений с базами данных. В "config" лежат файлы конфигурации Дизайнера. В "cash" могут создаваться временные файлы, используемые во время работы.
Активация OneBridge
Активация позволяет убедиться, что ваша копия OneBridge не используется на нескольких устройствах и содержит заявленную версию продукта.
Чтобы активировать вашу копию OneBridge, нужно будет разместить ключ активации в папке ./data/license. Ключ активации представляет собой файл с расширением .lic, который можно получить от сотрудника поддержки OneBridge. Процедура активации однократная и выполняется только при первом запуске системы.
При первом запуске OneBridge создаст папку ./data/license и сгенерирует файл с вашим machine-id. Путь к файлу будет прописан в консоли. Этот файл нужно будет передать сотруднику поддержки СБАР. В ответ вы получите другой файл, который нужно будет положить в папку рядом с machine-id и повторно запустить установку. В случае успешной проверки указанных файлов OneBridge будет активирован и вы сможене использовать все его функции.
При необходимости активации на новом устройстве, нужно будет повторить процедуру обмена файлами при первом запуске системы на этом устройстве.
Установка ODBC
Для доступа к базам данных OneBridge позволяет использовать ODBC. Для работы с конкретной базой понадобится установить соответствующий драйвер.
Ниже приведён пример установки ODBC и драйверов к нему на Linux.
Установка unixodbc
apt install unixodbc-dev
Установка iodbc
apt install odbcinst
Конфигурация odbc
- Файл odbcinst.ini содержит информацию о драйверах доступных всем пользователям.
- Файл odbc.ini содержит информацию о DSN доступных для всех пользователей.
Пример содержимого odbcinst.ini:
[PostgreSQL]
Description = PostgreSQL driver for Linux & Win32
Driver = /usr/local/lib/libodbcpsql.so
Setup = /usr/local/lib/libodbcpsqlS.so
FileUsage = 1
Заголовок содержит имя драйвера, в последствии используемое в odbc.ini
Description - описание драйвера
Driver - путь к драйверу
Setup - путь к библиотеке, используемой для установки (важно для GUI)
Пример содержимого odbc.ini:
[PostgreSQL]
Description = Test to Postgres
Driver = PostgreSQL
Trace = Yes
TraceFile = sql.log
Database = nick
Servername = localhost
UserName =
Заголовок - имя DSN
Description - описание DSN
Driver - псевдоним драйвера из odbcinst.ini либо можно указать путь до драйвера
Установка драйверов
Установка драйвера для postgres
Установка драйвера firebird
Password =
Port = 5432
Protocol = 6.4
ReadOnly = No
RowVersioning = No
ShowSystemTables = No
ShowOidColumn = No
FakeOidIndex = No
ConnSettings =
Заголовок - имя DSN
Description - описание DSN
Driver - псевдоним драйвера из odbcinst.ini либо можно указать путь до драйвера
Установка драйверов
Установка драйвера для postgres:
apt-get install odbc-postgresql
Установка драйвера firebird:
apt-get install libfbclient2
Глоссарий
Узел (нода) – минимальный алгоритм обработки информации.
Атрибут узла (ноды) - настройка, с помощью которой можно управлять выполнением каждого узла.
Граф - последовательность компонентов для обработки данных, записанная в файл. Для создания графа используются узлы, рёбра, метаданные и другие компоненты.
Ребро узла соединяет два узла и передает поток данных между ними. Чтобы данные могли пройти по ребру, ему назначаются метаданные.
Метаданные описывают структуру данных, проходящих по ребру. Мета состоит из названий полей и их типов данных.
Входной порт - точка входа потока данных в узел.
Выходной порт - точка выхода потока данных из узла.
Трансформация - код, который определяет, как входные данные преобразуются в выходные данные при прохождении через узел.
Параметр (графа) - неизменяемое значение, используемое для настройки работы графа. Значение параметра задаётся перед запуском и не может быть изменено в процессе работы графа.
Переменная - изменяемое значение, которое может меняться в процессе работы графа и передаваться между графами.
Расписание – график запуска графов. Позволяет настроить запуск графов в конкретное время.
Обработчик событий - инструмент для отслеживания изменений, таких как запуск графа или создание файла, и совершения запланированных действий.
Соединение - строка с настройками для подключения к базе данных.
Воркер — это независимый процесс, который отвечает за обработку графов. Каждый граф запускается в своей отдельной копии воркера, что позволяет одновременно выполнять несколько графов независимо друг от друга. Внутри каждого воркера узлы графа обрабатываются параллельно, используя механизм выделения отдельного потока для каждого узла.
Справочник - внутренняя таблица для быстрой работы с данными в рамках графа.
Дизайнер
Дизайнер - это локальное приложение для создания и запуска графов.
Все файлы хранятся на сервере, упорядоченные по проектам. OneBridge поддерживает синхронизацию файлов между Дизайнером и сервером, так что ситуации дублирования или потери изменений исключены. Подробнее об устройстве проектов и синхронизации рассказано в главе Проекты.
Создание и редактирование графов в Дизайнере происходит с помощью графического интерфейса на вкладке Ui. Главные компоненты графов - Узлы - представлены в виде прямоугольников, которые можно соединять друг с другом рёбрами и располагать в Рабочей области нужным образом. Задание свойств узлов осуществляется через Редактор узла.
Выполнение графов и отслеживание результатов описано в главе Выполнение графов.
Результатом изменений в Рабочей области является автоматически создаваемый xml-файл, в котором прописан алгоритм обработки данных. Текст файла отображается на вкладке Source. Обработка алгоритма происходит на Сервере Onebridge.
Интерфейс Дизайнера
Интерфейс Дизайнера состоит из нескольких панелей:
-
Рабочая область со списком компонентов находится в верхней правой части окна. На этой панели вы можете создавать свои графы. Рабочая область имеет две вкладки - Ui и Source. Список компонентов (панель Components) служит для выбора компонентов, которые можно переместить в Рабочую область для создания графа.
-
Обозреватель проектов (панель Project structure) находится в верхней левой части окна. На этой панели находятся файлы проектов. Открывать любые файлы можно двойным щелчком - они будут открыты в Рабочей области.
-
Структура графа (панель Outline) находится в нижней левой части окна. Панель содержит списки всех частей графа, открытого во вкладке Ui в данный момент, разделенных по группам: Components, Metadata, Parameters, Connections, Dictionary и Lookup table.
-
Панель состояний (Console) находится в нижней части окна. Она содержит несколько вкладок с уточняющей информацией.
Над панелью Project structure находится главное меню:
- File - для управления сохранением и открытием файлов
- Run - пункты для запуска графов и их остановки
- View - для управления отображением на Рабочей области (сетка, метаданные на ребрах)
Обзор панелей Дизайнера

Проекты OneBridge
Все файлы хранятся на сервере упорядоченные по проектам. Проекты могут быть скачаны локально в Дизайнер и автоматически синхронизируются в веб-приложении.
Когда проект создаётся локально в Дизайнере - он появляется и на сервере. Для того чтобы скачать проект с сервера в Дизайнер, нужно авторизоваться и выбрать нужный проект, тогда он будет скачан.
Обозреватель проектов
В левой части окна Дизайнера находится панель Обозреватель Проектов. На этой панели можно развернуть папки проектов, просмотреть имеющиеся в проектах файлы.
Структура папок проекта внутри Обозревателя проектов

Каждый из проектов будет иметь стандартную структуру проекта, если её не изменить при создании проекта.
Стандартная структура подразумевает набор подпапок в проекте, которые появляются, если при создании проекта стояла галочка "создать проект по шаблону". Ниже в таблице представлено описание шаблонных подпапок.
| Стандартное имя папки | Описание |
|---|---|
| conn | Для файлов с описаниями соединений с базами данных |
| data-in | Для файлов и таблиц, в которых содержатся входные данные |
| data-out | Для файлов и таблиц, в которые предполагается записать выходные данные |
| data-tmp | Для временных данных, создаваемых на время работы графов |
| graph | Папка, содержащая графы |
| meta | Для файлов с описанием внешних метаданных |
| param | Для файлов с описанием внешних параметров |
Так же будет создан файл Workspace.prm, содержащий стандартные параметры проекта.
| Параметр | Описание |
|---|---|
| PROJECT | Корневой путь проекта |
| CONN_DIR | Папка по умолчанию для внешних подключений |
| DATAIN_DIR | Папка по умолчанию для файлов входных данных |
| DATAOUT_DIR | Папка по умолчанию для файлов выходных данных |
| DATATMP_DIR | Папка по умолчанию для файлов временных данных |
| GRAPH_DIR | Папка по умолчанию для графов (.grf) |
| META_DIR | Папка по умолчанию для внешних метаданных (.fmt) |
| PARAM_DIR | Папка по умолчанию для файлов параметров (.prm) |
Создание и подключение проектов
Изначально в Дизайнере не будет проектов, пока не создано подключения к какому-либо серверу. После подключения проекты можно скачать с сервера или создать локально.
Для подключения к серверу, нажмите правую кнопку мыши в области панели Project structure и выберите New server в контекстном меню.
В параметрах подключения укажите URL сервера в формате http://ip-adress:port, логин и пароль пользователя, имеющего доступ. Проверить подключение можно с помощью Test Connection. Чтобы подключиться, нажмите Log in. Чтобы не вводить атрибуты подключения при следующем подключении к проекту с того же сервера, можно отметить чекбокс Remember me.
Затем выберите проект из существующих на сервере или создайте новый, нажмите Next. Проверьте имя проекта и завершите подключение, нажав Finish.
Подключение к новому проекту

Выбор существующего или создание нового проекта

Размещение проекта

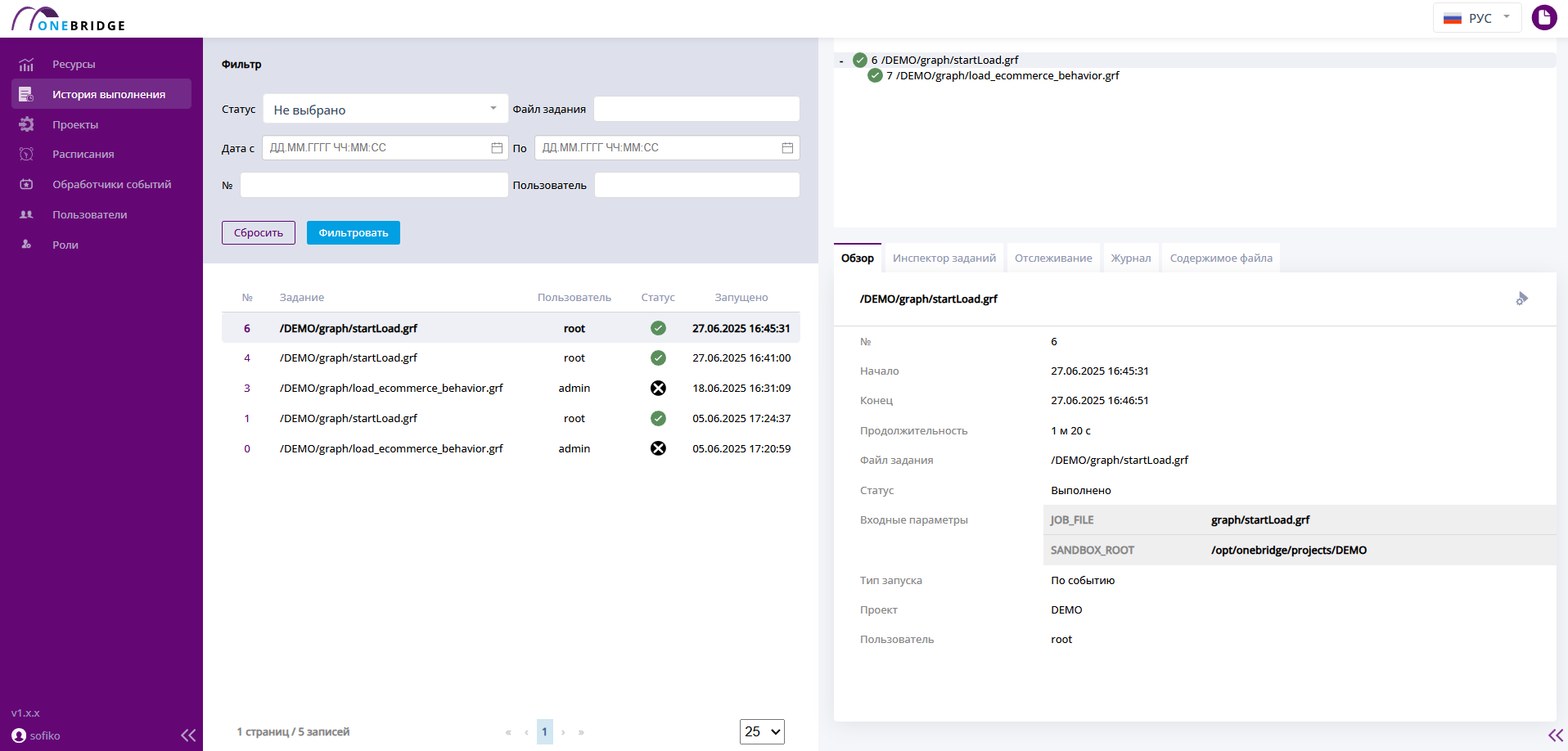
После скачивания проекта файлы с размером, превышающим 1Mb, будут отображаться со значком Download и постфиксом-downloadable в названии расширения. Это значит, они не скачались вместе с остальными файлами проекта потому что слишком большие. Но их можно скачать принудительно, выбрав в меню файла пункт Download.
Действия с файлом на панели Project structure
Создание графов
Граф OneBridge — это наименьшая исполняемая единица рабочего процесса. В графе описан процесс преобразования данных.
После создания проекта вы можете создать новый граф, выбрав в контекстном меню проекта New grf file.
Действия с проектом на панели Project structure
Задайте имя графа в открывшемся диалоговом окне. Граф будет помещен в выбранный проект. Расширение .grf будет добавлено к заданному имени автоматически. Затем в панели Project structure появится файл new-graph.grf. Он автоматически откроется в рабочей области сразу после создания.
После создания файл открывается в рабочей области
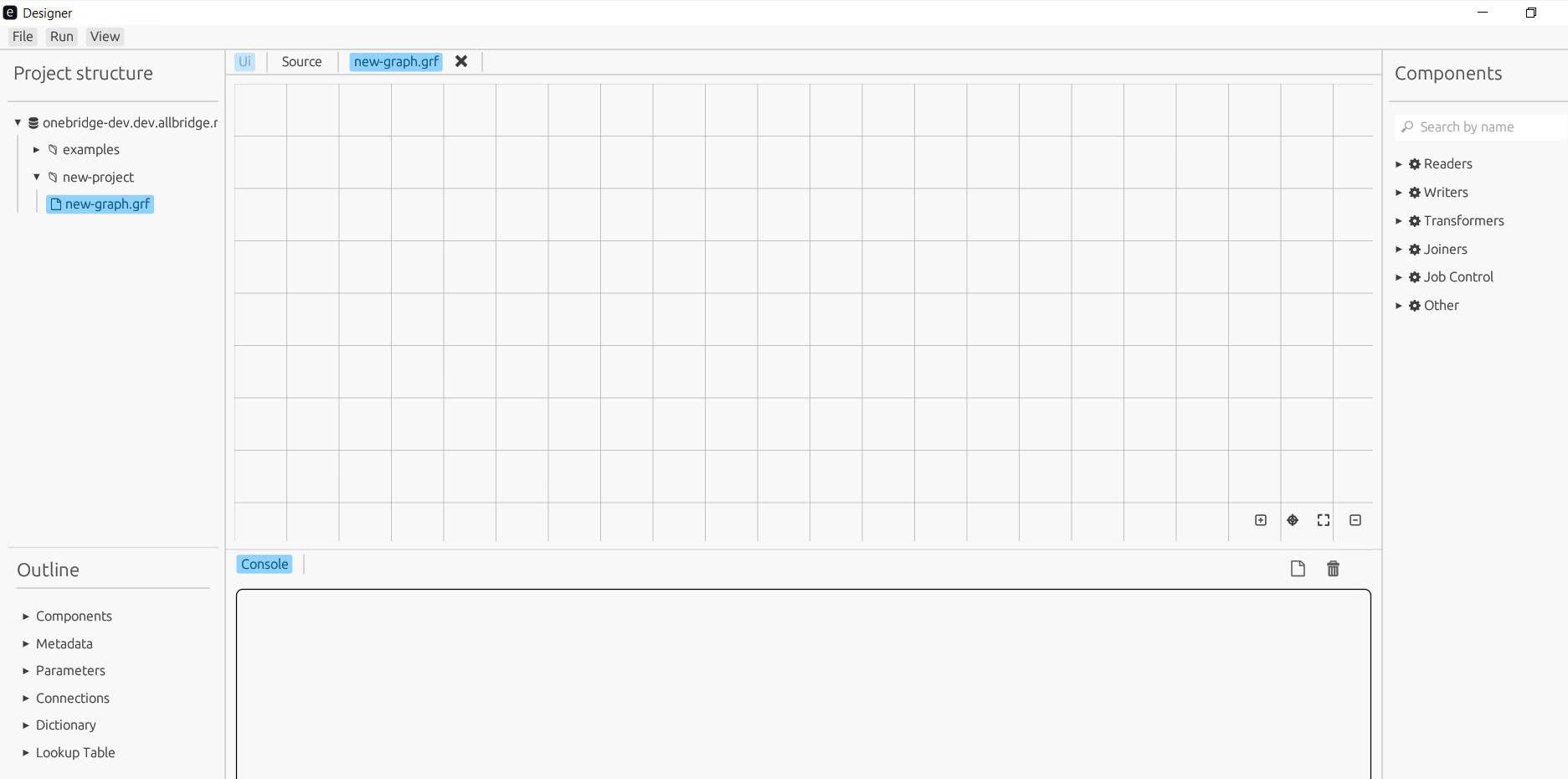
В верхнем меню во вкладке View можно настроить отображение сетки (Grid), прилипание (Sticking) и отображение метаданных на ребрах (Show metadata).
Настройка отображения вспомогательных элементов
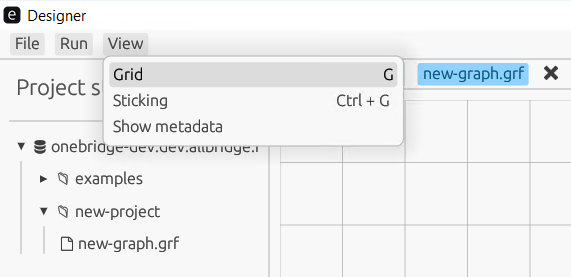
Далее в этой главе описываются следующие темы:
- Размещение компонентов
- Редактор узлов
- Соединение компонентов рёбрами
- Структура графа
Размещение компонентов
Чтобы создать граф для обработки данных, нужно наполнить граф компонентами. Все доступные к использованию компоненты находятся на правой панели Компоненты.
Найдите узел FlatFileReader среди узлов группы Readers. Перетащите его из списка компонентов в Рабочую область.
Размещение первого компонента в Рабочей области

Сделайте то же самое с FlatFileWriter из группы Writers. Поместите их в ряд, слева направо.
Размещение компонента для записи

Перемещение нескольких компонентов
Для того чтобы переместить компонент, нужно захватить его курсором и перетянуть в нужное место, затем отпустить. Для перетаскивания нескольких компонентов нужно сначала выделить их, затем перетаскивать все вместе.
Для множественного выделения нужно зажать CTRL и затем кликнуть на все компоненты, которые нужно выделить. Либо зажать CTRL и курсором нарисовать прямоугольник вокруг нужных компонентов.
Выделенные компоненты получают жирную чёрную рамку. Рёбра всегда выделяются вместе с узлом, из которого выходят.
Чтобы сбросить выделение, зажмите CTRL и кликните на пустом пространстве Рабочей области.
Добавление заметок
Еще одним видом компонентов являются заметки - в них можно записать дополнительную информацию к графу, например, объяснить логику работы сложного графа. Заметка всегда располагается под узлами и может служить контейнером для них. Чтобы закрепить узел на заметке, атрибуту узла parent присваивается значение id заметки - parent="Note0". В рабочей области во вкладке Ui в правом верхнем углу узла появится значок замка, это значит, что данный узел закреплен на заметке.
Компонент Note (заметка) можно найти на панели компонентов в группе Others. Перетащив заметку на рабочую область можно задать ей размер, потянув за правый нижний угол.
Добавление заметки к графу

Дважды кликните на область заметки, чтобы открыть редактор текста заметки. Атрибуты заметки настраиваются в редакторе на вкладке Attributes.
Редактирование текста заметки

Изменение атрибутов заметки

Когда граф и все входные данные для него готовы, можно запустить его в работу. Запуск и выполнение подробно описаны в следующей главе - "Выполнение графов".
Редактор узлов
Для того чтобы настроить или изменить значения атрибутов узла, используйте Редактор узла. Его можно открыть дважды кликнув по пустому пространству на поверхности узла. Чтобы сохранить изменения значений атрибутов, нажмите Save. Для отмены всех внесённых изменений - Cancel.
Настройка узла в Редакторе

Соединение компонентов рёбрами
Теперь нужно соединить компоненты ребром. Для этого есть два способа:
- Можно нажать на выходной порт FlatFileReader, появится ребро красного цвета с незакреплённым концом. Перетащите свободный конец ребра на входной порт FlatFileWriter.
- Быстрое соединение - зажать курсором выходной порт первого узла и протянуть, не отпуская, до входного порта второго узла.
Соединение компонентов ребром

Ребро по-прежнему красного цвета, поскольку ему не назначены метаданные. Чуть ниже описано создание и присвоение метаданных ребру.
Структура графа
Все компоненты, используемые в текущем графе, отображаются на панели Outline.
Щелкнув по имени компонента вы перейдёте в редактор выбранного узла.
Список компонентов текущего графа

Создание и присвоение метаданных ребру
Чтобы передавать данные между компонентами графа, необходимо задать метаданные и присвоить их рёбрам графа. Метаданные в графе можно задать тремя способами:
- Создать через редактор метаданных.
- Подключить файл с внешними метаданными.
- Скопировать метаданные из другого графа и вставить в текущий.
1) Создание метаданных в редакторе метаданных
На панели Outline откройте контекстное меню группы Metadata -> New Metadata, откроется редактор метаданных.
Здесь можно задать имя метаданных и разделитель записей. Чуть ниже определить имена, типы и разделитель полей.
Кнопкой + создайте новую запись и укажите ее атрибуты. Сохраните изменения кнопкой Save.
Создание метаданных

2) Подключение файла с внешними метаданными
Для подключения внешних метаданных нужно указать ссылку на файл, в котором они описаны. На панели Outline в контекстном меню группы Metadata выберите Link metadata. В поле fileURL укажите путь к файлу с описанием метаданных.
Подключение файла метаданных

3) Копирование метаданных из другого графа
Метаданные можно копировать из графа в граф. Для этого в панели Outline откройте контекстное меню нужных метаданных -> Copy metadata.
В графе, в который метаданные нужно вставить, в панели Outline откройте контекстное меню блока Metadata -> Paste metadata.
При попытке вставить метаданные с именем, аналогичным тому, что уже есть в графе - они будут вставлены с постфиксом "Copy + номер копии".
Назначение метаданных ребру
Назначить созданные метаданные ребру графа возможно несколькими способами:
- В контекстном меню ребра выберите пункт Edit, откроется редактор ребра. Для атрибута
Metadataвыберите из выпадающего списка нужное имя метаданных, сохраните изменения кнопкой Save. - Перетащить на ребро нужные метаданные с панели Outline методом drag-and-drop.
Назначение метаданных

Метаданные назначены

Назначение параметров
Иногда бывает удобно создать константу, чтобы переиспользовать её в нескольких местах внутри графа. Параметры можно создать в графе либо указать ссылку на файл с описанием параметров.
Создать параметры
Чтобы создать параметр, перейдите в редактор параметров из панели Outline: Parameters -> Edit parameters.
Создание параметров

Созданный параметр можно указать используя синтаксис ${parametr_name}.
Использование параметра

Добавить ссылку на файл параметров
Чтобы добавить в граф ссылку на файл с описанием параметров, откройте редактор ссылок параметров из панели Outline: Parameters -> Link parameters. Вставьте путь к файлу параметров в поле fileURL.
Подключение файла параметров

Установка соединения с базой данных
Для корректной работы некоторых узлов нужно создать подключение к базе данных. Возможно описать соединение в графе либо привязать ссылку на отдельный файл с описанием соединения.
Создать подключение
На панели Outline щелкните правой кнопкой мыши по Connections -> New connection, чтобы создать новое внутреннее соединение с базой.
Для создания соединения выберите один из доступных драйверов и заполните атрибут URL по приведённому шаблону. Для подключения через ODBC используйте строку подключения, начинающуюся с odbc:..., добавив имя драйвера и остальные стандартные настройки подключения к выбранной базе.
Создание соединения

Добавить ссылку на файл подключения
На панели Outline щелкните правой кнопкой мыши по Connections -> Link connection, чтобы подключить файл, содержащий конфигурацию соединения с нужной базой данных. Заполните атрибут dbConfig, указав путь к файлу с параметрами соединения.
Подключение файла соединения

Добавление переменной
В переменной можно хранить данные в рамках запуска графа и передавать данные между всеми компонентами этого графа.
Чтобы создать запись переменной, нужно открыть редактор переменной на панели Outline: Dictionary -> Edit dictionary.
Создание переменной

В редакторе нужно внести имя записи переменной и выбрать его тип. Можно задать значение по-умолчанию.
Редактор переменной

Добавление справочника
Чтобы добавить справочник, воспользуйтесь редактором справочников. Чтобы открыть редактор, в контекстном меню группы Lookup Table на панели Outline выберите Edit lookup table. Для создания справочника обязательно заполнить поля Name, Key, Metadata. Если заполнить поле File, будет создан файл, в который данные таблицы будут сохранены. Иначе таблица будет существовать в памяти только на время работы графа.
Меню справочников

Редактор справочников

Редактор ссылок на справочники

Выполнение графов
Когда граф готов, его можно запустить различными способами:
- выбрать Run -> Run graph в главном меню;
- использовать сочетание клавиш Ctrl+R;
Успешное выполнение графа
После запуска графа процесс его выполнения можно увидеть на вкладке Log:
Вкладка Log с журналом выполнения графа

Во время работы графа на каждом ребре отображается количество прошедших по нему записей. Статистику по каждому ребру можно увидеть в виде чисел над ребром: слева число вошедших в ребро записей, справа процент записей от этого количества, которое успешно передано в следующий узел. Если открыть инспектор ребра, будут видны данные, прошедшие по нему:
Инспектор ребра

Обработка и вывод ошибок
Если при проверке графа или в процессе выполнения графа происходит сбой, ошибки будут выведены в журнал на вкладку Log.
Если ошибка возникла при работе конкретного узла, на нём отобразится восклицательный знак. Наведя курсор на значок можно увидеть всплывающее окно с указанием ошибки, произошедшей в этом узле.
Вывод ошибок на вкладку Log

Если ошибка обнаружена до начала выполнения, на этапе проверки файла - ошибка будет выведена в журнал, но не отобразится в Рабочей области.
Вывод ошибок на вкладку Log

Вывод ошибок на вкладку Log
Если ошибка связана с работой дизайнера - она будет выведена на вкладку Console, например при попытке запустить еще не сохраненный граф.

Статусы выполнения графа
Исполняемый граф может находиться в одном из следующих состояний:
| Статус | Символ | Описание |
|---|---|---|
| В процессе/In Progress |
| Процесс выполняется. |
| Выполнено/Success |
| Работа завершилась без сбоев. |
| Не выполнено/Failure |
| Произошел сбой во время обработки данных. |
| Отменено/Aborted |
| Обработка отменена. |




Каждый узел так же может иметь статус. Узлы могут получать все те же статусы, что и граф, а также находиться в ожидании (status: Waiting), когда граф еще не запущен либо упал раньше, чем выполнение дошло до данного узла.
Панель администрирования
Панель администрирования Onebridge - это web-приложение для отслеживания производительности сервера, управления пользователями и ролями, запуска и наблюдения за выполнением графов, для создания расписаний запусков и настройки обработчиков событий.
Каждая страница приложения поделена на три панели:
- панель меню;
- рабочая панель;
- панель дополнительной информации.
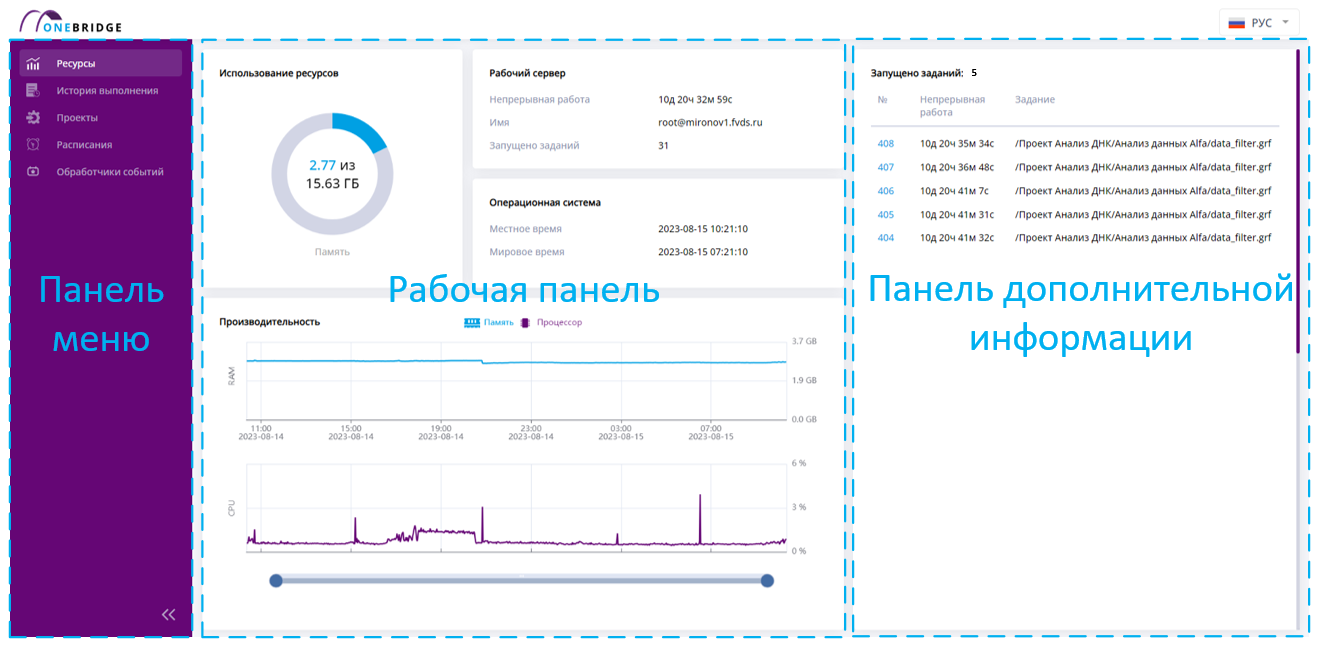
В меню доступны для перехода несколько функциональных разделов:
- На странице ресурсов отображается информация о задействованных ресурсах сервера и его производительности. Информация сгруппирована на нескольких панелях. Периодичность обновления данных можно настроить.
- На странице истории выполнения отображается история выполнения графов в виде таблицы, каждая строка которой содержит информацию по отдельному графу. Данные в таблице можно фильтровать. Доступен просмотр подробных данных по каждому графу.
- В дереве проектов доступен просмотр информации о графах и их запуск на выполнение.
- С помощью расписаний можно планировать запуск графов.
- Обработчики событий реагируют на произошедшие изменения и запускают выполнение назначенных задач.
- На странице Пользователи доступно администрирование пользователей.
- На странице Роли осуществляется управление ролями.
В следующих главах описан интерфейс и функционал этих разделов.
Просмотр документации
Ссылка на документацию доступна с любой страницы веб-приложения по клику на значок Документация Onebridge в правом верхнем углу экрана приложения.
Переход к документации

Переход к документации

Смена языка
По умолчанию язык интерфейса – русский. Язык можно сменить с помощью переключателя в правом верхнем углу экрана на любой странице приложения. Выберите нужный язык из выпадающего списка.
Смена языка интерфейса
Скрытие панелей
Чтобы скрыть панель меню для улучшения обзора, нажмите кнопку в виде двойной стрелки внизу данной панели. Чтобы раскрыть меню, еще раз нажмите на кнопку в виде стрелки.
Кнопка сворачивания панели меню
Панель меню в свернутом виде
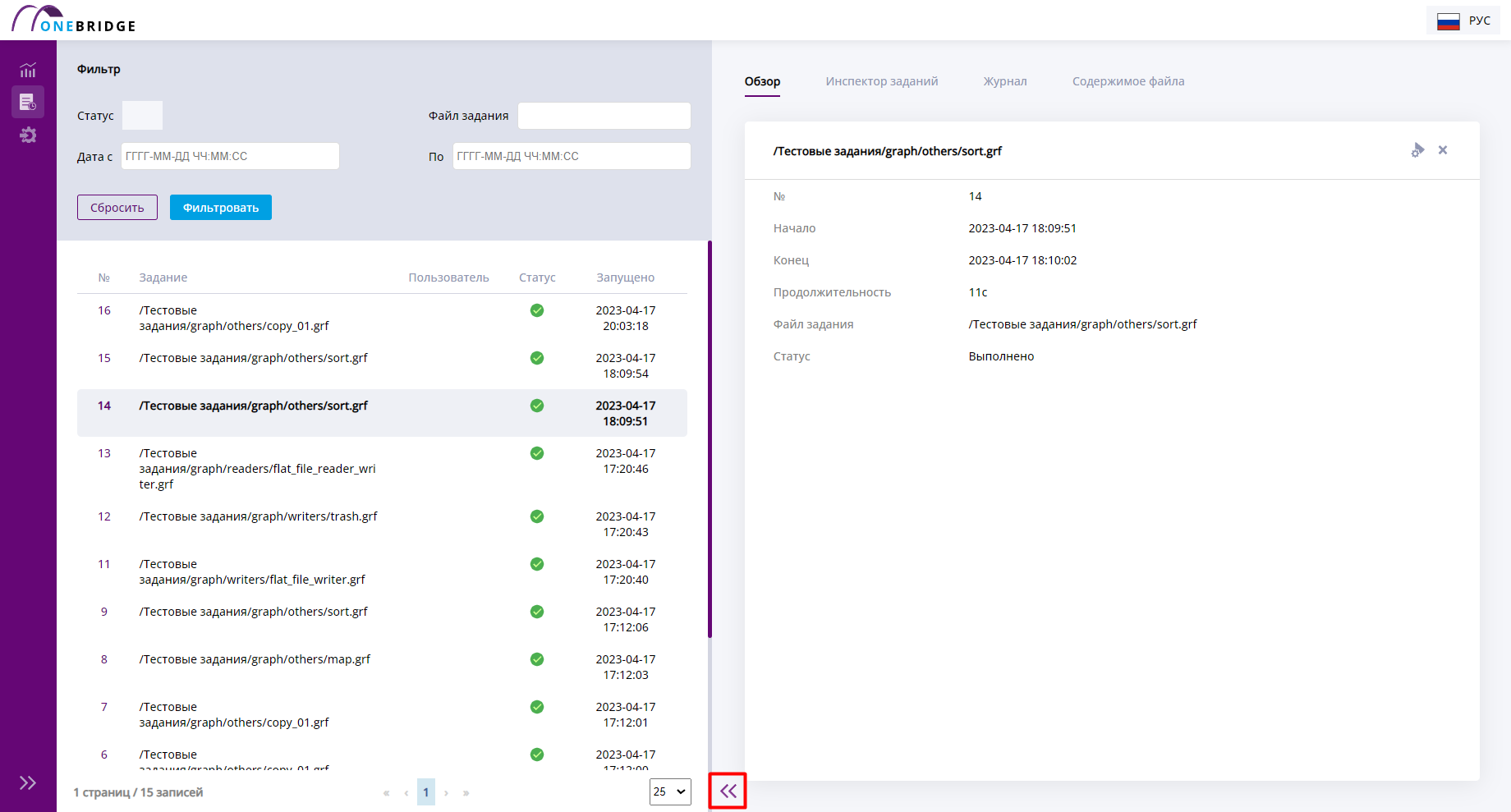
На странице истории можно раздвинуть вкладку с инспектором, чтобы просмотреть особенно большой граф, с помощью кнопки в виде двойной стрелки.
Кнопка для управления размером панели дополнительной информации
Полностью развернутая панель дополнительной информации
Чтобы уменьшить размер панели, нажмите на кнопку повторно.
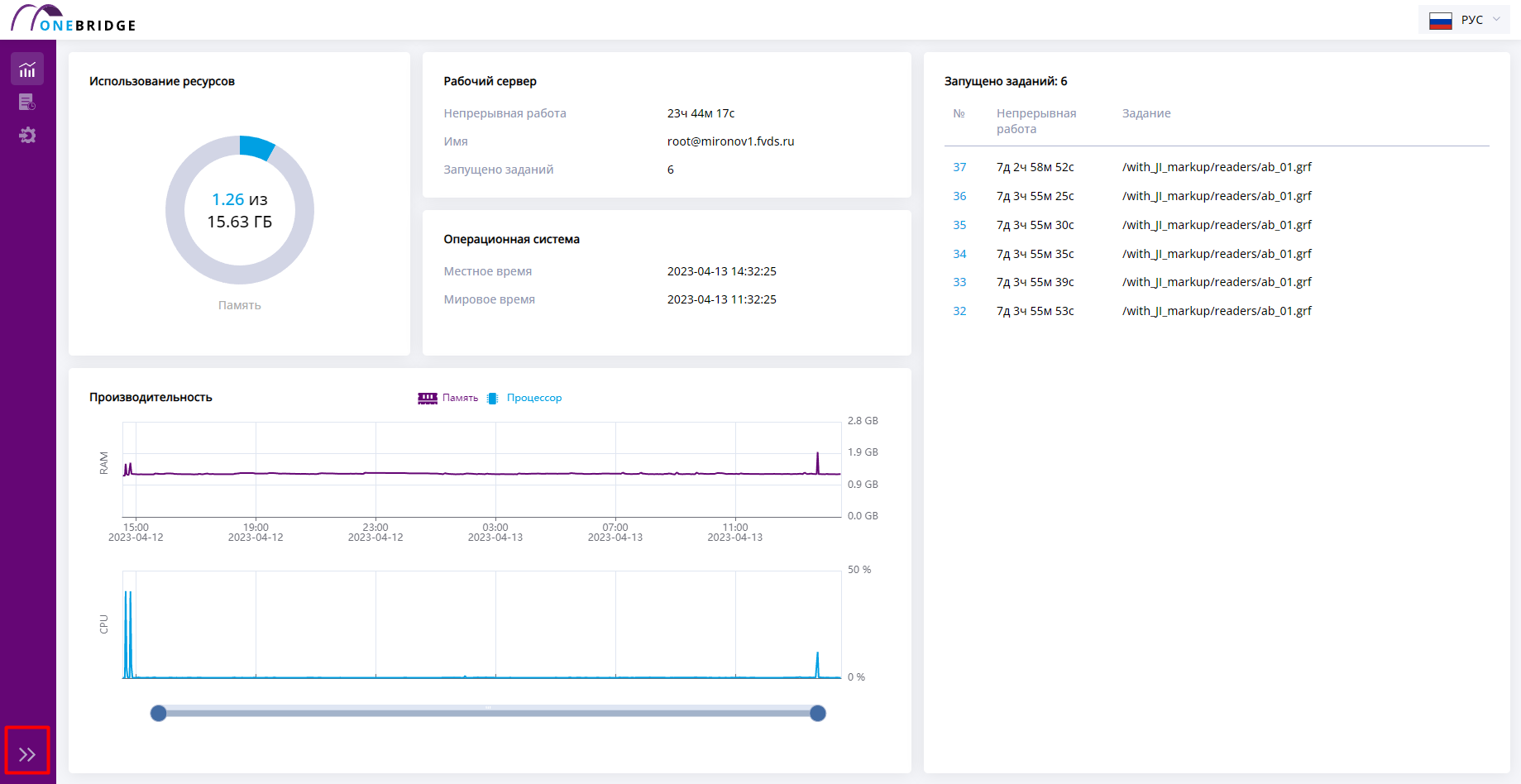
Ресурсы
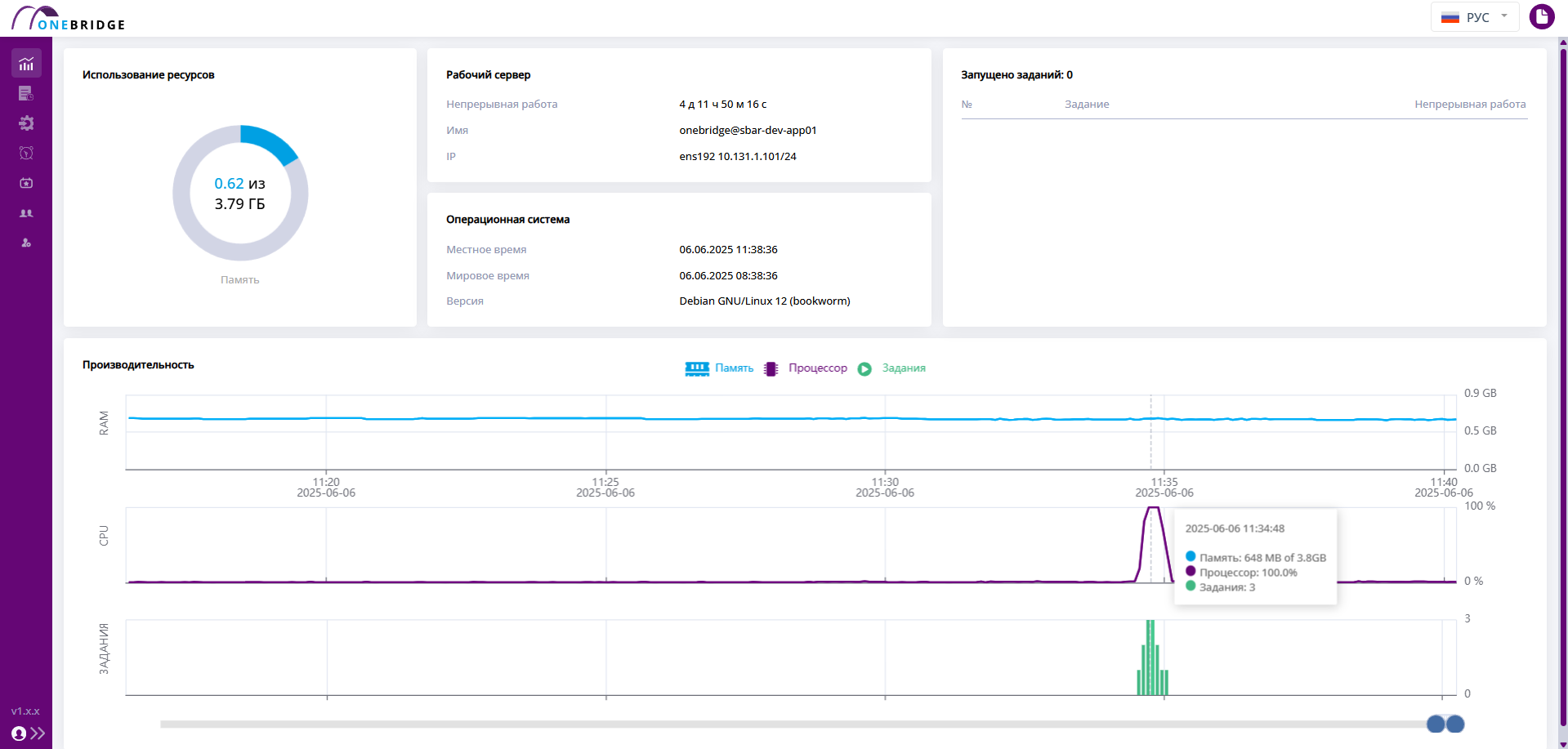
Страница ресурсов отображает график зависимости используемых ресурсов от времени, информацию о затраченной памяти сервера, показывает количество запущенных в данный момент графов.
Рабочая панель поделена на несколько областей:
- В блоке «Использование ресурсов» на круговой диаграмме отражается процентное соотношение занятой оперативной памяти сервера ко всей доступной.
- «Рабочий сервер». Раздел содержит информацию о параметрах рабочего сервера.
- «Операционная система». Содержит основную информацию об операционной системе.
- «Производительность». В этом разделе отображаются два линейных графика: «Загрузка памяти» - RAM и «Загрузка ЦП» - CPU, а также столбчатая диаграмма "Графы", демонстрирующая зависимость количества запущенных графов от времени.
- В блоке "Запущено графов" отображаются работающие в данный момент графы. Обновление происходит каждые 5 секунд. По клику на номер графа можно перейти в историю выполнения, чтобы посмотреть подробную информацию про этот запуск.
На странице ресурсов отсутствует панель дополнительной информации.
Интерфейс страницы «Ресурсы»
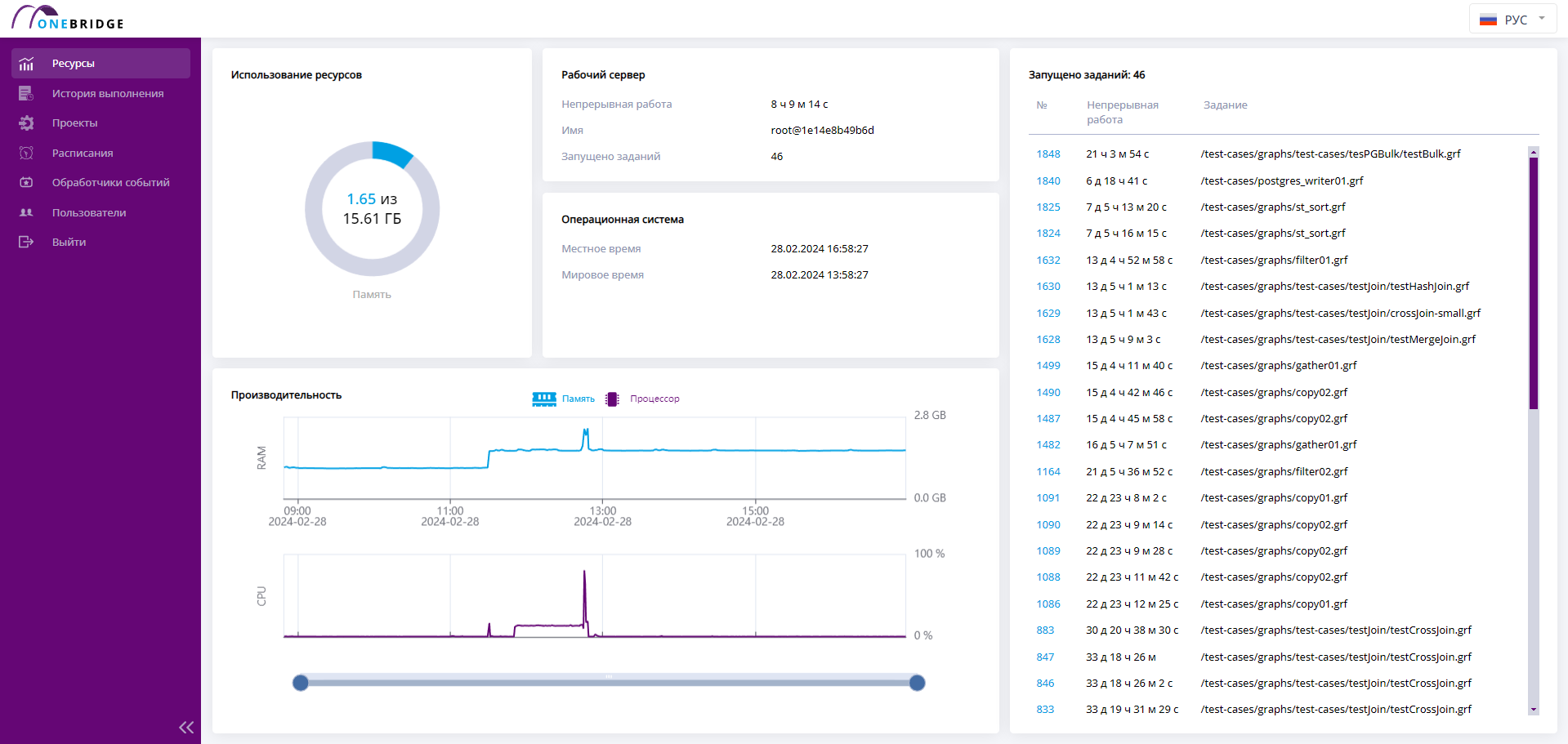
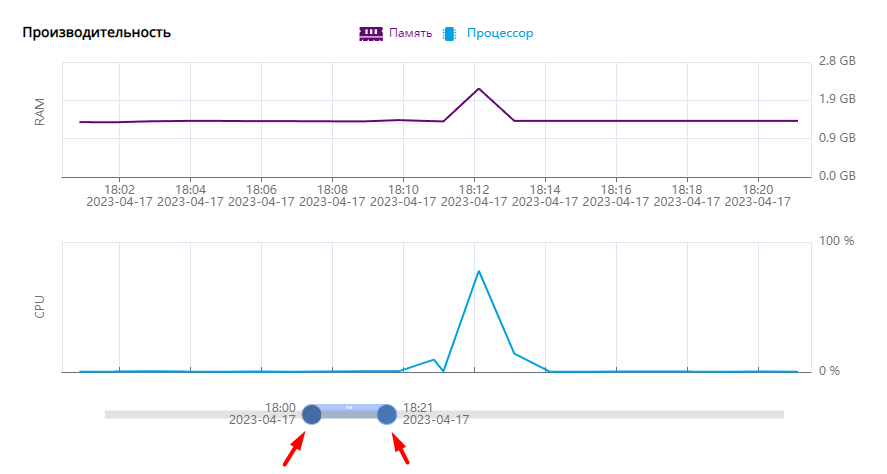
В блоке «Производительность» видимую область графиков можно менять, с помощью колеса прокрутки мыши или двигая мышкой ползунок с указанием времени под графиком. Ползунок позволяет установить начало и конец временного интервала по отдельности. Выбор временного отрезка проиллюстрирован на следующем рисунке.
Уменьшение временного отрезка на графиках с помощью ползунка
Изменение временного отрезка пригодится, чтобы наблюдать изменения производительности на меньшем промежутке времени, так как по умолчанию выводится информация о последних сутках использования.
Наведя указатель мыши на график, вы увидите всплывающую подсказку с описанием ресурсов в выбранный момент времени.
Всплывающая подсказка на графике производительности
Для лучшей читаемости каждый из графиков можно включить или отключить, щелкнув его метку над областью графиков.
Метки, управляющие видимостью графиков

История выполнения
История выполнения показывает список всех запущенных на сервере графов в порядке их запуска. Вы можете использовать историю выполнения, чтобы узнать, почему граф завершился ошибкой и просмотреть параметры, которые использовались для конкретного запуска и другую информацию о запуске.
Компоненты страницы истории выполнения:
Интерфейс истории выполнения
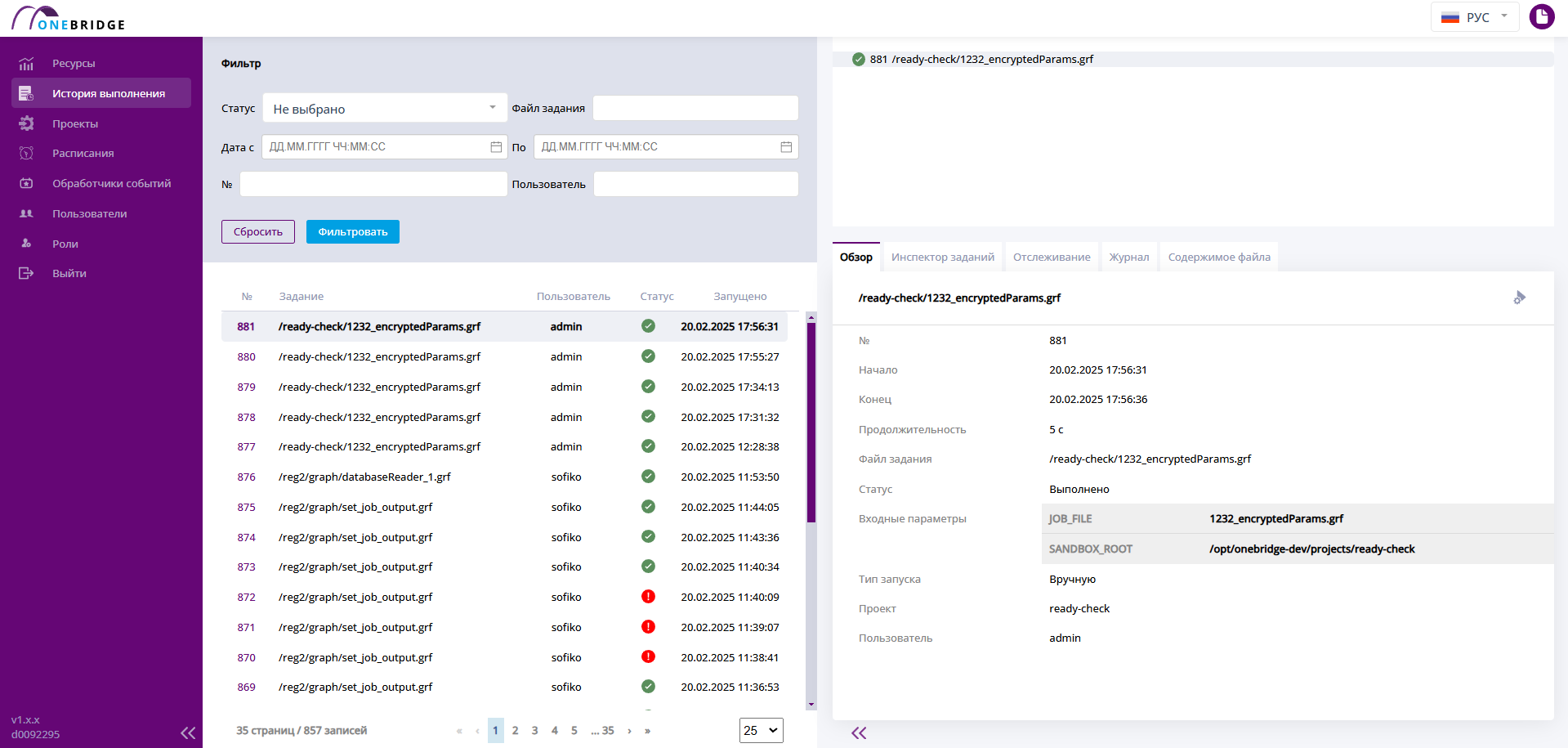
В рабочую область выводится таблица с основной информацией о произведенных запусках графов: номер запуска, название файла, имя запустившего пользователя, статус и время запуска графа. Процесс, запущенный последним, отображается в таблице выше всех.
Интерфейс страницы "История выполнения"
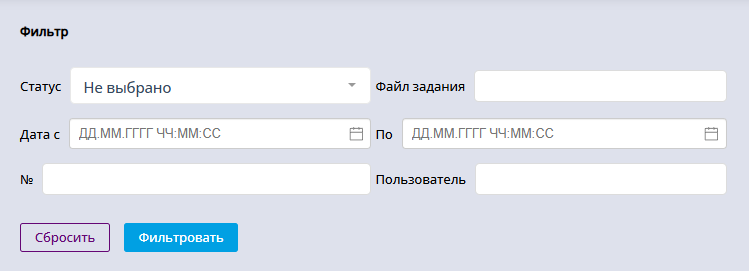
Чтобы отфильтровать таблицу по дате или названию файла графа, заполните поля фильтров и используйте кнопку "Фильтровать".
Поля для фильтрации таблицы с историей выполнения графов
Обзор
Чтобы просмотреть информацию о конкретном графе, нужно кликнуть соответствующую строку в таблице. Откроется панель дополнительной информации с открытой вкладкой "Обзор". Во вкладке будет отображаться информация о выбранном графе.
Если вы попали на вкладку истории выполнения после запуска графа, нажав на уведомление, то просмотр информации по конкретному графу будет доступен сразу.
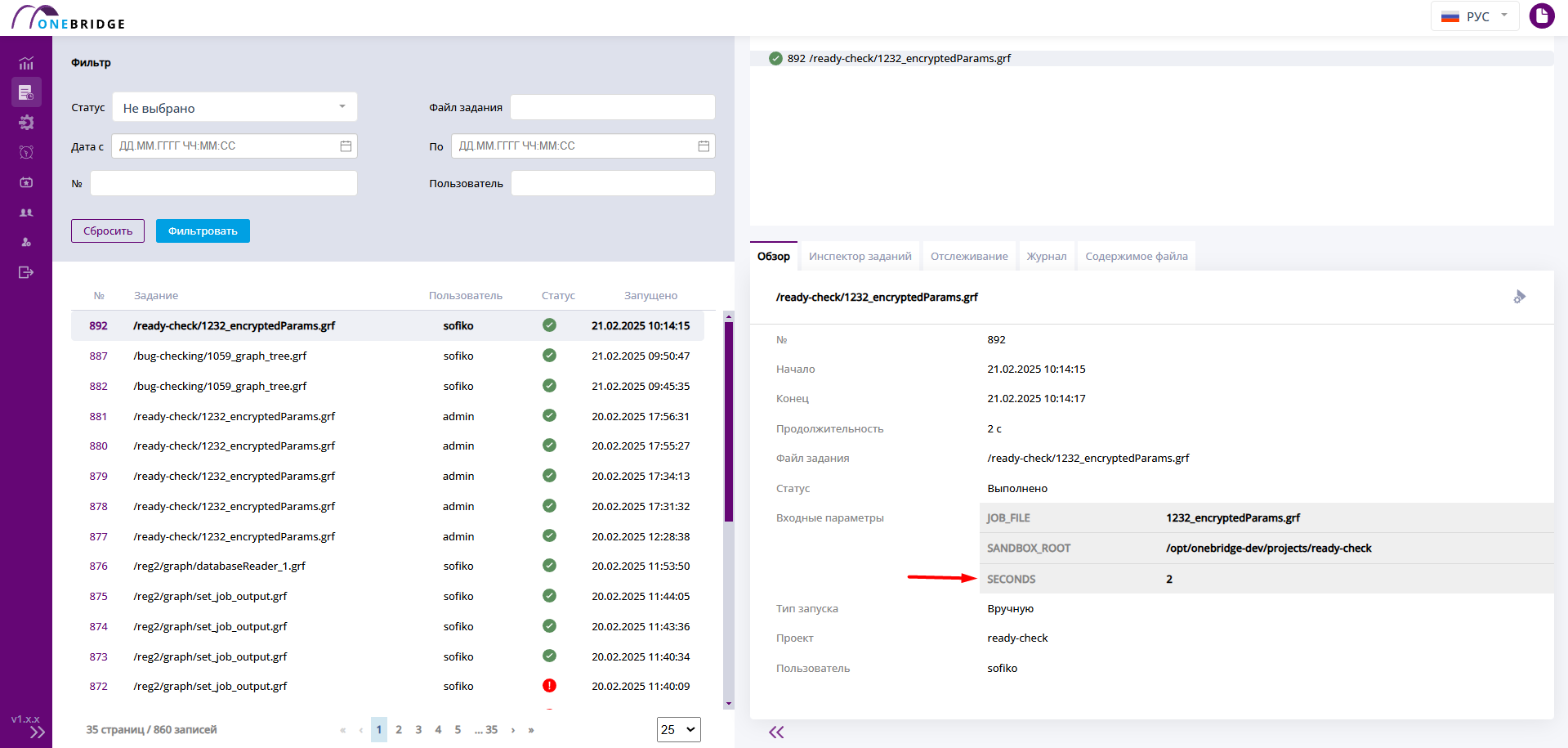
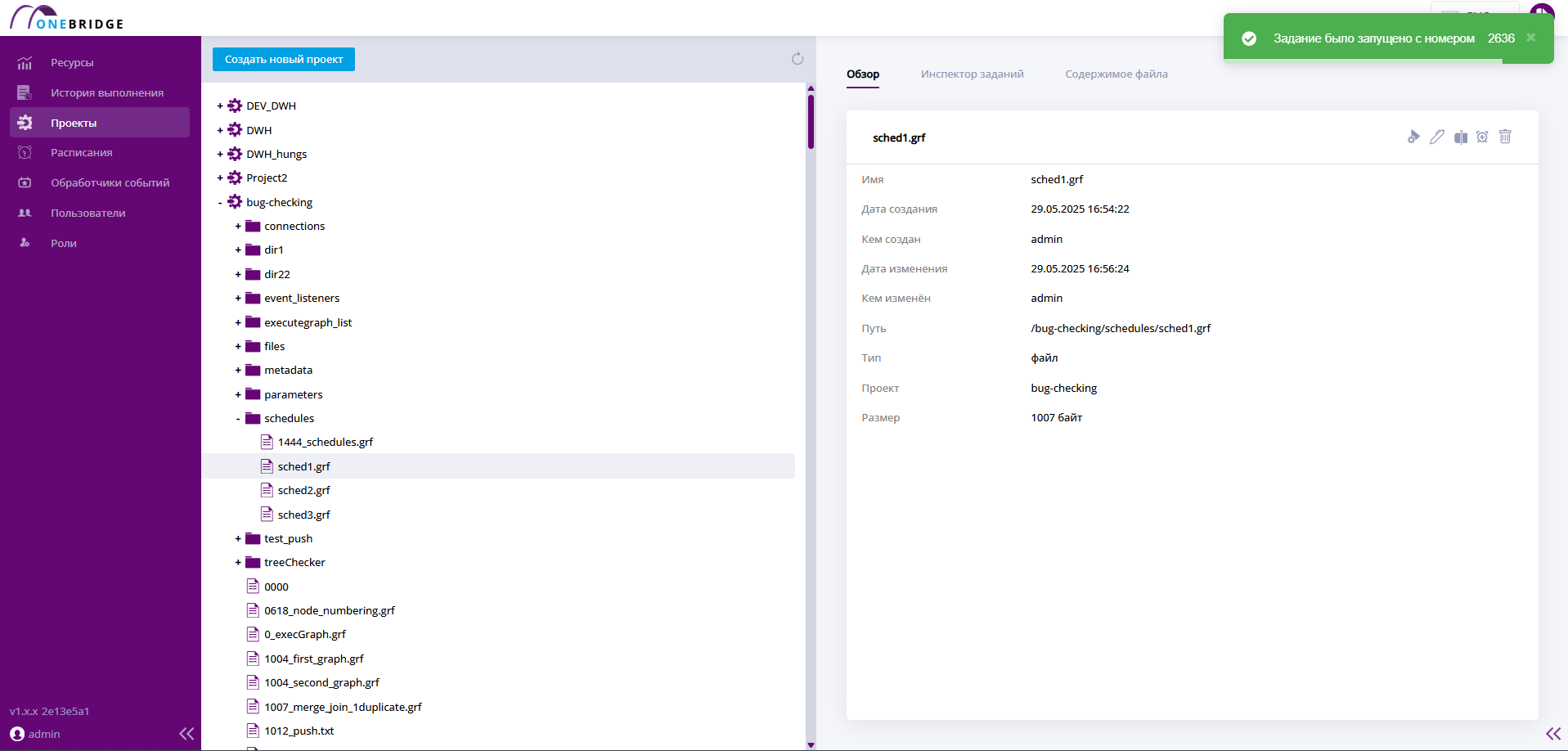
На вкладке "Обзор" отображается номер графа, данные о времени выполнения, относительный путь к файлу графа, статус его выполнения и параметры запуска.
Интерфейс вкладки "Обзор"
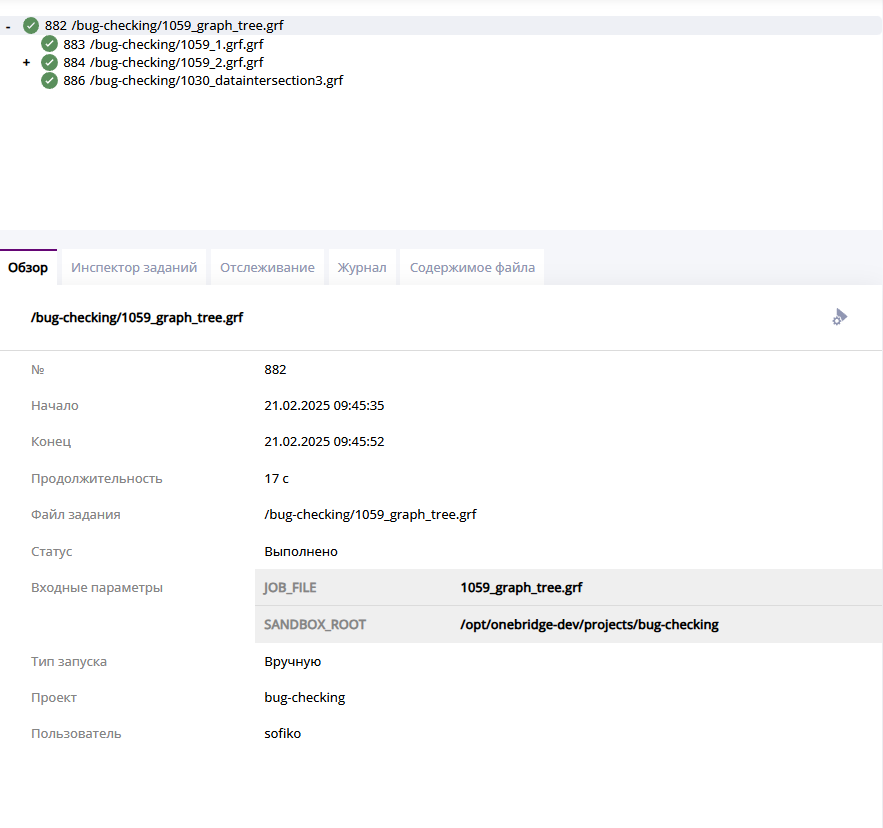
В таблице ниже описаны данные, отображаемые на вкладке "Обзор".
| Имя столбца | Описание |
|---|---|
| № | Идентификатор запуска графа, уникальный номер, идентифицирующий запуск графа. |
| Начало | Дата и время начала выполнения графа. |
| Конец | Дата и время окончания выполнения графа. |
| Продолжительность | Длительность выполнения графа. |
| Файл графа | Относительный путь до файла графа. |
| Статус | Статус выполнения графа. "Выполнено" - граф выполнен успешно, "В процессе" - граф в данный момент выполняется и "Не выполнено" - граф завершен с ошибкой. |
| Входные параметры | Наименования и значения входных параметров, которые были использованы при запуске графа. |
| Тип запуска | Отражает триггер, запустивший граф в работу: Вручную/ По событию/ По расписанию |
| Проект | Название проекта, в котором лежит файл графа запускаемого графа. |
| Пользователь | Имя пользователя, который запустил граф. |
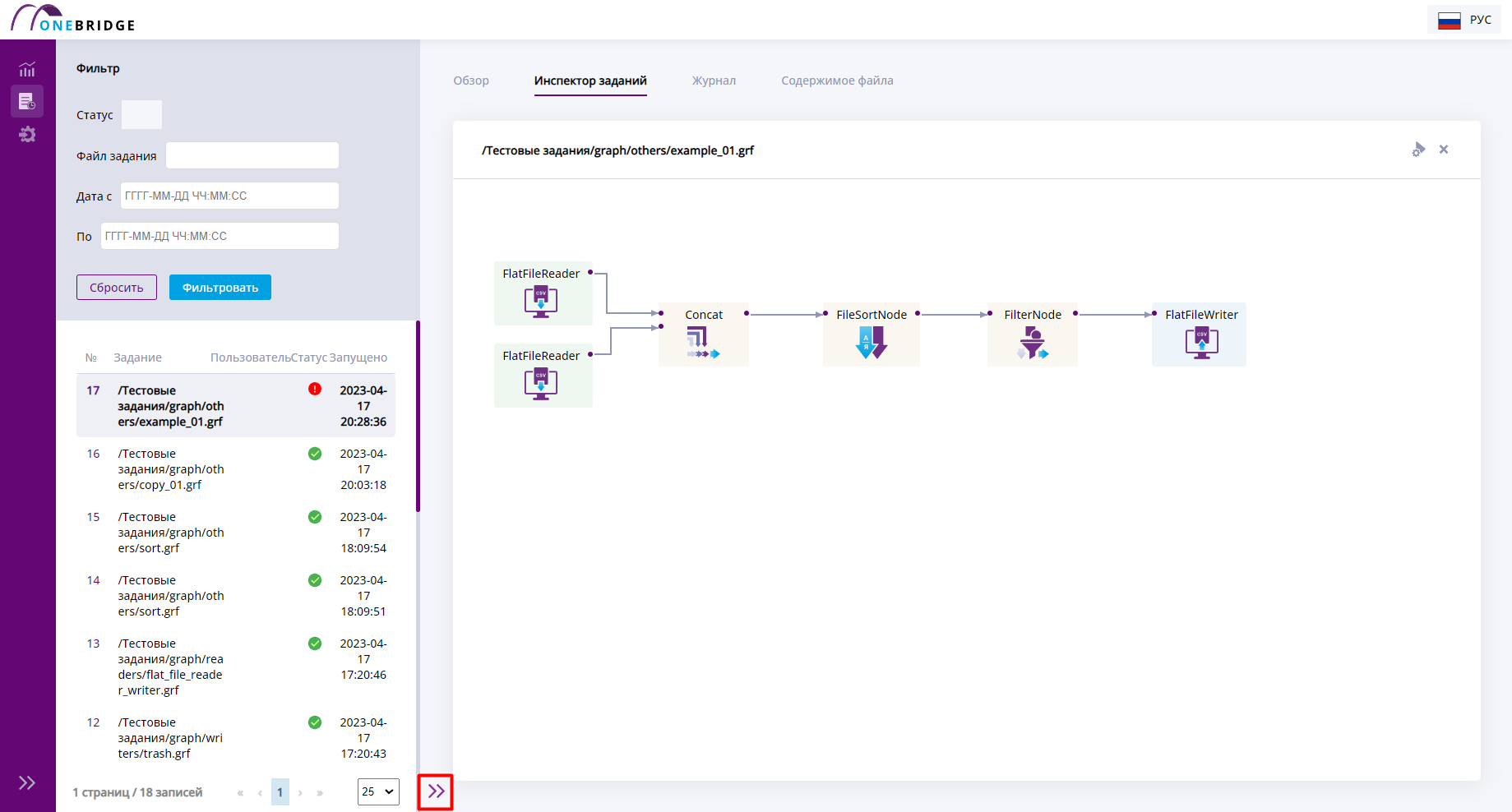
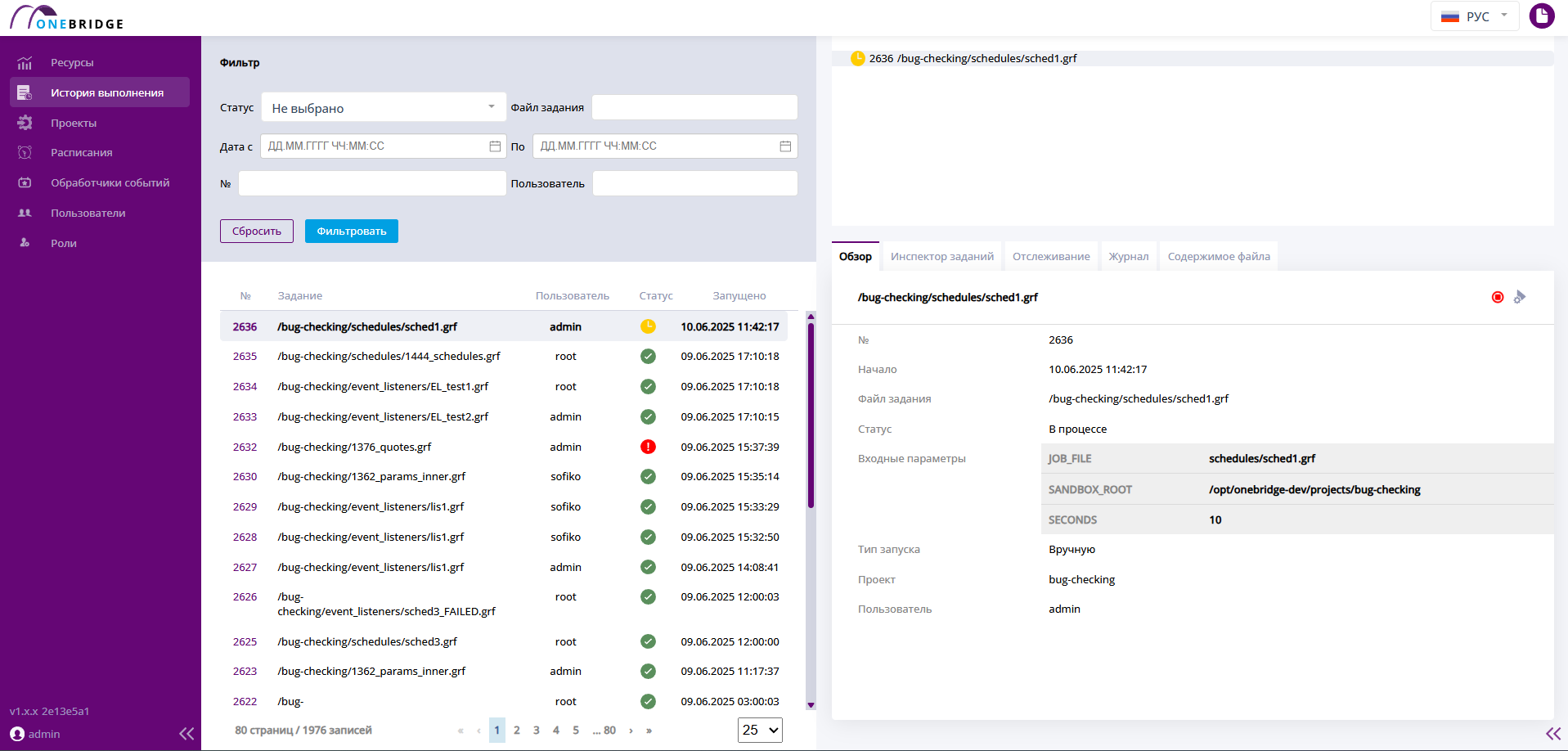
Инспектор
Графический инструмент "Инспектор", приведенный на рисунке ниже, позволяет пользователю исследовать процесс выполнения графа. Инспектор визуализирует поток данных в виде графа. На графе выводятся компоненты - это узлы алгоритма, они представлены в виде прямоугольников, соединенных линиями. Линии в графе называются рёбрами и отражают потоки данных между компонентами.
Граф может быть очень большим и не помещаться в инспекторе полностью. Чтобы увидеть все компоненты и их связи, нужно перетащить рисунок, зажав его левой кнопкой мыши, и потянув, сдвинув в сторону.
Вкладка "Инспектор". Визуальное представление графа, состоящего из нескольких узлов.
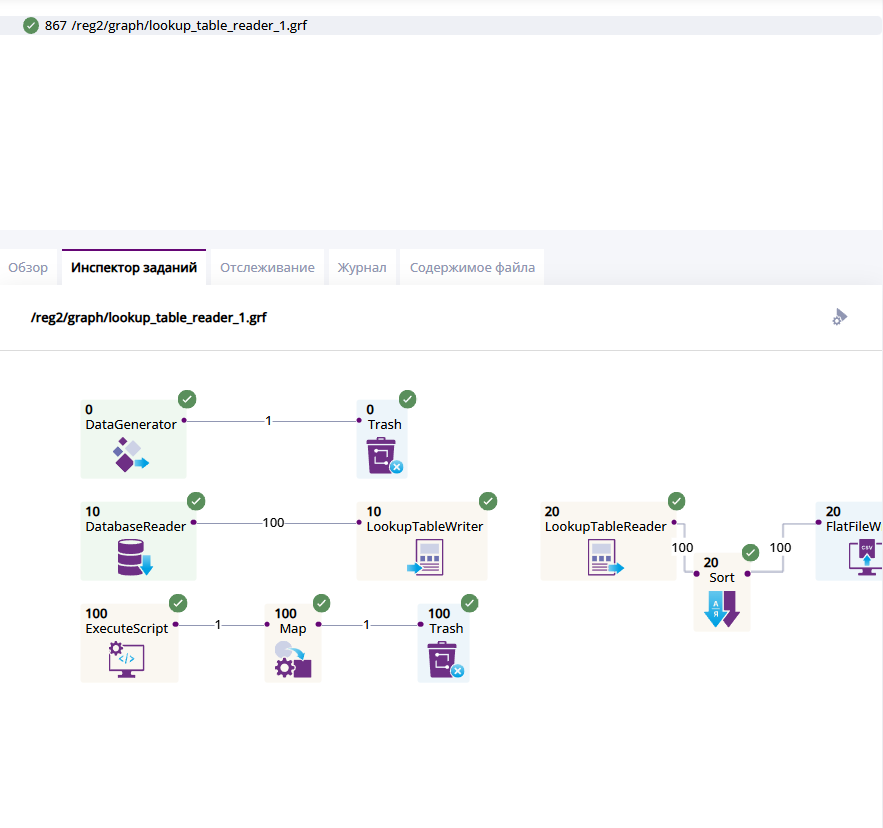
Отслеживание
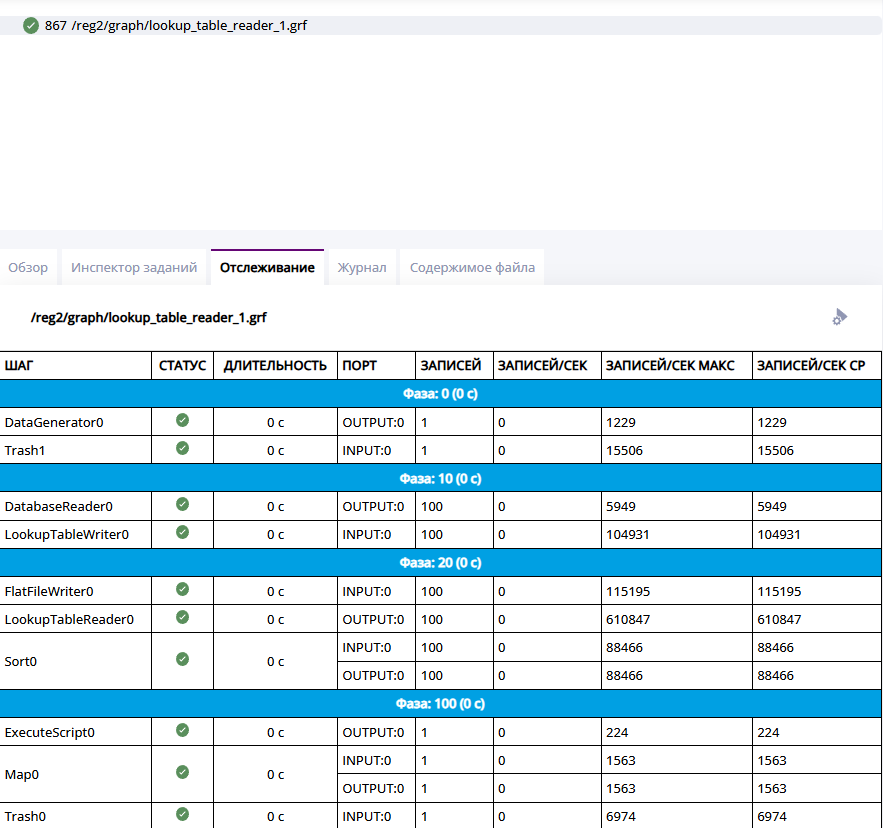
С помощью "Отслеживания" можно увидеть подробные данные по каждому узлу, используемому в графе. Статусы узлов, количество переданных записей, скорость передачи данных.
Вкладка "Отслеживание"
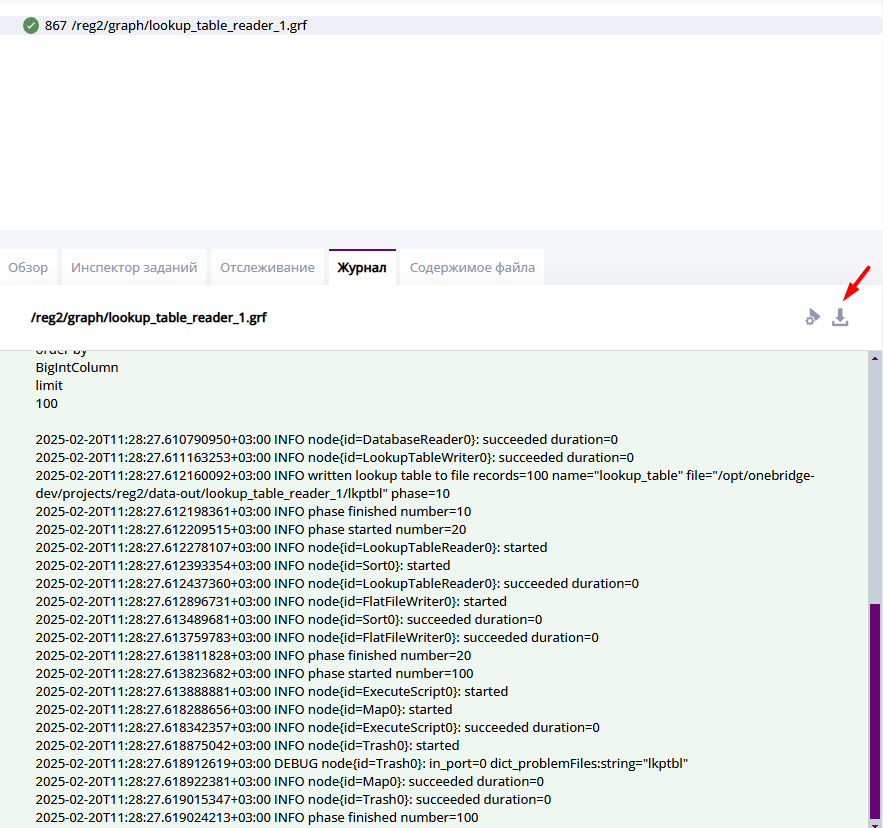
Журнал
На вкладку "Журнал" пишутся логи. Здесь можно будет увидеть ошибку, если она случится в процессе выполнения.
Каждый запуск графа имеет собственный файл журнала. Журнал можно скачать.
Вкладка "Журнал"
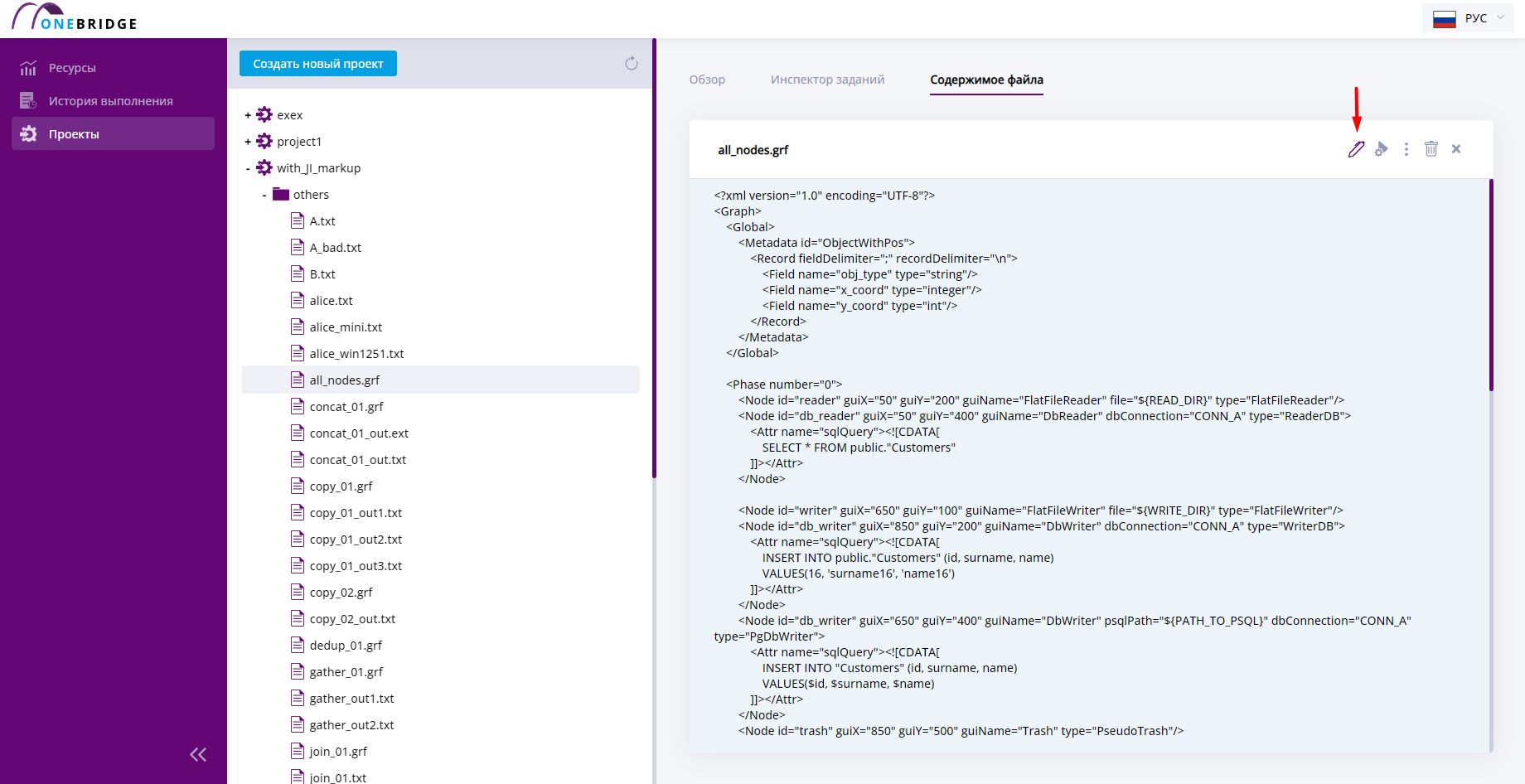
Содержимое файла
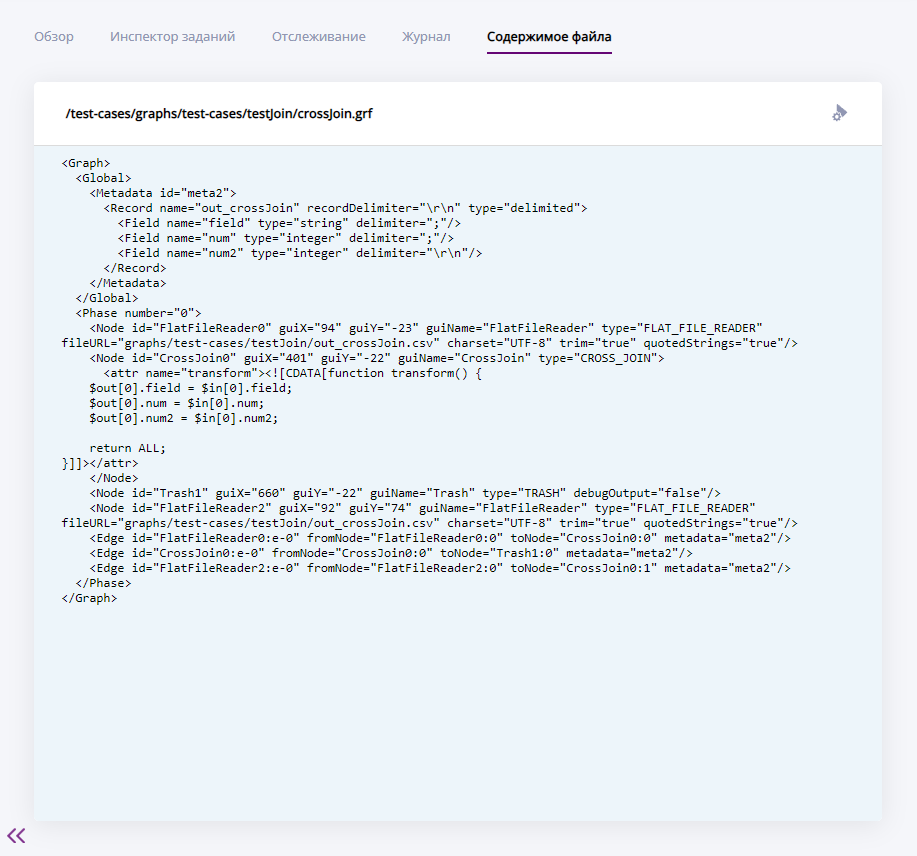
На вкладку "Содержимое файла" выводится контент файла, актуальный на момент запуска графа.
Вкладка "Содержимое файла"
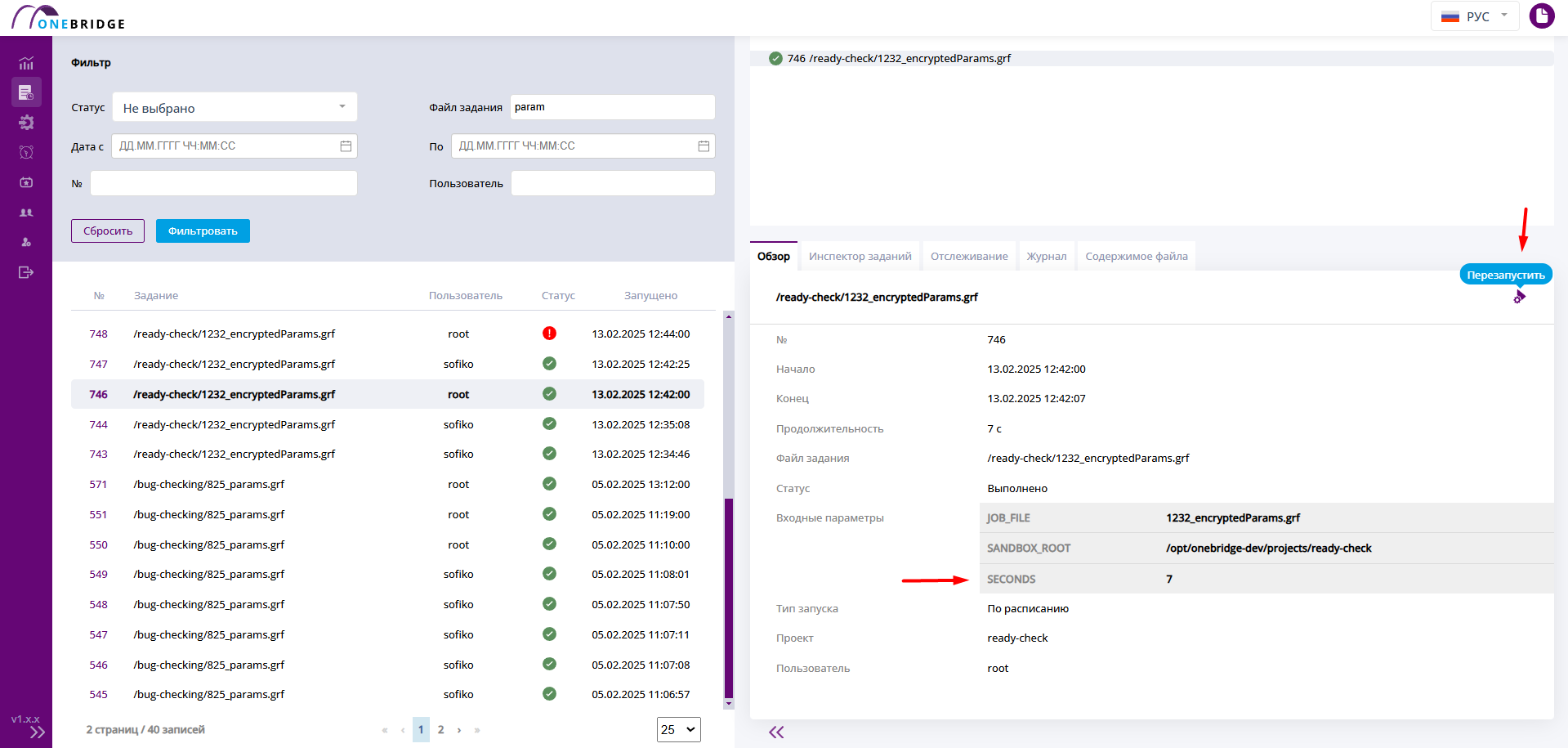
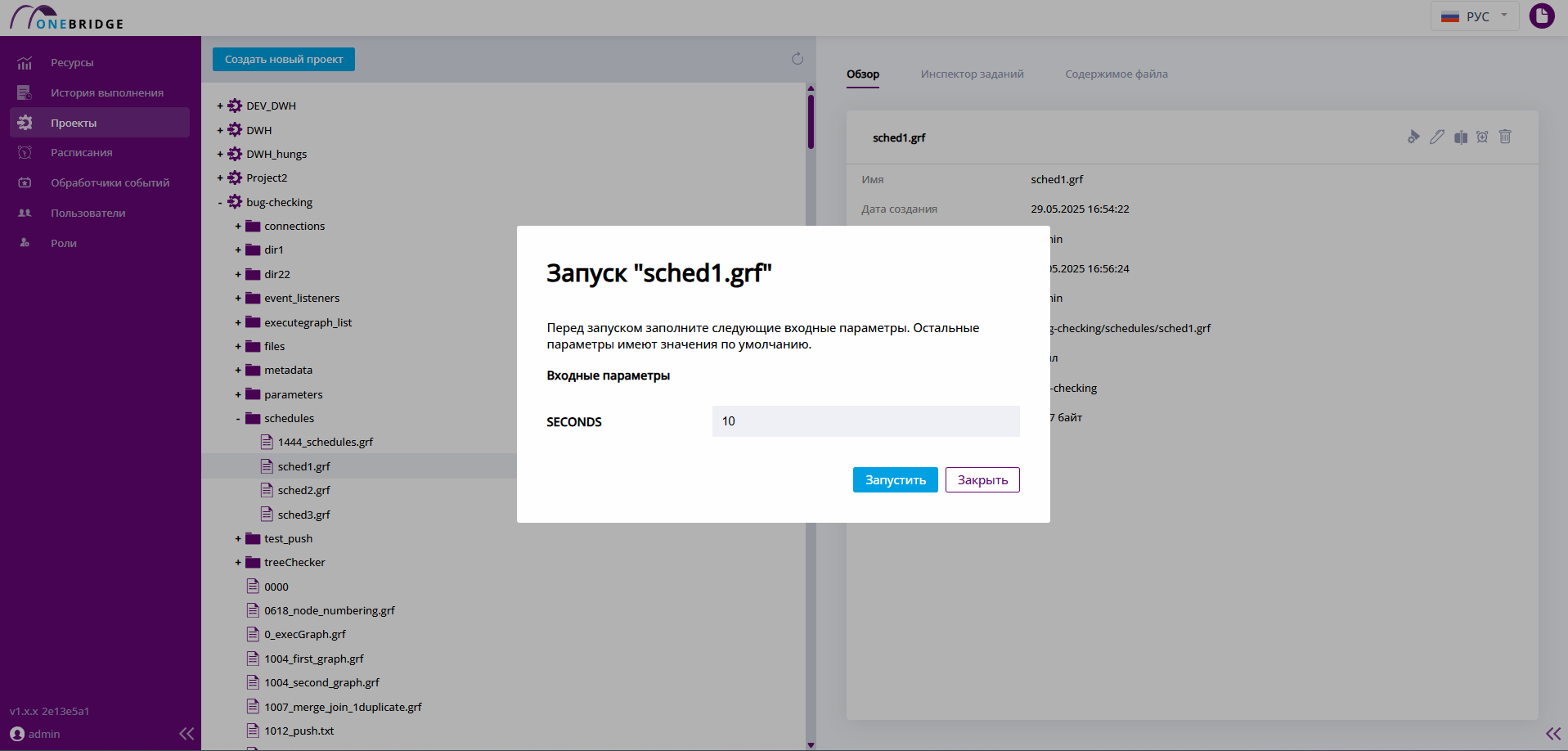
Перезапуск графа
Для удобства, с любой вкладки панели дополнительной информации можно запустить граф заново с помощью кнопки "Перезапустить".
Если в графе используются параметры, то при перезапуске будут по умолчанию использованы значения из запуска, из которого происходит перезапуск. Значения параметров, указанные в файле графа, учтены не будут.
В окне перезапуска можно ввести новые значения параметров, если это необходимо. При перезапуске будет использовано содержимое файла графа, актуальное на момент перезапуска.
Граф с параметрами из истории. Кнопка перезапуска
В окне перезапуска указано историческое значение параметра SECONDS.
Окно задания параметров перед перезапуском
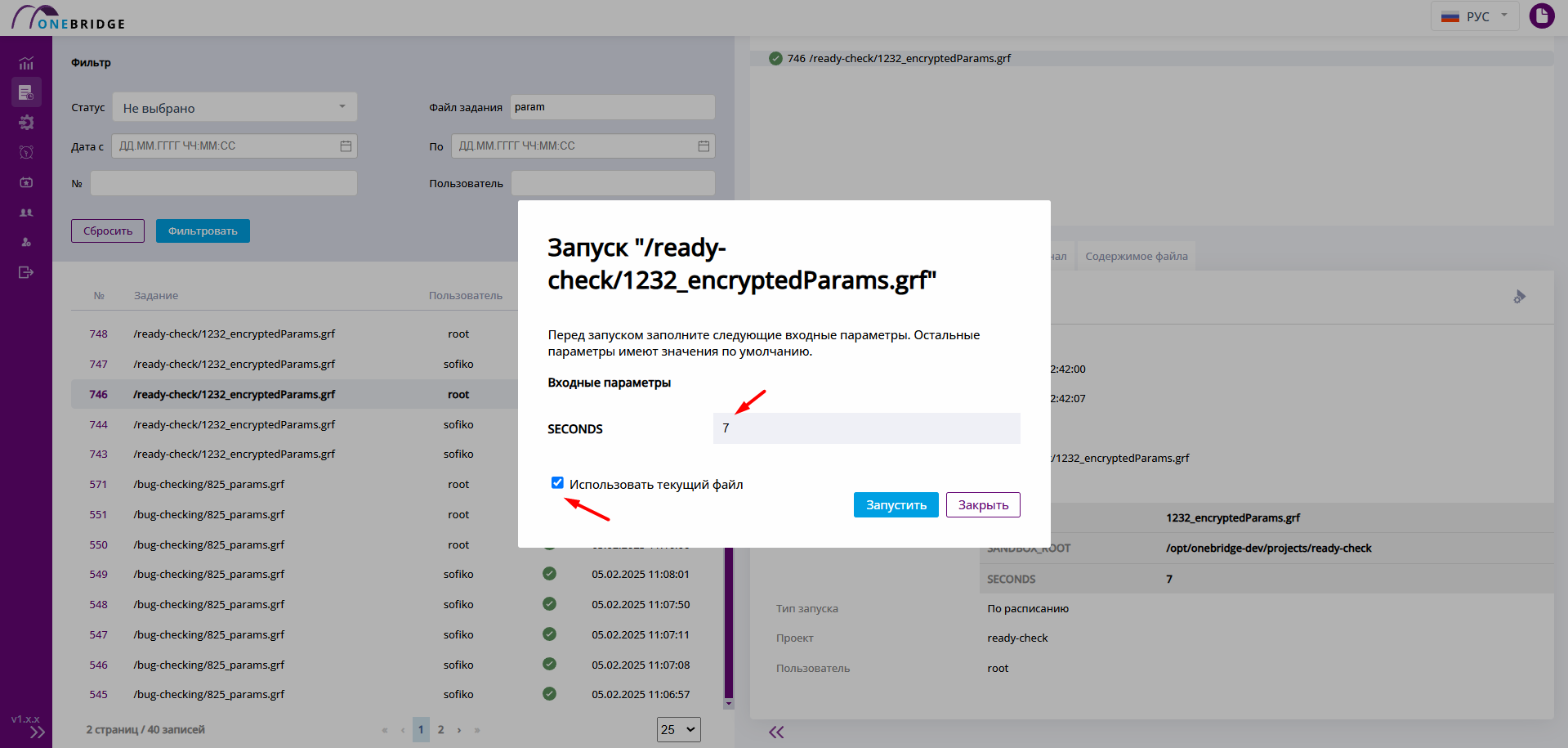
Значение параметра можно поменять
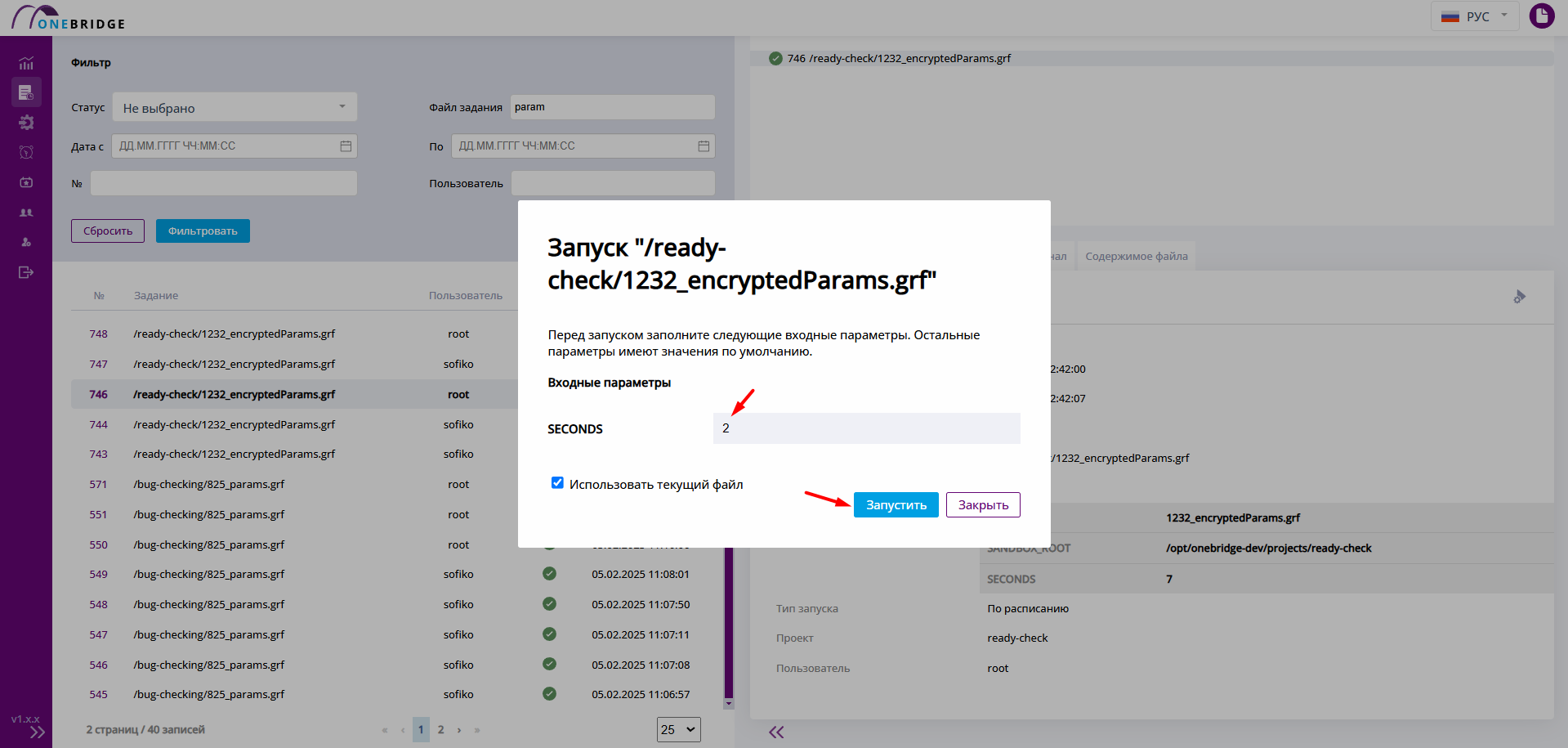
Перезапущенный граф использует содержимое файла, актуального на данный момент и параметры, введенные в окне перезапуска.
Результат перезапуска с новыми значениями параметров
Проекты
Страница проектов — это место, где отображаются все файлы, хранящиеся на сервере. На рабочей панели этой страницы находится дерево проектов, внутри проектов – папки и файлы. На следующем рисунке приведен внешний вид страницы проектов.
Интерфейс страницы "Проекты"
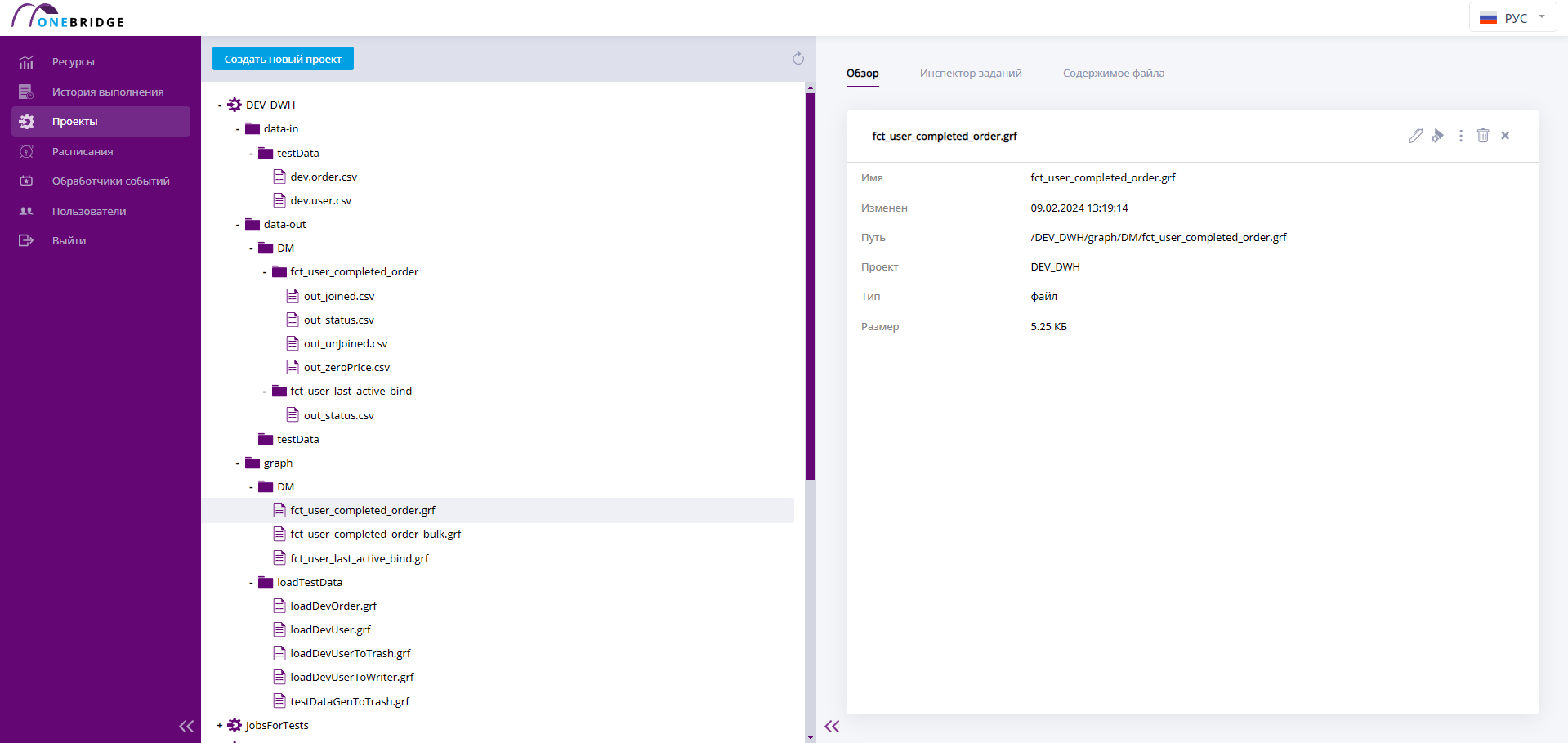
Чтобы открыть содержимое проекта или папки, нажмите на плюсик "+" слева от названия элемента в дереве. Чтобы свернуть содержимое проекта или папки, используйте минус "-".
Если нажать на название проекта, папки или файла, в правой части экрана появится панель дополнительной информации. На ней есть несколько вкладок для просмотра подробной информации об открытом элементе дерева и его содержимом:
- Для любого элемента дерева доступна вкладка "Обзор". На ней отображаются данные файла или выбранной директории. Запуск графов на выполнение производится на этой вкладке.
- Для файлов с расширением
.grfпоявляется вкладка "Инспектор". На ней можно увидеть процесс выполнения графа в графическом виде. - Содержимое файлов выводится во вкладку "Содержимое файла", если не превышает объём в 1Мб. При превышении лимита, файл можно просмотреть только через Дизайнер, скачав его вручную.
Далее описано создание проектов и управление их содержимым.
Создать проект
Чтобы создать новый проект, нажмите кнопку Создать новый проект в верхней части рабочей панели на странице "Проекты". Диалог создания проекта показан ниже.
Открытие диалога по созданию нового проекта
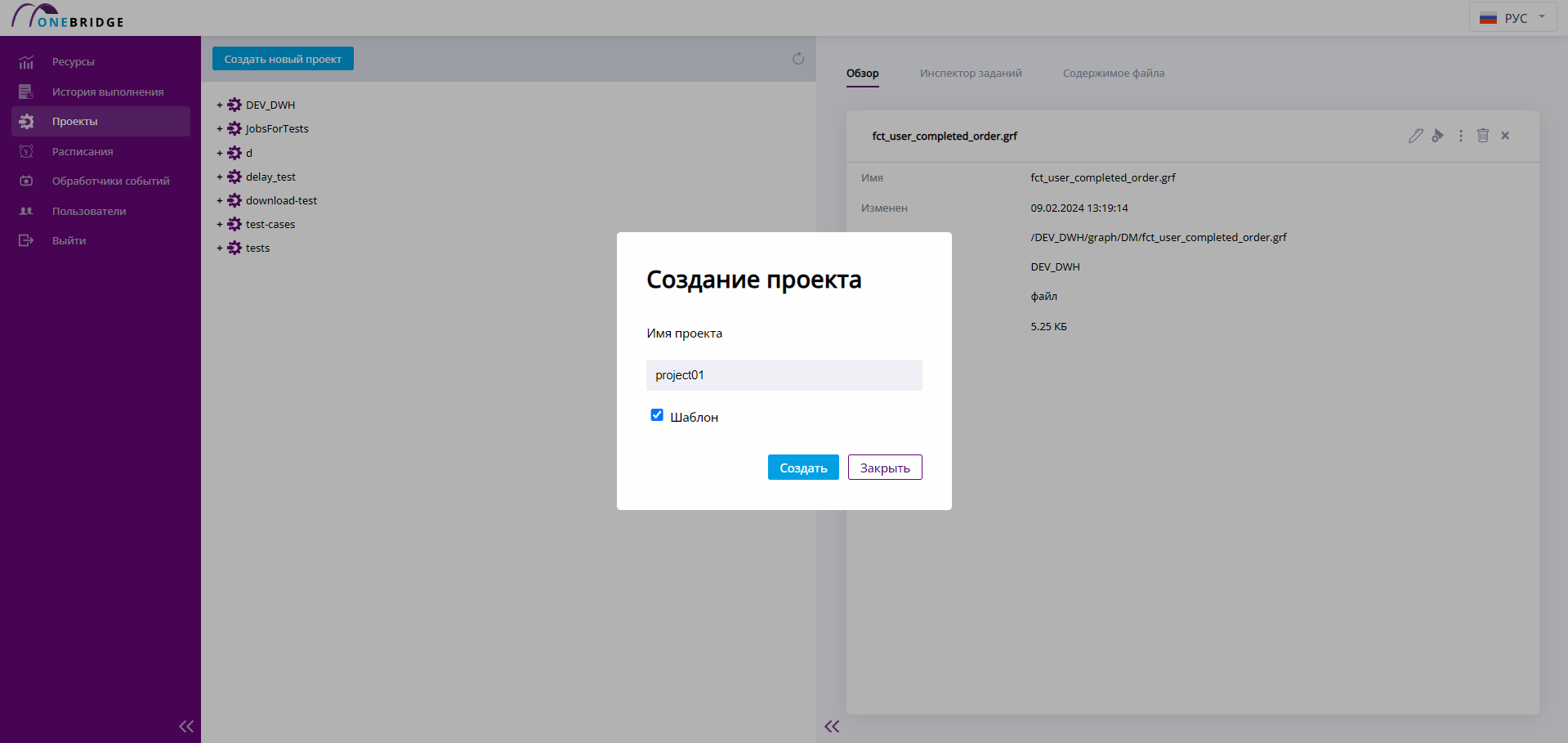
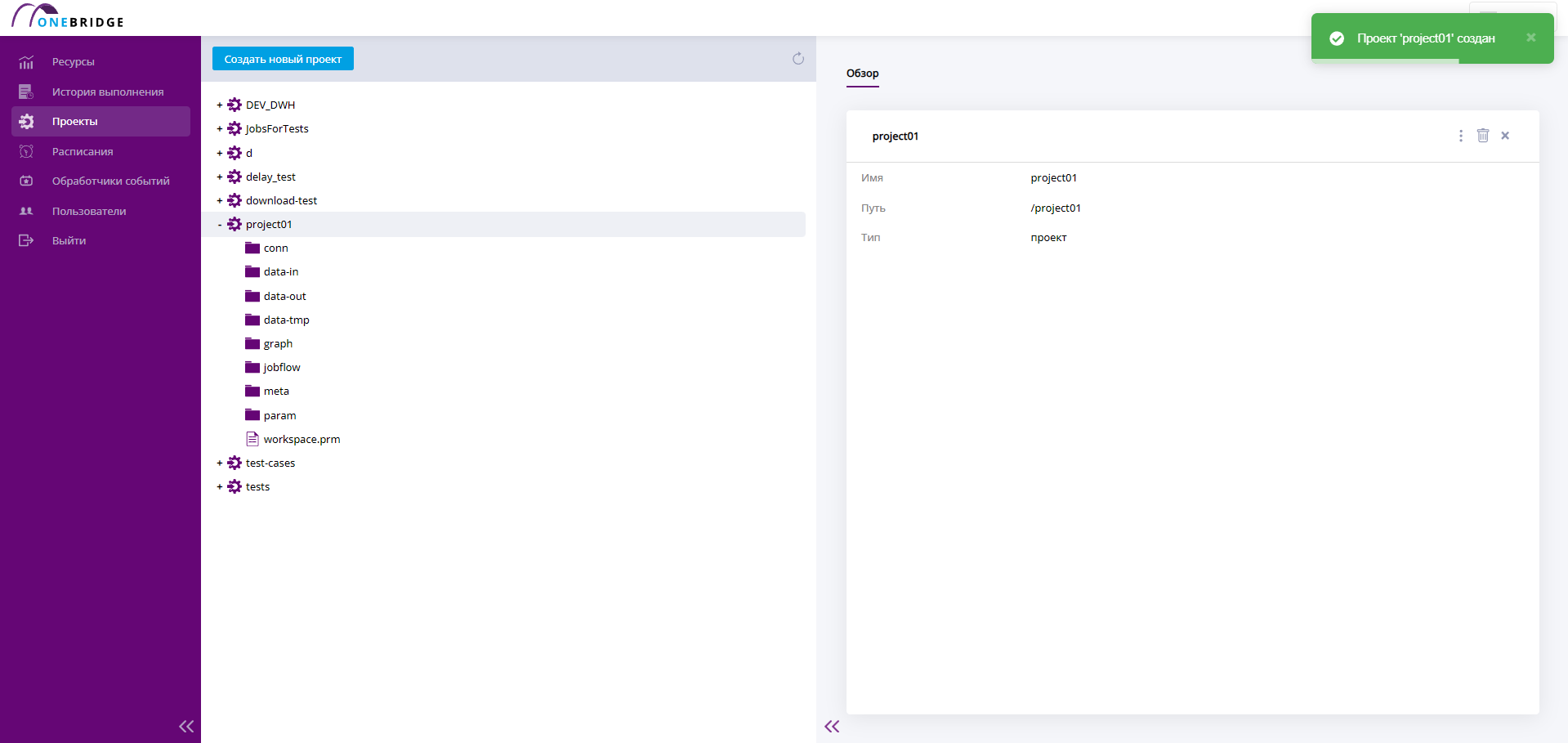
Откроется диалоговое окно. Задайте название в поле "Имя проекта" и используйте чекбокс "Шаблон", если хотите, чтобы в новом проекте сразу появились папки для удобства. Нажмите кнопку Создать, чтобы создать проект. Чтобы выйти из диалога без сохранения – нажмите Закрыть.
В случае создания проекта в верхнем правом углу будет выведено уведомление об этом. Название нового проекта появится в дереве проектов.
Пример шаблонного проекта приведён на рисунке ниже:
Новый проект создан
Создать папку
В существующих проектах можно создавать пользовательские папки для упорядочивания файлов внутри ваших проектов.
Для создания папки нажмите на название проекта, в котором нужно создать папку. На панели дополнительной информации отобразится вкладка "Обзор". Из списка действий с проектом выберите Создать папку.
Меню директории при создании папки
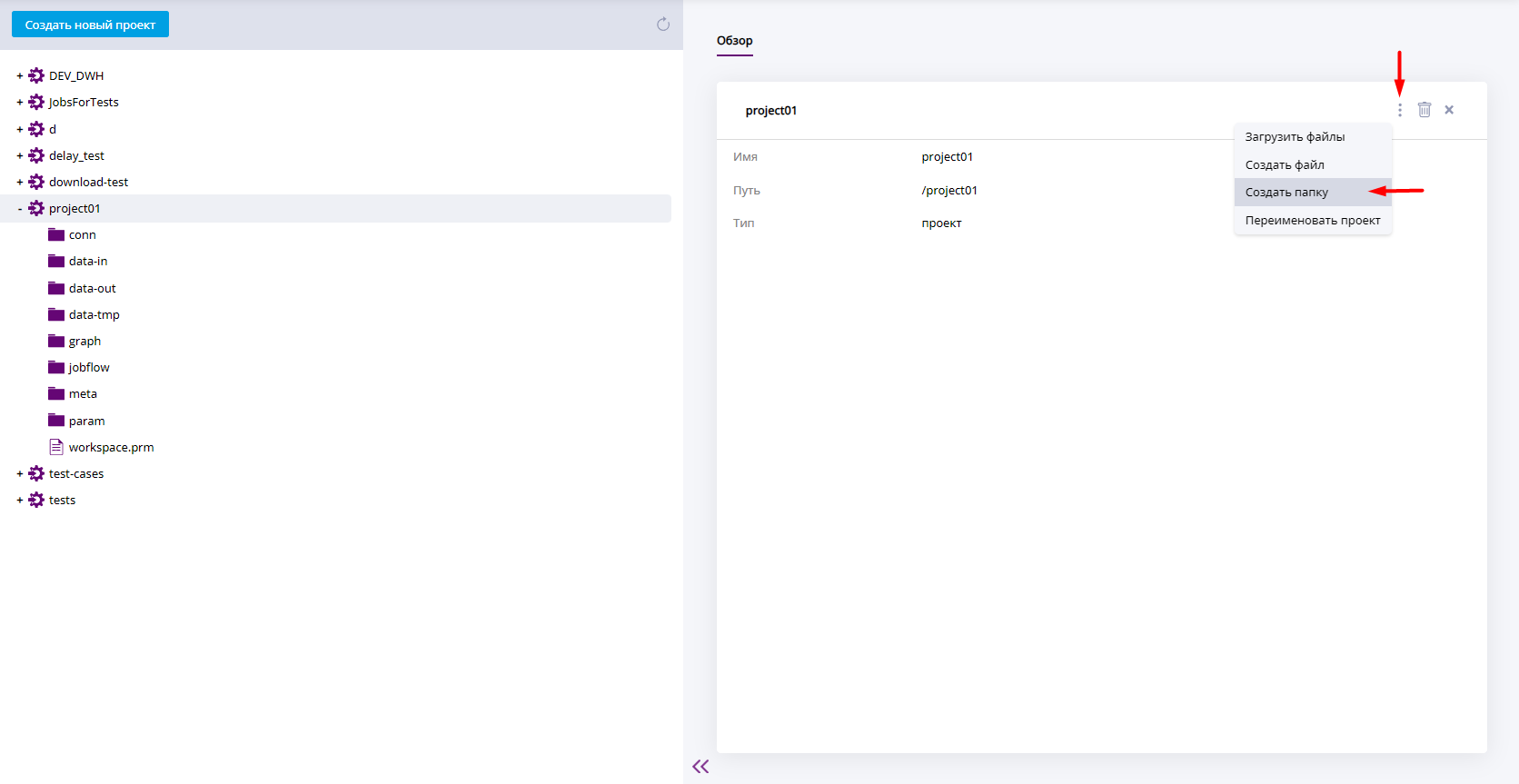
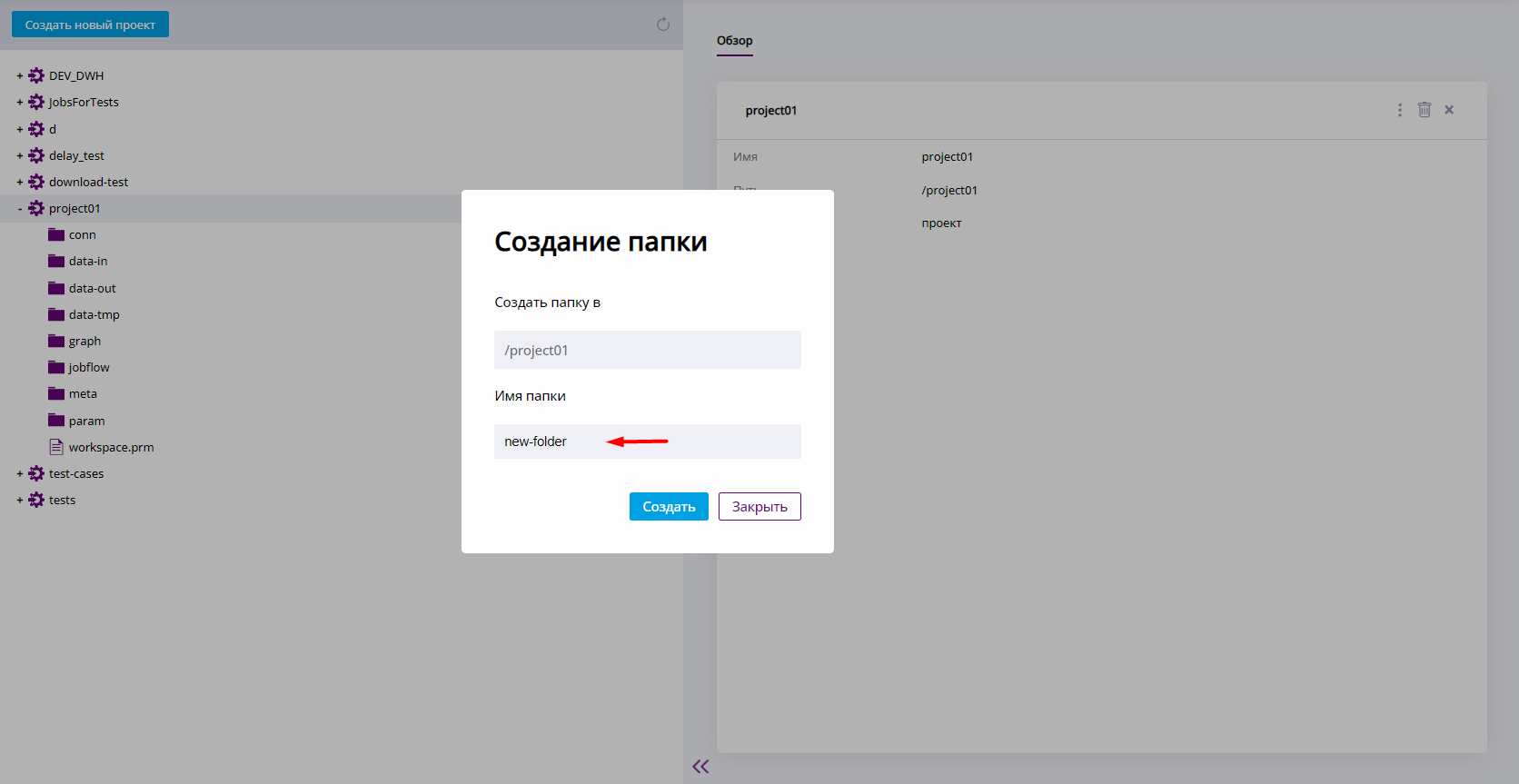
Отобразится диалоговое окно. Введите имя папки в поле "Имя папки". Нажмите Создать. Для отмены создания нажмите Закрыть.
Диалог создания папки
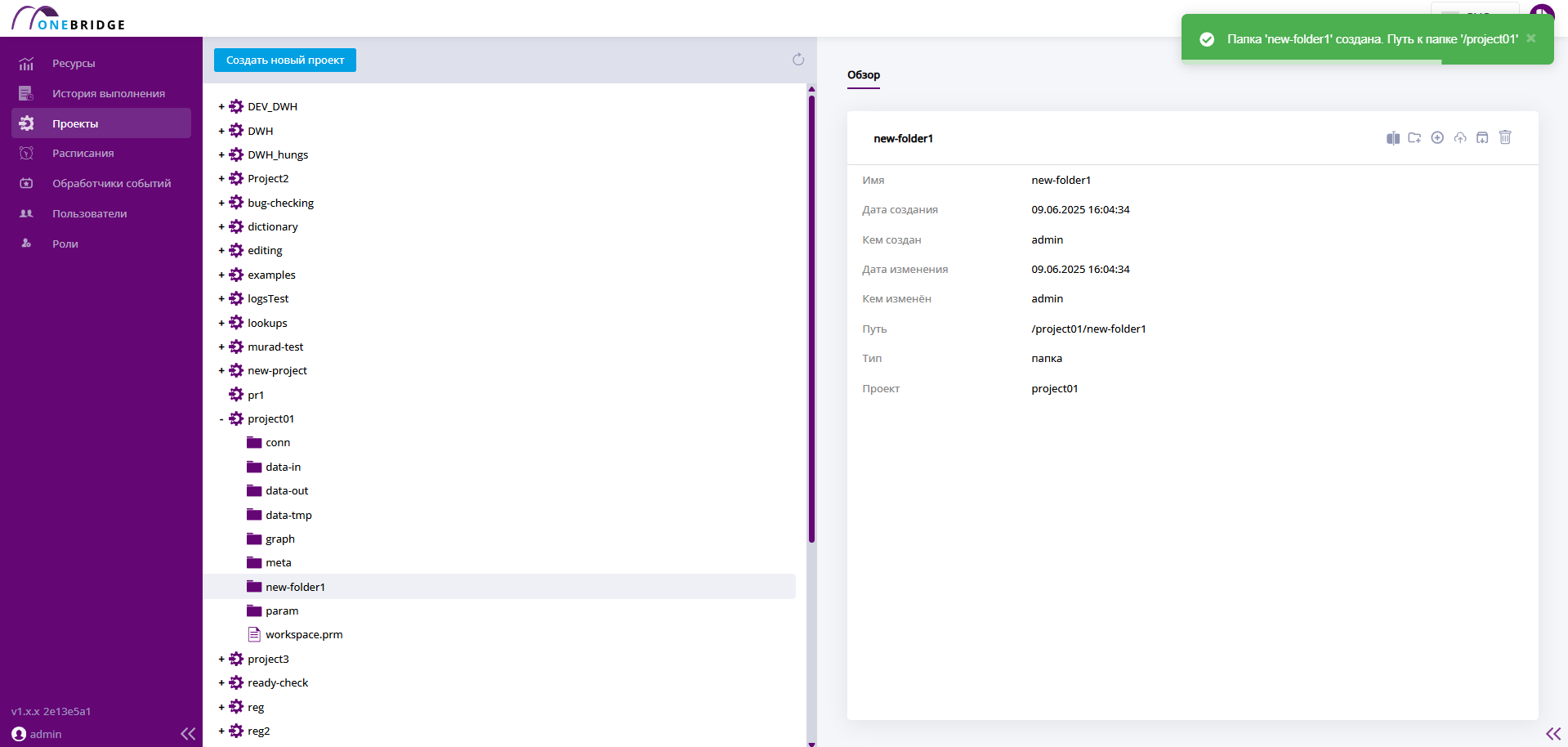
После создания папки в верхнем правом углу появится всплывающее уведомление с названием созданного элемента.
Новая папка создана
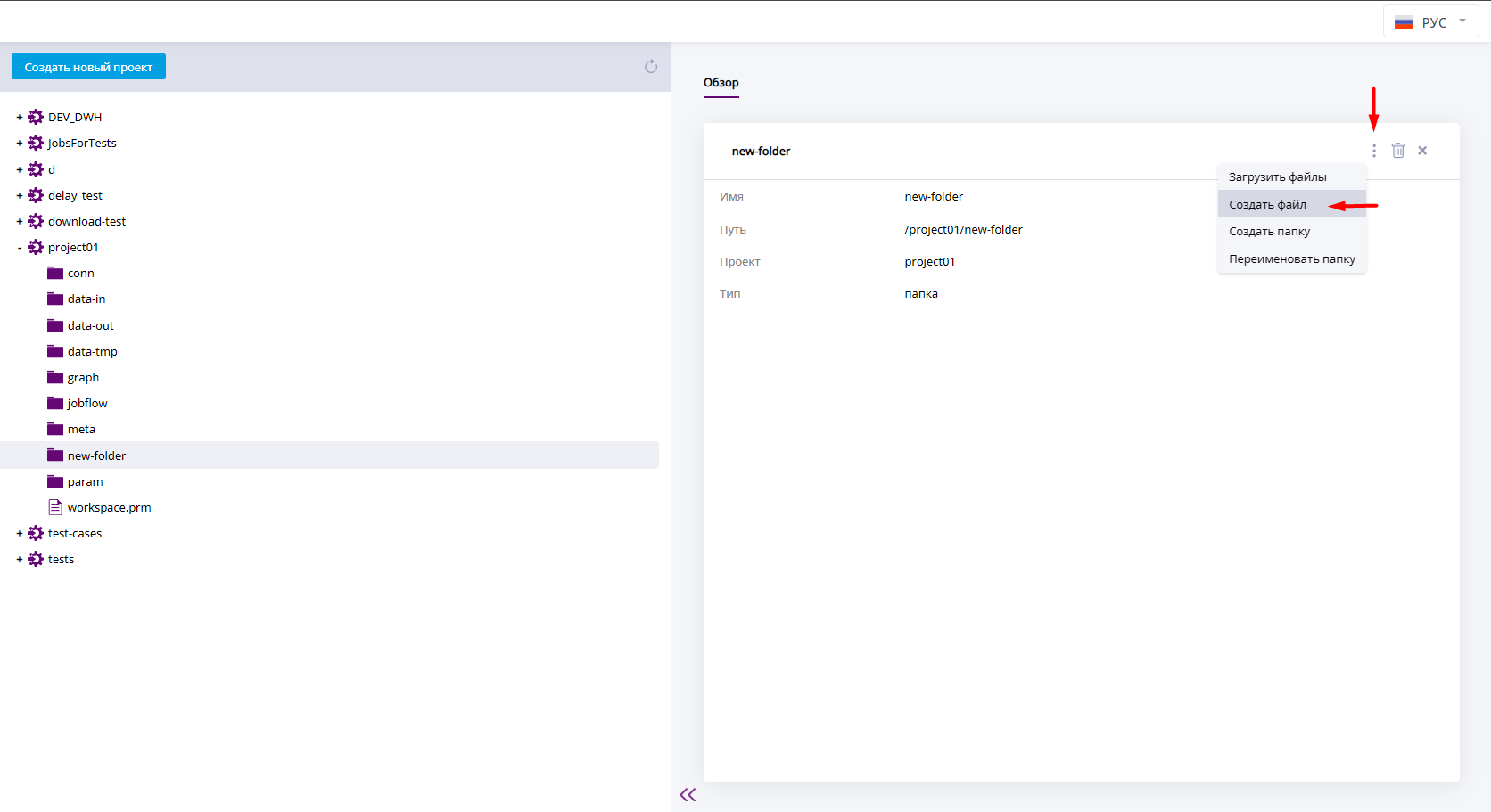
Создать файл
Файлы можно создавать как внутри проектов, так и внутри папок. Чтобы создать файл внутри папки, выберите соответствующее действие на обзоре той директории, в которой нужно создать файл. В правом верхнем углу вкладки "Обзор" нажмите Создать файл.
Меню директории при создании файла
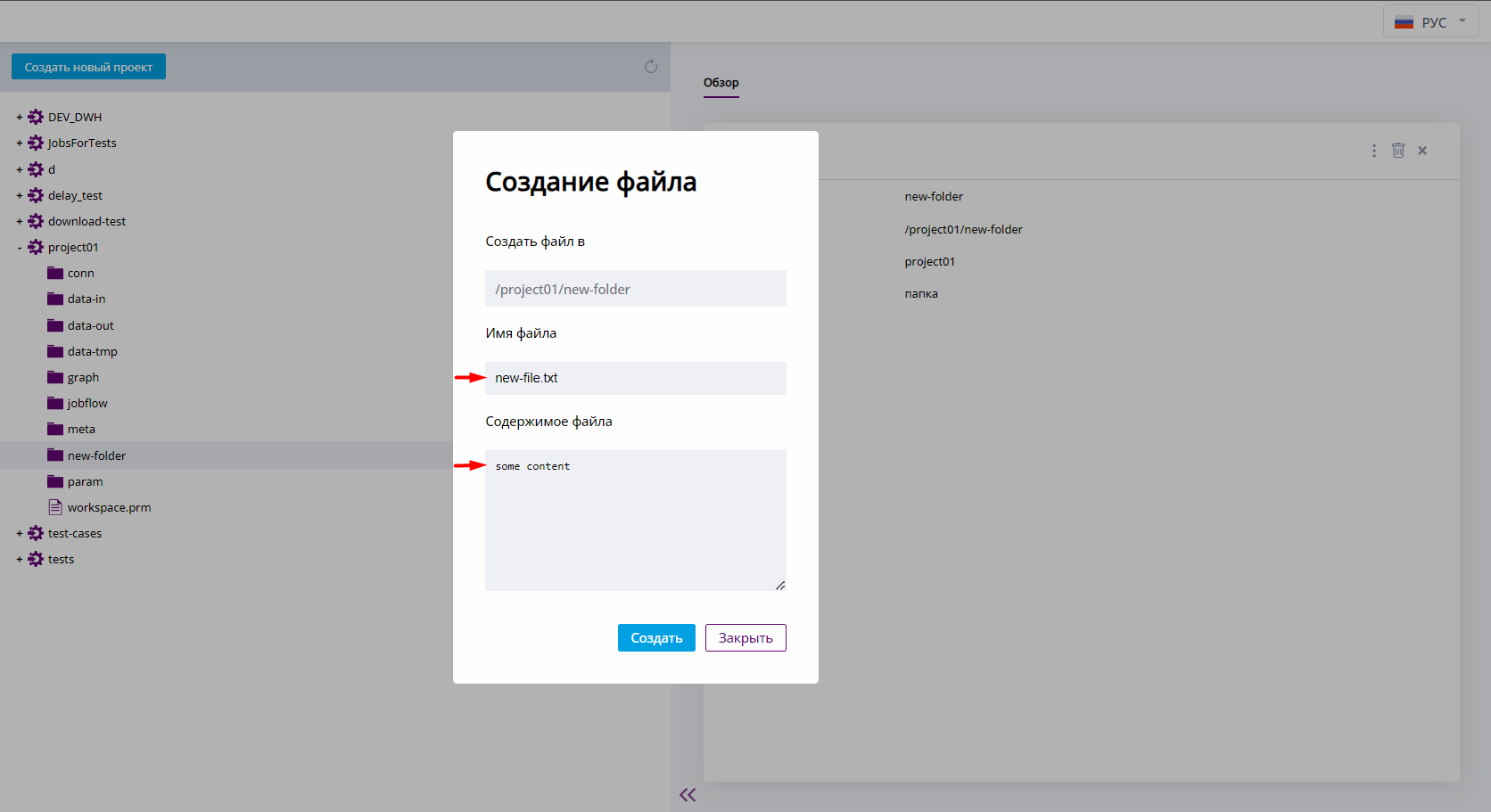
Откроется диалог создания файла. Путь к создаваемому элементу будет указан в поле "Создать файл в". Задайте название файла вместе с расширением в поле "Имя файла". При необходимости, внесите содержимое файла в поле "Содержимое файла". Нажмите Создать. Для отмены создания нажмите Закрыть.
Диалог создания файла
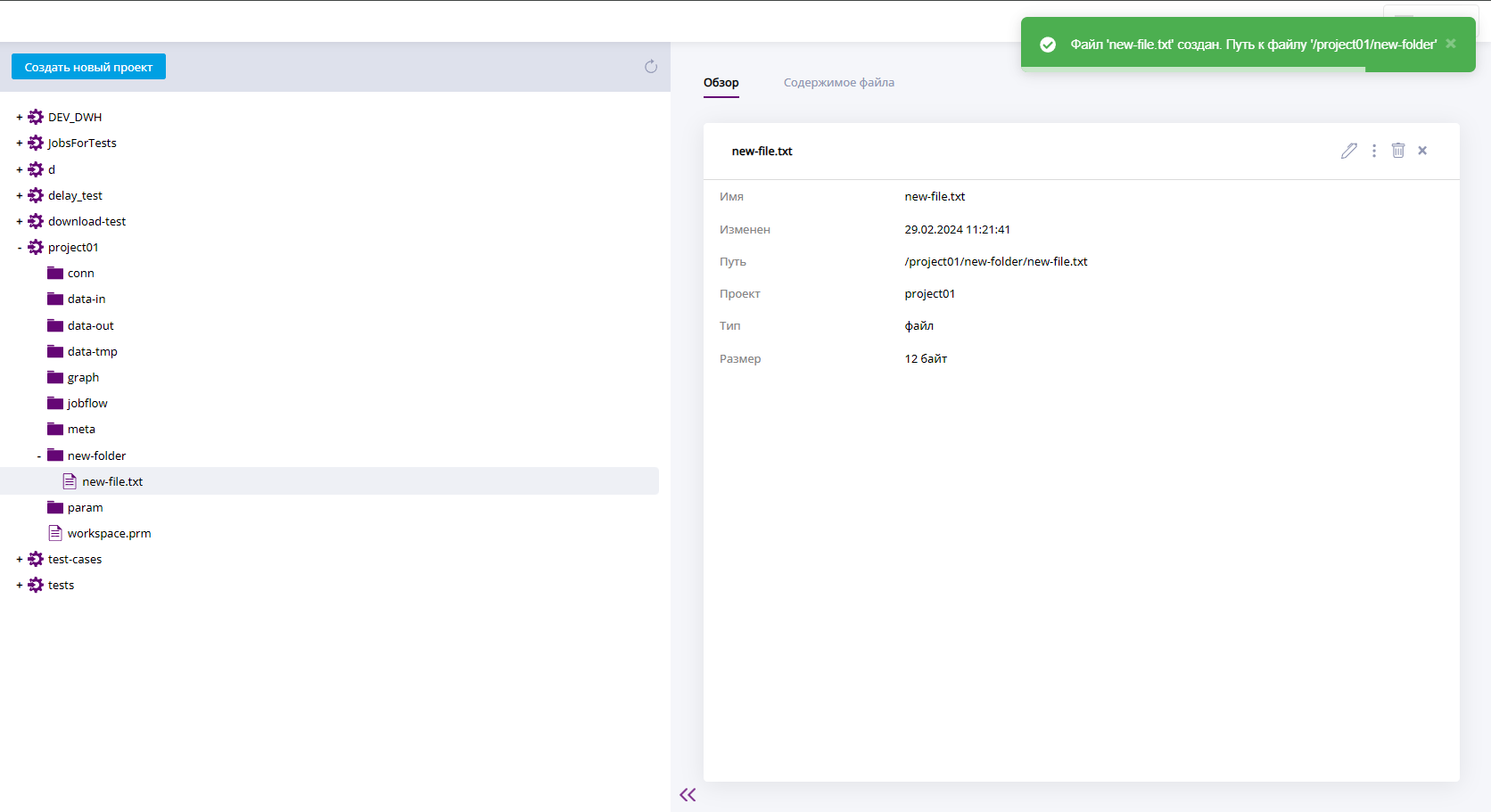
После создания файла в пустой папке рядом с её значком в дереве проектов появится значок "+". Это значит, что в папке есть элементы. Чтобы посмотреть список элементов, нажмите на "+", директория раскроется и станут видны содержащиеся в ней элементы. Значок "+" при этом изменится на "–".
Новый файл создан
Запуск графов
Чтобы запустить граф в работу, используйте кнопку Запустить граф. В диалоге запуска введите значения параметров, если необходимо, и нажмите Запустить.
Кнопка запуска графа
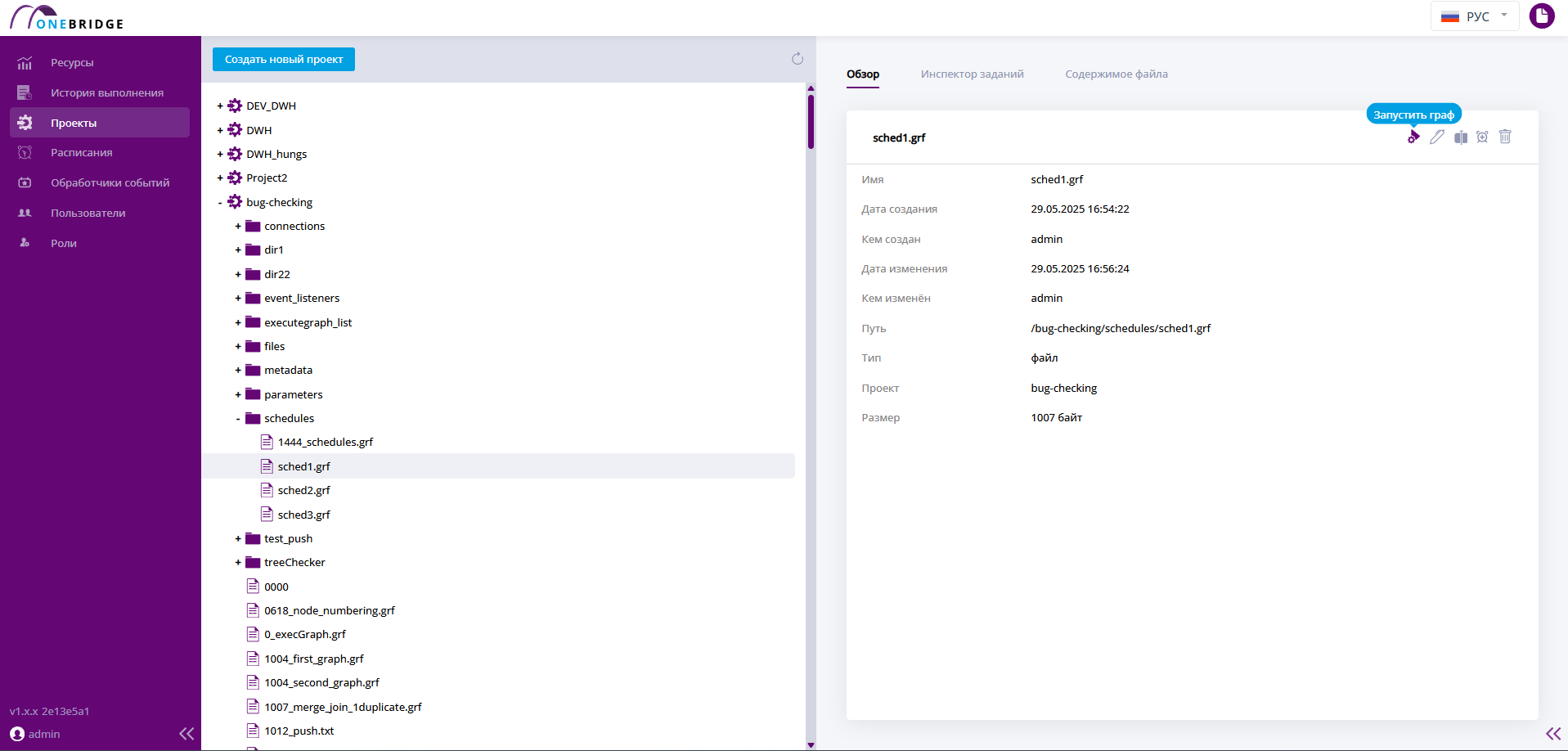
Диалог запуска графа
Уведомление о запуске графа
Просмотр результата запуска графа
Просмотреть результаты запусков всех графов можно на странице История выполнения.
Другие действия с папками и файлами дерева проектов
Удалить элемент
Чтобы удалить элемент дерева, например файл, используйте кнопку Удалить находясь на вкладке "Обзор" элемента, который собираетесь удалить. Подтвердите удаление, нажав Удалить.
Кнопка удалить
Диалог удаления файла
Переименовать элемент
Любой элемент дерева проектов можно переименовать с помощью кнопки Переименовать.
Переименование папки
Скачать архив
Проект или папку можно скачать целиком в виде архива. Для этого используйте кнопку Скачать в виде архива.
Скачивание проекта в виде архива
Загрузить файлы
Локальные файлы можно загрузить в проект. Для этого воспользуйтесь кнопкой Загрузить файлы.
Загрузка файлов в папку
Редактировать содержимое файла
Содержимое файла можно отредактировать. Для этого нажмите на иконку в виде пишущей ручки на панели дополнительной информации. Вы будете автоматически перенаправлены на вкладку "Содержимое файла".
Включение режима редактирования файла
Чтобы сохранить изменённый файл, нажмите Сохранить.
Сохранение изменений
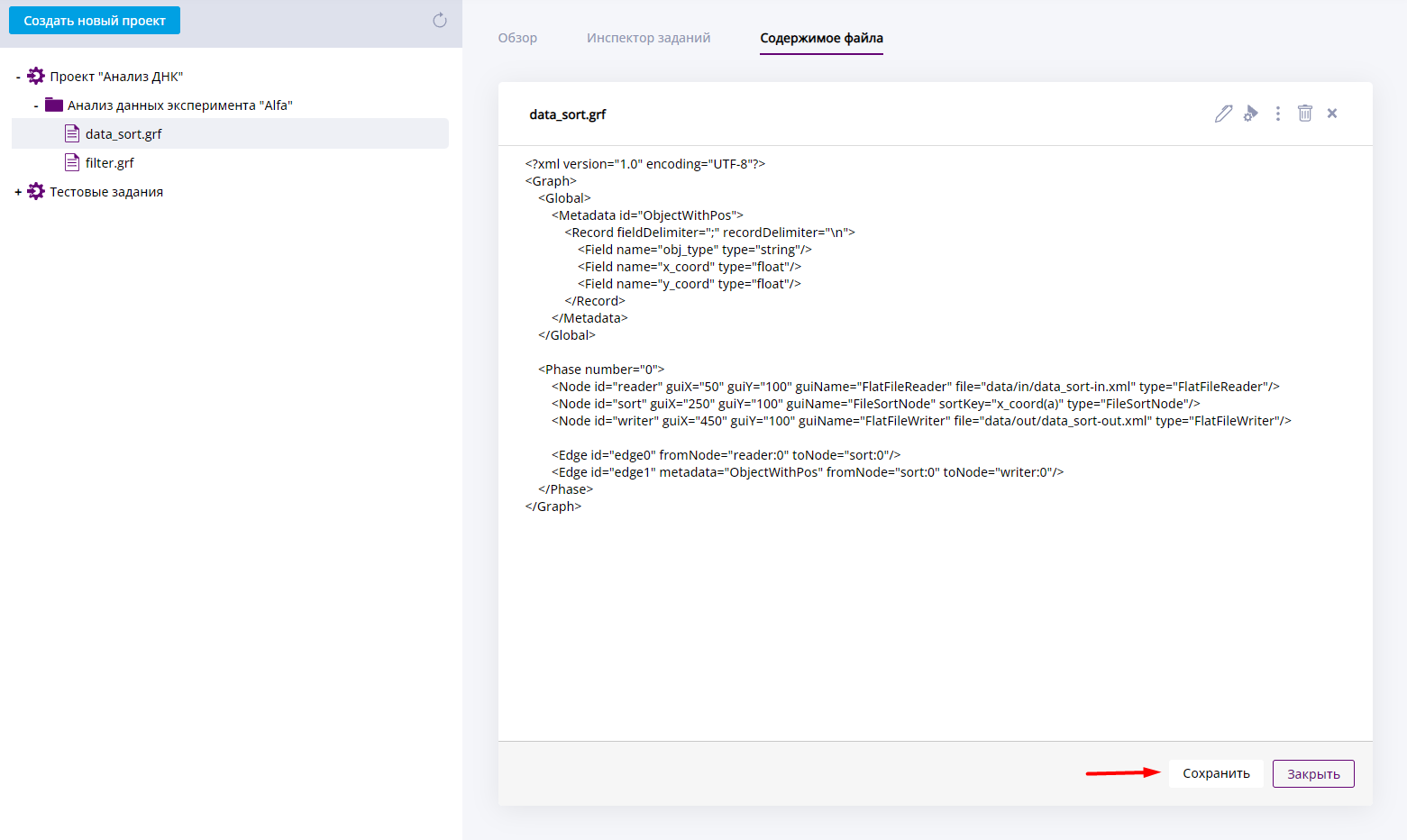
Чтобы выйти из режима изменения без сохранения, нажмите Закрыть.
Расписания
Раздел расписаний позволяет планировать запуск графов в конкретное время, устанавливаемому пользователем. Периодичность запуска настраивается.
Запланированные расписания представлены в виде таблицы, в которой указан статус расписания (включено/выключено), название расписания и имя запускаемого файла, дата и время последнего и следующего запусков.
Для каждого расписания можно открыть вкладку Обзор и просмотреть подробную информацию - интервал действия, заданные параметры.
Список созданных расписаний
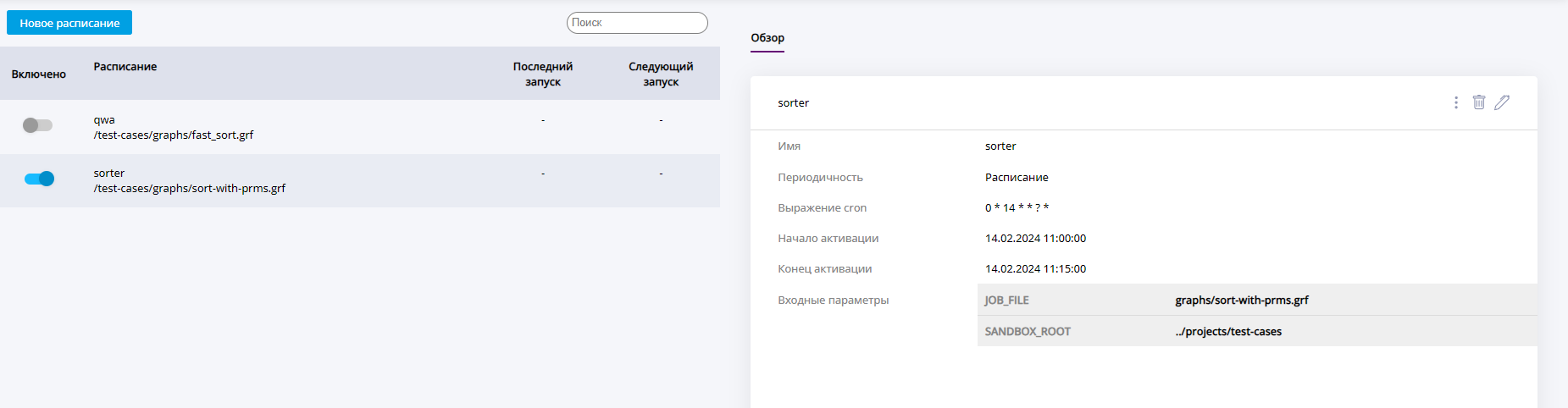
Каждое расписание представляет собой определение времени и периодичности запуска и указание файла графа и параметров для выполнения. После создания расписания можно редактировать значения его атрибутов, например, приостанавливать его выполнение, изменив статус.
Периодичность запуска расписаний:
- один раз - нужно задать время выполнения;
- с интервалом - нужно задать время начала и конца активации;
- расписание. Для создания такого расписания используется cron-выражение.
CRON-выражение используется для настройки триггера, в основном для повторяющегося срабатывания по расписанию. Оно представляет собой строку, состоящую из 7 полей. Эти поля разделены пробелами и содержат любые разрешенные значения в разных сочетаниях.
CRON-выражение может быть простым, например:
- "Срабатывать каждый понедельник в полночь" -
0 0 0 * mon *.Или более сложным, например:
- "Каждую пятую секунду, в минуты с 3 по 39, ежечасно, в определенные месяцы и дни недели, в течение 10 лет с 2024 по 2034 год" -
0/5 3-39 * ? mar,apr,may wed,thu 2024-2034
| Название | Обязательный | Описание |
|---|---|---|
| Имя | да |
Пример значения: |
| Периодичность | да |
Пример значения: |
| Время исполнения | да | Актуально для периодичности "Один раз".
Пример значения: |
| Частота | да | Актуально для периодичности "Интервал".
Пример значения: |
| Выражение cron | да | Актуально для периодичности "Расписание".
Пример значения: |
| Начало активации | да | Актуально для периодичности "Интервал" и "Расписание".
Пример значения: |
| Конец активации | да | Актуально для периодичности "Интервал" и "Расписание".
Пример значения: |
| Последний запуск | нет | Время последнего запуска расписания.
Пример значения: |
| № последнего запуска | нет | Идентификатор последнего произведенного запуска.
Пример значения: |
| Статус последнего запуска | нет | Статус последнего произведенного запуска.
Пример значения: |
| Следующий запуск | нет | Время следующего запуска расписания.
Пример значения: |
| Дата создания | да | Дата создания расписания.
Пример значения: |
| Кем создан | да | Логин автора расписания.
Пример значения: |
| Дата изменения | нет | Дата изменения расписания.
Пример значения: |
| Кем изменен | нет | Логин автора изменения расписания.
Пример значения: |
| Файл графа | да |
Пример значения: |
| Входные параметры | нет |
Пример значения:
|
Создать расписание
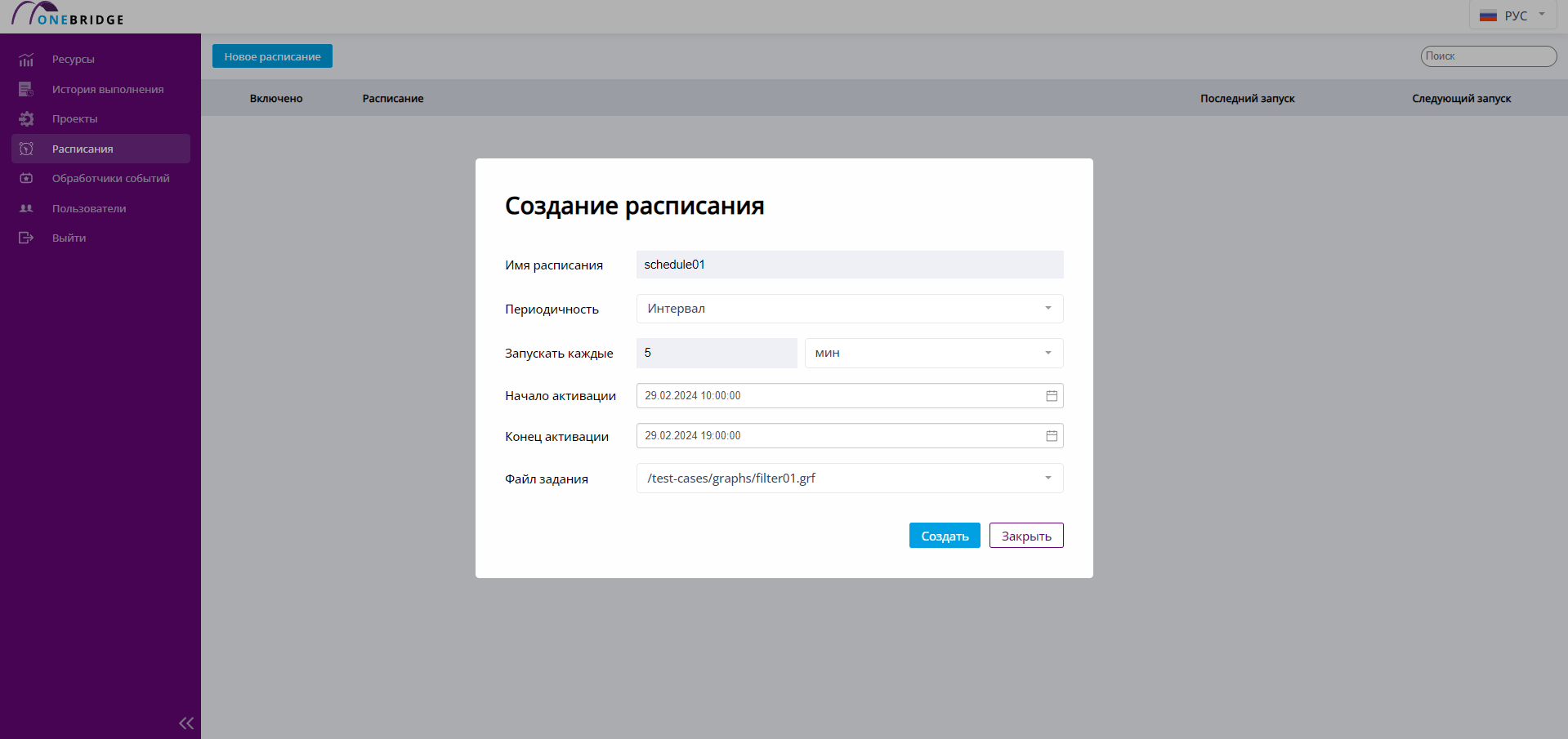
Чтобы открыть диалог создания расписания, нажмите Новое расписание находясь на странице "Расписания".
В открывшемся окне введите имя расписания, периодичность запуска, время активации, выберите файл графа, который надо запустить, при необходимости задайте параметры. Нажмите «Создать», чтобы создать расписание.
Диалог создания нового расписания
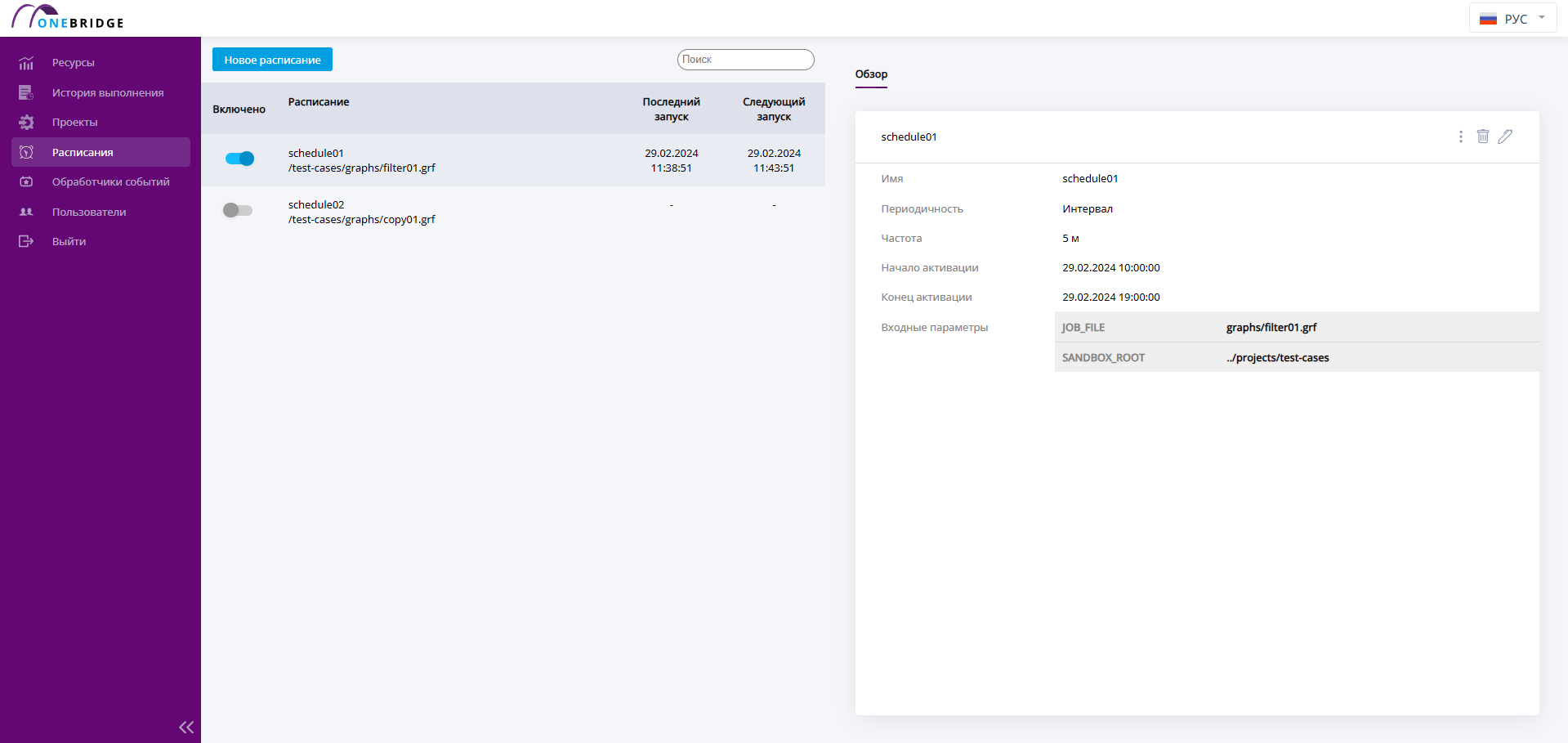
Расписание будет создано и запущено в заданное время. Созданное расписание можно увидеть в таблице расписаний. Работающие расписания помечены как включенные с помощью синего переключателя. Чтобы выключить расписание – нажмите на переключатель, чтобы он стал серым.
Список запланированных задач
Выполнение расписания можно проверить на странице «История выполнения».
Проверка запуска запланированной задачи в истории выполнения
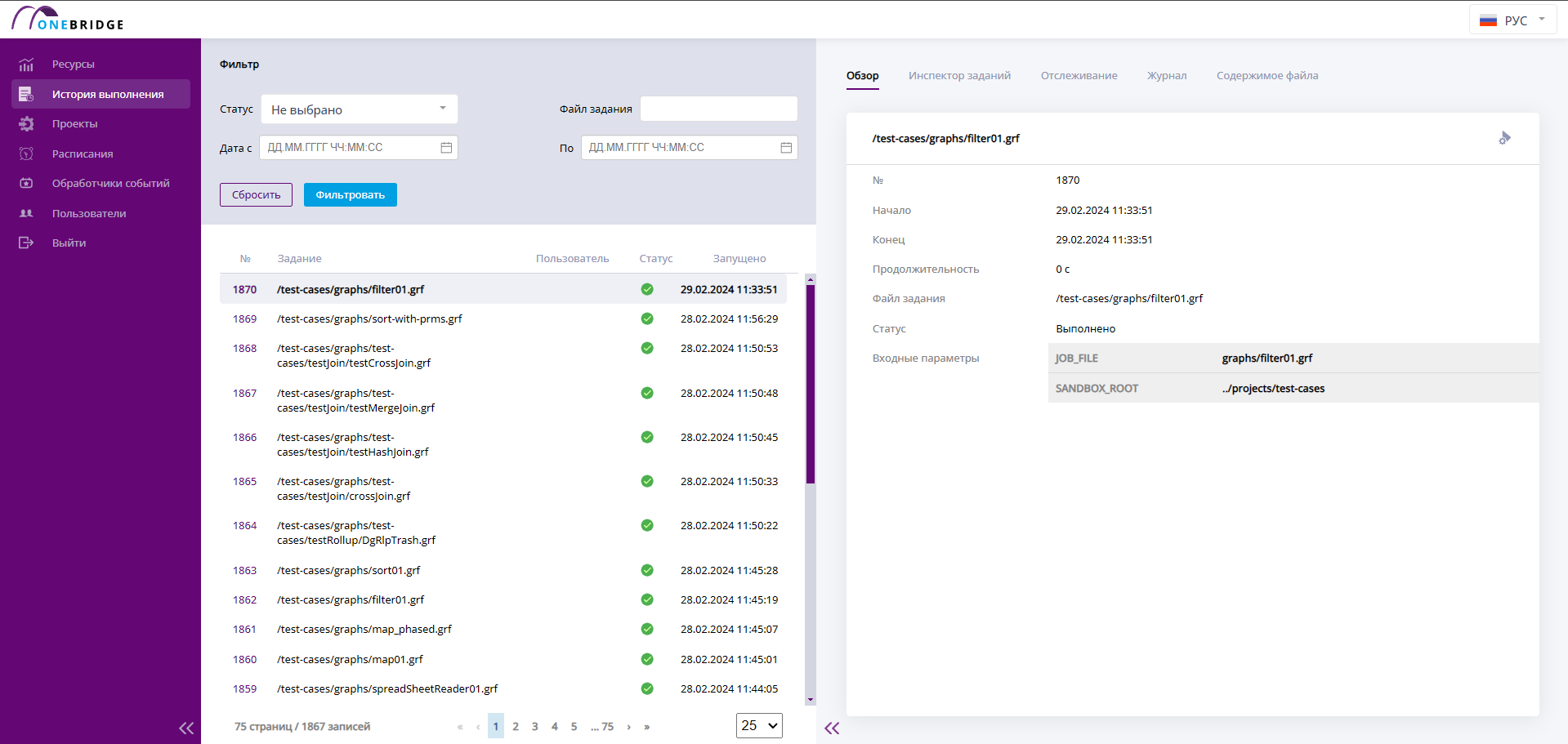
Изменить расписание
Для редактирования расписания нажмите значок в виде пишущей ручки на вкладке "Обзор". В открывшемся окне можно изменить тип расписания, время и файл, который будет запущен.
Редактирование расписания
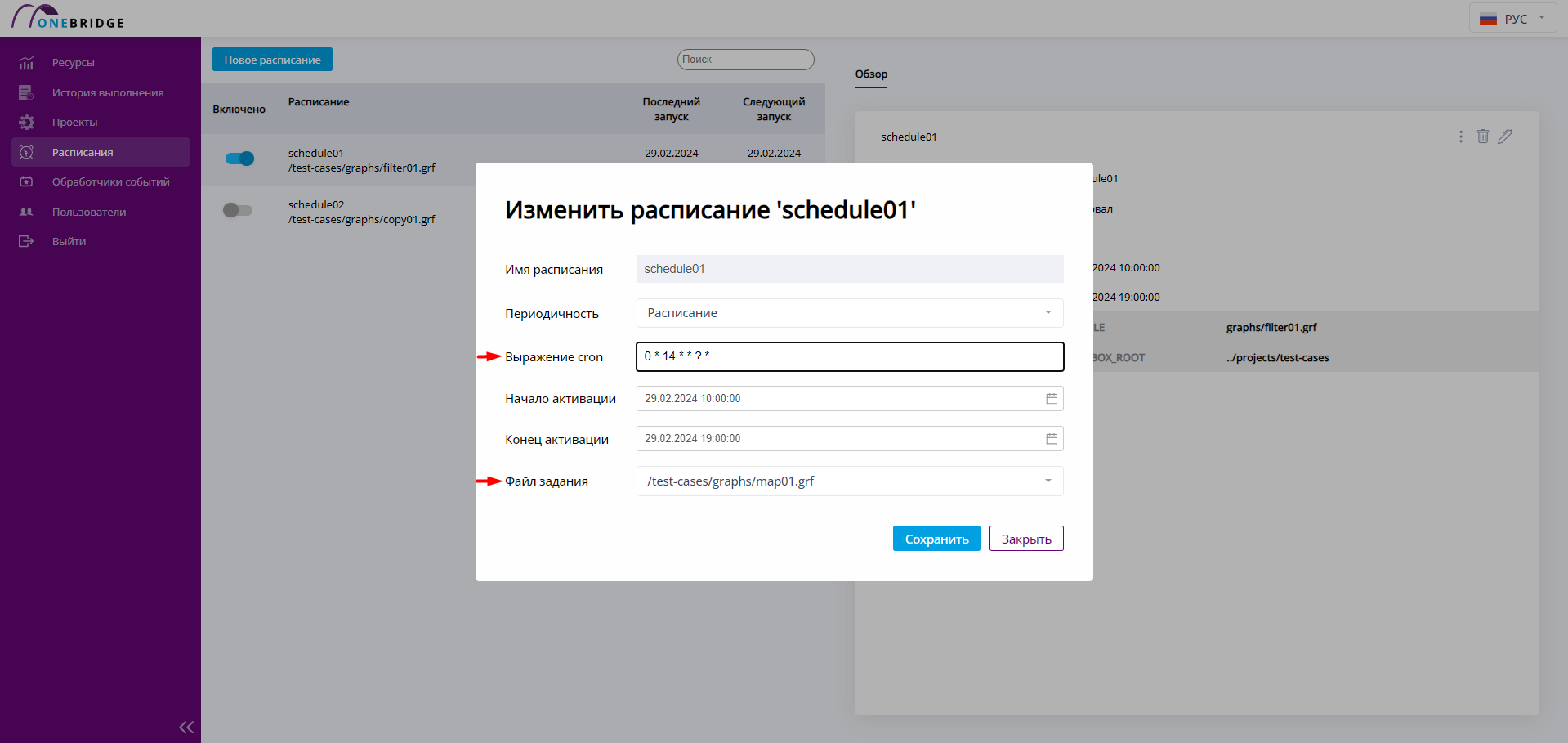
Измененное расписание
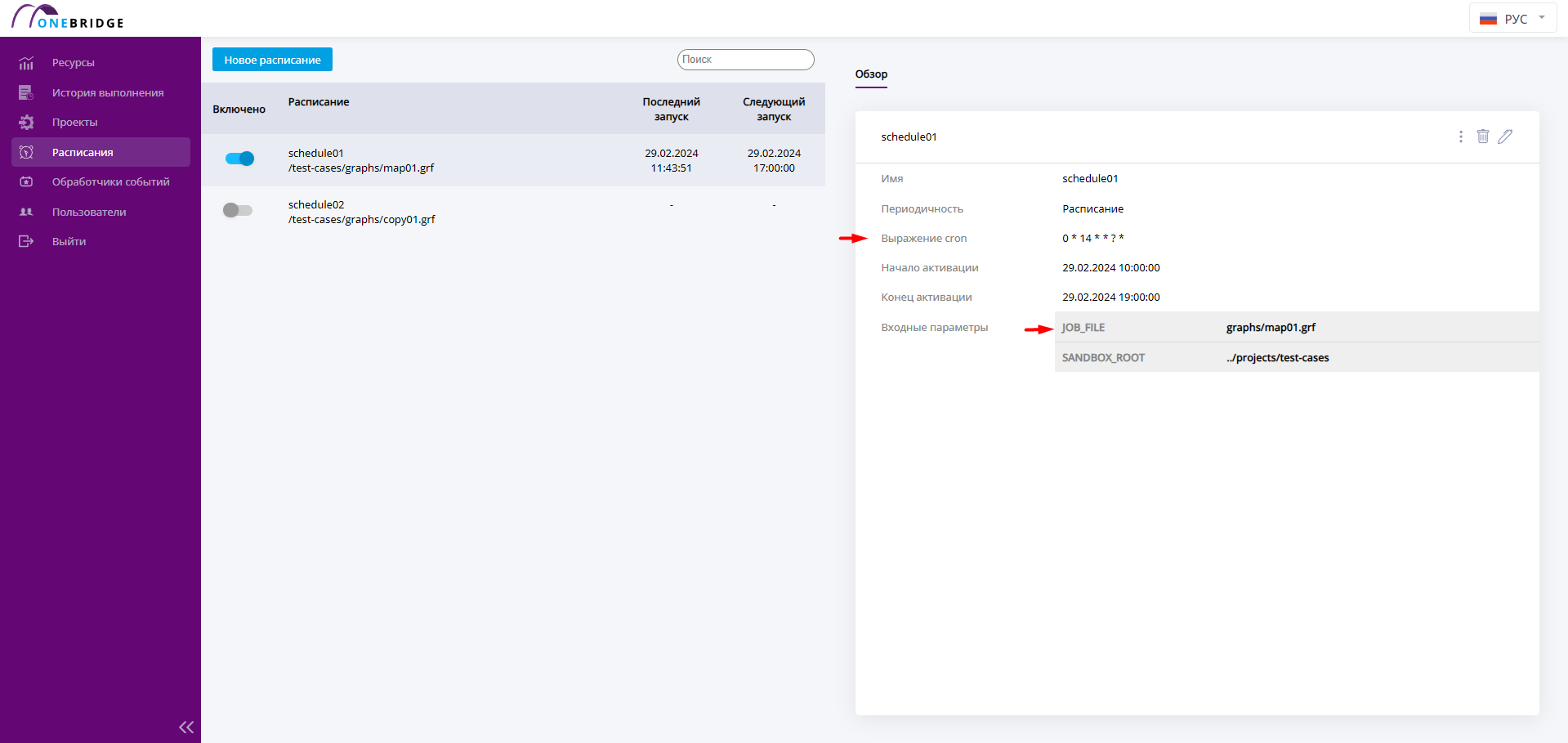
Чтобы переименовать расписание, воспользуйтесь меню из трёх точек, введите новое имя расписания.
Переименование расписания
Удалить расписание
Чтобы удалить расписание, нажмите значок мусорного ведра на вкладке Обзор и подтвердите удаление в появившемся диалоговом окне.
Удаление расписания
Обработчики событий
Обработчики событий – это инструменты для отслеживания изменений в системе и совершения запланированных действий. С их помощью можно настроить запуск выполнения определенной задачи, после выполнения указанного события.
Список созданных обработчиков событий

Виды обработчиков:
- обработчики событий привязаны к определенному рабочему процессу и отрабатывают каждый раз, когда рабочий процесс выполняется;
- обработчики файловых событий отслеживают изменения в файловой системе и реагируют на такие изменения запуском определенной задачи.
Обработчики ждут наступления события и запускают определенное в их настройках действие, если событие происходит. Созданные обработчики отображаются в списке обработчиков событий.
Отслеживаются следующие события:
- Завершение работы графа с определенным статусом
- События с файлами – создание/удаление
Список обработчиков содержит следующую информацию:
| Поле | Описание |
|---|---|
| ID | Порядковый номер обработчика, присвоенный при создании. |
| Включено | Показывает, включен ли обработчик. |
| Обработчик события | Имя обработчика. |
| Последний запуск | Дата и время последнего запуска обработчика. |
| Статус последнего запуска | Статус последнего выполненного обработчиком запуска. |
Типы задач, которые можно выполнить с помощью обработчиков:
- запуск графа;
- выполнение системной команды.
| Название | Обязательный | Описание |
|---|---|---|
| Имя | да |
Пример значения: |
| Событие | да |
Возможные значения: |
| По завершению | да | Актуально для события "Граф".
Пример значения: |
| Статус выполнения | да | Актуально для события "Граф".
Возможные значения: |
| Проверка | да | Актуально для события "Файл".
Возможные значения: |
| Файловая система | да | Актуально для события "Файл".
Пример значения: |
| Интервал | да | Актуально для события "Файл".
Пример значения: |
| Путь | да | Актуально для события "Файл".
Пример значения: |
| Выполнить действие | да | Актуально для события "Файл".
Возможные значения: |
| Начало | да |
Пример значения: |
| Последний запуск | нет | Время последнего запуска обработчика.
Пример значения: |
| № последнего запуска | нет | Идентификатор последнего произведенного запуска.
Пример значения: |
| Статус последнего запуска | нет | Статус последнего произведенного запуска.
Возможные значения: |
| Дата создания | да | Дата создания обработчика.
Пример значения: |
| Кем создан | да | Логин автора обработчика.
Пример значения: |
| Дата изменения | нет | Дата изменения обработчика.
Пример значения: |
| Кем изменен | нет | Логин автора изменения обработчика.
Пример значения: |
| Входные параметры | нет |
Пример значения: |
Создать обработчик событий
Чтобы настроить обработчик, выберите Новый обработчик на вкладке Обработчики событий. Появится диалоговое окно для внесения значений атрибутов обработчика событий. Задайте название обработчика, выберите отслеживаемое событие и назначьте действие, которое будет выполнено, когда отслеживаемое событие совершится. Нажмите «Создать».
Создание обработчика событий
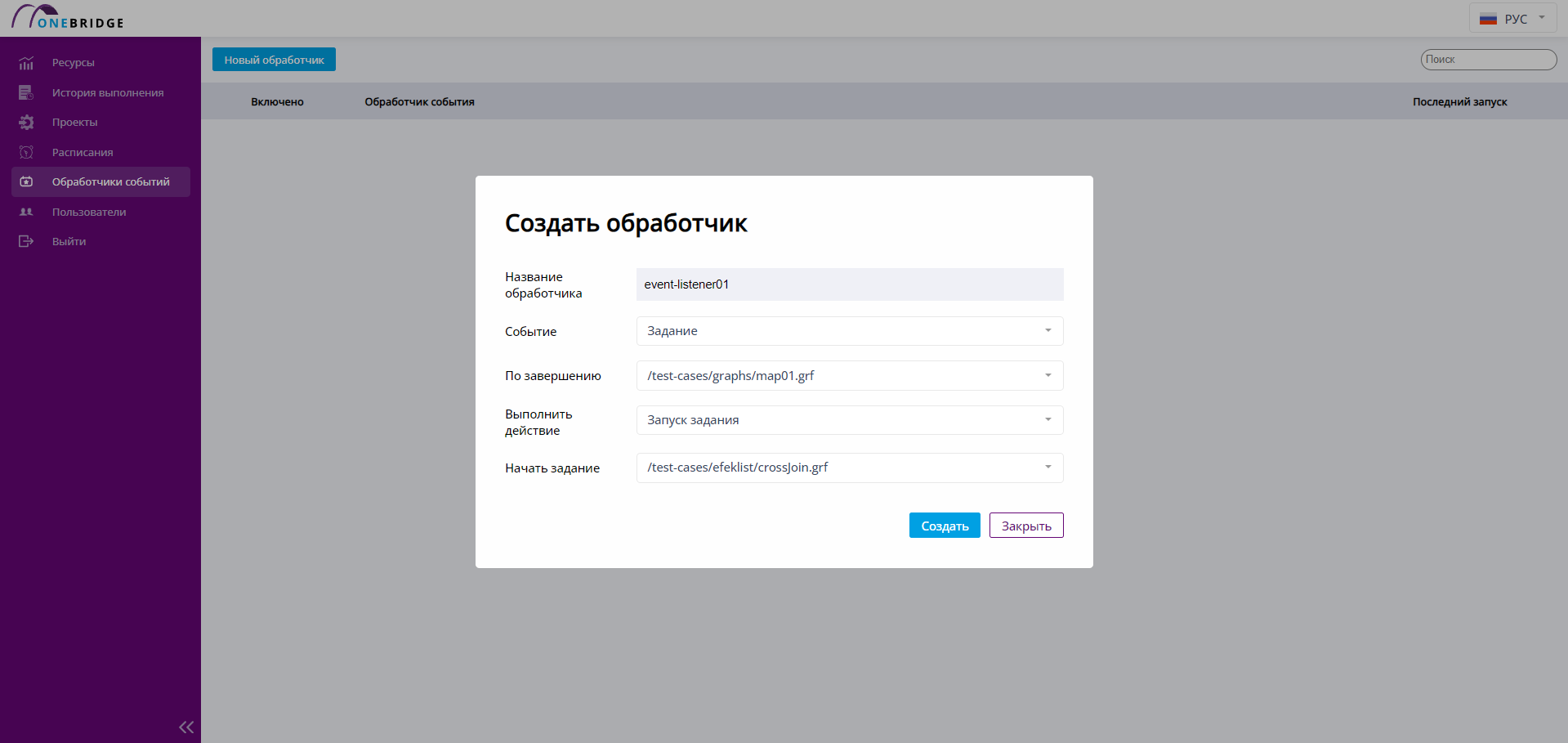
Созданный обработчик отобразится в списке.
Список обработчиков событий

Чтобы указать директорию для проверки появления или удаления в ней файла, укажите полный путь к папке на сервере в атрибуте "Путь" и добавьте в конце указание вида "/*".
Например, чтобы проверить добавление файла в папку "folder" проекта "project", укажите
Путь=путь на сервере до папки с проектами/project/folder/*.
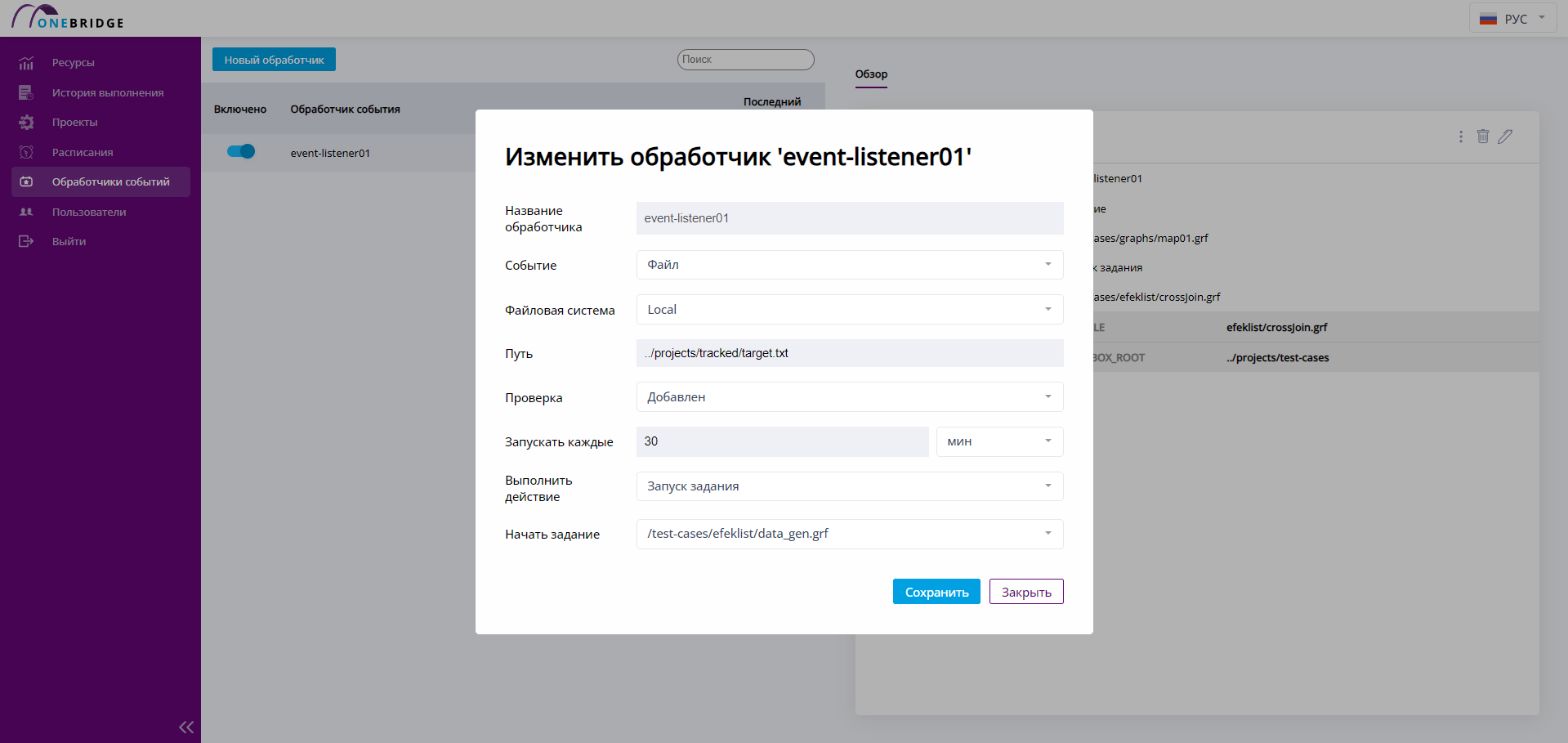
Отредактировать обработчик событий
Для того чтобы отредактировать обработчик событий, откройте вкладку Обзор, нажав на имя обработчика. На вкладке Обзор выберите кнопку редактирования в виде карандаша. В открывшемся диалоговом окне внесите изменения в обработчик событий.
Редактирование обработчика событий
Удалить обработчик событий
Чтобы удалить обработчик событий, нажмите кнопку удаления в виде мусорного ведра, подтвердите удаление в диалоговом окне.
Удаление обработчика событий
Управление пользователями
В OneBridge учётные записи пользователей создаются и редактируются на странице "Пользователи".
Пользователям можно назначать роли и привилегии для разграничения прав и уровней доступа.
Ролевая модель описана в главе Права доступа.
Управление пользователями OneBridge

Схема авторизации
В Onebridge существуют два типа пользователей:
- внутренние (метод аутентификации - Internal)
- внешние (метод аутентификации - LDAP)
Когда пользователь вводит логин и пароль на странице авторизации, производится проверка принадлежности пользователя к тому или иному существующему типу. Если в списке внутренних пользователей логин не найден - производится проверка в списке пользователей LDAP. Если логин не найден и там, выдается ошибка авторизации. В случае если пользователь найден по логину в одном из списков, сразу производится проверка совпадения паролей, если она пройдена, то пользователь получает ключ авторизации и входит в систему.
Схема авторизации пользователя в OneBridge

Далее описаны возможные действия с учётными записями пользователей:
- Создание нового пользователя
- Изменение записи пользователя
- Включение и отключение пользователей
- Недействительный пароль
- Назначение ролей и привилегий
Создание нового пользователя
Чтобы создать пользователя, нажмите Добавить нового пользователя. Появится диалоговое окно для внесения данных.
Внесите обязательную информацию, такую как логин, имя и почту. Нажмите Создать для создания и Закрыть для выхода из диалога без сохранения пользователя.
Создание пользователя

Если пользователь создан, появится окно с назначенным ему паролем. Пароль нужно скопировать, чтобы использовать для первой авторизации пользователя.
Сохранение дефолтного пароля пользователя

Всю доступную информацию о пользователе можно просмотреть на вкладке Обзор, кликнув на строку с его именем.
Просмотр информации о пользователе

В Обзоре отображаются следующие данные о пользователе:
| Имя атрибута | Описание |
|---|---|
| Метод аутентификации | Internal / LDAP |
| Логин | Идентификатор пользователя, может состоять только из букв и цифр. Нельзя поменять после создания. |
| Имя | Имя пользователя, может состоять только из букв и цифр. |
| Фамилия | Фамилия пользователя, может состоять только из букв и цифр. |
| Адрес электронной почты пользователя, может состоять из букв, цифр и знаков препинания. | |
| Статус | Статус пользователя (active / blocked), меняется с помощью синего свитч-переключателя. |
| Дата последнего входа | Дата и время, когда пользователь последний раз авторизовался. |
| Статус последнего входа | success / failure / not_set |
Изменение записи пользователя
Для изменения данных пользователя нажмите кнопку Редактировать пользователя в виде карандаша на вкладке Обзор. В открывшемся диалоге внесите изменения, затем нажмите Сохранить для сохранения изменений или Закрыть, чтобы выйти из диалога без сохранения. Новые данные отобразятся на вкладке Обзор.
Поменять можно только полное имя и электронный адрес пользователя. Логин пользователя поменять нельзя.
Изменение информации о пользователе

Просмотр обновлённой информации о пользователе

Включение и отключение пользователей
Созданных пользователей нельзя удалить через интерфейс, но учётные записи пользователей, которые потеряли свою актуальность, можно заблокировать. Для этого нужно кликнуть на синий переключатель, статус пользователя сменится.
Смена статуса учётной записи пользователя

Сменить пароль
Если пользователь забыл свой пароль, администратор с соответствующей ролью может сбросить его пароль через меню на вкладке Обзор.
Сброс пароля от учётной записи пользователя

Новый пароль будет выведен в диалоговое окно. Администратор может скопировать его и передать пользователю. При входе пользователю нужно будет ввести сгенерированный пароль и задать новый.
Копирование нового пароля от учётной записи пользователя

Назначение ролей и привилегий
Каждому пользователю можно назначить роли и привилегии. Для настройки ролей пользователя перейдите на вкладку Роли. Чтобы выдать пользователю роль, выделите имя роли в графе "Все роли" и переместите с помощью кнопок управления в графу "Выданные роли". Сохраните изменения.
Назначение ролей пользователю

Привилегии выдаются пользователю на вкладке Привилегии. Возле каждой привилегии есть два чекбокса: левый чекбокс отвечает за привилегии, выданные через роли, присвоенные пользователю. Их можно отредактировать только на вкладке Роли. С помощью правого чекбокса можно выдать привилегию пользователю напрямую. Для этого выделите нужные привилегии, поставив галочку в соответствующем чекбоксе из правой колонки. Сохраните изменения.
Назначение привилегий пользователю

Управление ролями и привилегиями
Роли и принадлежащие им привилегии можно править на странице Роли.
Ролевая модель описана в главе Права доступа.
Чтобы создать роль нужно открыть диалог создания роли с помощью кнопки Добавить новую роль. Внести имя роли и её описание, сохранить.
Каждой роли можно назначить суброли и привилегии. Для настройки субролей роли перейдите на вкладку Роли на панели дополнительной информации. Чтобы выдать роли суброль, выделите имя роли в графе Все роли и переместите с помощью кнопок управления в графу Выданные роли. Сохраните изменения.
Назначение субролей роли

Привилегии выдаются роли на вкладке Привилегии. Кликните на чекбокс рядом с нужной привилегией, чтобы добавить ее в список привилегий конкретной роли. Сохраните изменения.
Назначение привилегий роли

Сервер OneBridge
Сервер OneBridge отвечает за обработку данных, сбор статистики использования ресурсов сервера, оркестрацию выполняемых и запланированных графов.
Этот модуль состоит из инструкций по обработке данных и содержит программные интерфейсы для передачи необходимой информации в другие модули и взаимодействия с рабочими процессами OneBridge.
В главах этого раздела описано устройство файлов графов, рассказано о параметрах и метаданных, используемых для работы и приведено описание всех компонентов, которые используются для обработки данных.
Механизм выполнения заданий
Сервер OneBridge использует концепцию воркеров для эффективного и параллельного выполнения графов. Каждый граф, запущенный в системе, получает свою собственную независимую копию воркера. Это позволяет одновременно обрабатывать несколько графов, не влияя на их выполнение и обеспечивая изоляцию процессов.
Внутри каждого воркера узлы графа также выполняются параллельно. Для каждого узла выделяется отдельный поток выполнения, что оптимизирует использование ресурсов и ускоряет обработку данных. Такой подход обеспечивает максимальную производительность и позволяет системе эффективно справляться с большим количеством одновременно выполняемых задач.
Графы
Граф – это файл с описанием последовательности обработки данных в формате XML. Имеет расширение .grf.
В этой главе описаны:
Структура файлов графов OneBridge
В системе определены некоторые элементы, которые стоит использовать для корректной передачи информации и отображения графов в инспекторе задач.
После декларации следует указать начальный тег корневого элемента документа <Graph>. В этот элемент помещается все описание алгоритма обработки данных, все используемые узлы, ребра и их метаданные.
За ним следуют строки, описывающие дочерние элементы корневого элемента. Два главных дочерних элемента это <Global> и <Phase>. В элементе <Global> описываются метаданные и параметры подключения.
Система OneBridge обрабатывает данные в виде записей. Каждая запись может состоять из нескольких полей разных типов. Метаданные хранят тип данных этих полей. Метаданные являются частью графа, они содержатся в файле графа и их нужно описывать в элементе <Metadata>, чтобы четко определить типы обрабатываемых данных.
Параметры подключения к базе данных, файлы с настройками, можно указать и подключить в элементе <GraphParameters>.
В <Phase> задаются атрибуты узлов графа <Node> и описываются ребра <Edge>. Описание узлов может содержать в себе дочерние элементы <Attr>, в которых описываются методы преобразования записей данных.
Последняя строка файла содержит конечный тег корневого элемента: </Graph>.
На схеме ниже представлена иерархия элементов в файле графа.

Элементы файла графа
Ниже приведена таблица с описанием возможных элементов файла графа.
| Элемент | Родительский элемент | Описание элемента |
|---|---|---|
| Graph | нет | Является главным элементом, определяющим граф. Содержит информацию о файле графа.* Обязательный тег для отрисовки графа в инспекторе. |
| Global | Graph | Содержит информацию о файле, не имеет атрибутов. Дочерние элементы: - Metadata - используемые метаданные; - GraphParameters – параметры графа; - Connection – подключения к базам данных. |
| Metadata | Global | Определяет тип данных записи |
| Record | Metadata | Используется для определения символов-разделителей полей и записей для узлов FlatFileReader и FlatFileWriter, которые читают и записывают данные изв плоские файлы. По умолчанию разделитель полей — "," разделитель строк — "n", если необходимо использовать другие разделители – нужно задать их в элементе Record с помощью конструкции:
|
| Field | Record | Содержит имя поля и его тип. Если задан Record, то все Field должны идти внутри него.
|
| GraphParameters | Global | Содержит элементы, в которых хранится информация для подключения к базам данных или путь к файлу для чтения. Может иметь атрибут scopeNonce - дополнительный параметр для защищенных параметров, например, пароля от базы данных. |
| GraphParameter | GraphParameters | Хранит параметры для используемых в файле узлов, например, путь к файлу для узла чтения данных. Атрибуты элемента описаны в таблице "Атрибуты элемента GraphParameter" |
| GraphParameterFile | GraphParameters | Подключает файл параметров. Атрибуты описаны в таблице "Атрибуты элемента GraphParameterFile" |
| Connection | Global | Хранит параметры подключения к базе данных. |
| Phase | Graph | Номер фазы присваивается узлам графа, если есть необходимость запускать часть узлов после завершения выполнения другой части узлов. Фаз в графе может быть несколько, так что им нужно присваивать атрибут number, указывающий очередность выполнения. Каждый граф выполняется параллельно в рамках одного и того же номера фазы; т. е. каждый узел и каждое ребро с одинаковым номером фазы выполняются одновременно. Если процесс останавливается на какой-то фазе, более высокие фазы не запускаются. Только после успешного завершения всех процессов в рамках одной фазы начнется следующая фаза. Ребра графа, в которых описывается соединение узлов должны быть описаны в одной фазе с используемыми узлами. То есть нельзя объявлять узлы в одной фазе, а связывать их ребром - в другой. |
| Node | Phase | Описывает атрибуты узла. Атрибуты описаны в таблице "Атрибуты элемента Node" |
| Attr | Node | Описывает логическое выражение для фильтрации и сортировки или метод преобразования данных. |
| Edge | Phase | Описывает связь между узлами графа. Атрибуты описаны в таблице "Атрибуты элемента Edge" |
Атрибуты элементов
Для графов: <GraphParameter> и <GraphParameterFile>
Для узлов:<Node>
Для рёбер:<Edge>
Атрибуты элемента GraphParameter
| Название | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| name | да | Имя параметра | name="READ_DIR" |
| value | нет | Значение параметра | value="test/files/generated" |
| public | нет | Публичность параметра | Значение по умолчанию: public="false" |
| required | нет | Обязательность указания значения параметра при запуске графа | Значение по умолчанию : required="false" |
| secure | нет | Параметр зашифрован | Значение по умолчанию: secure="false" |
- если public="true" и required="true", тогда value игнорируется;
- если public="true" и value не задан, тогда required устанавливается в "true";
- если public="false", то required игнорируется;
- если public="false", то value должно быть задано;
- значение name не может содержать в себе подпоследовательность "${".
Атрибуты элемента GraphParameterFile
| Атрибут | Обязательный | Описание | Возможные значения |
| fileURL | да | Путь к файлу с параметрами |
|
Атрибуты элемента Node
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| id | да | Удобное название узла для указания в атрибутах ребер графа. | id="reader" |
| guiName | нет | Имя узла, отражаемое в инспекторе графов. Может быть любым. | guiName="read" |
| guiX | нет | Координата X левого верхнего угла узла для визуального отображения узла в инспекторе задач. | guiX="-132" |
| guiY | нет | Координата Y левого верхнего угла узла для визуального отображения узла в инспекторе задач. | guiY="212" |
| type | да | Тип узла. Определяет функциональность данного узла. |
Все имеющиеся в системе типы узлов: type="FLAT_FILE_READER" type="FLAT_FILE_WRITER" type="EXT_SORT" type="HASH_JOIN" |
Атрибуты элемента Edge
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| id | да | Уникальное название ребра в пределах графа. | id="edge0" |
| fromNode | нет | Имя исходного компонента с указанием порта. | fromNode="test_join:0" |
| toNode | нет | Имя конечного компонента с указанием порта. | toNode="FlatFileWriter1:0" |
| batch | нет | Объём данных, передаваемых ребром, в Мб. | batch="1024" |
| meta | да | Идентификатор метаданных, назначаемых данному ребру. | meta="metaname" |
В следующих главах более подробно рассмотрено устройство графов и описано взаимодействие с ними.
Узлы графа
Узел (нода) – это компонент графа с определёнными значениями атрибутов, выполняющий конкретную функцию в рамках графа. Этот минимальный алгоритм обработки данных может исполнять функцию чтения, копирования, очистки, объединения данных и т.д.
Отображение узлов FlatFileReader и FlatFileWriter в рабочей области дизайнера

Типы узлов
Все компоненты делятся на несколько групп:
- Для чтения - узлы для чтения обычно являются начальными компонентами графов. Они читают данные из входных файлов, подключенных входных портов либо генерируют данные по заданному шаблону.
- Для записи - узлы для записи обычно ставятся в конце графа. Они могут записать данные в файлы или базу данных, передать на выходной порт либо прервать передачу данных.
- Некоторые узлы используются для трансформации данных. Еще они называются преобразователями, так как могут изменять данные в соответствии с заложенным в них алгоритмом. Преобразователи получают данные и могут копировать их на все выходные порты, удалять дубликаты, фильтровать, сортировать, отправлять обработанные данные на один или несколько выходных портов.
- Объединители получают данные из двух или более источников, объединяют их в соответствии с указанным ключом и отправляют объединенные данные через выходные порты.
- узлы для управления ходом графов.
- узлы, которые не входят в вышеописанные группы объединены в группу Другие.
Порты
Порт - это точка входа или выхода данных из узла. У большинства узлов есть хотя бы один порт - входной или выходной. Портов одного вида также может быть несколько. К примеру, у Copy может быть несколько выходных портов.
Метаданные
Все узлы требуют, чтобы данные, обрабатываемые ими, имели определенную структуру.
Чтобы создать новые метаданные, откройте редактор метаданных из панели Outline, а затем внесите имя и тип новых метаданных.
Общие свойства узлов
Каждый узел можно настроить с помощью Редактора узла.
Среди свойств, которые можно установить в этом диалоговом окне, более подробно описаны следующие:
-
Каждый узел имеет метку с его названием (Именование узлов).
-
Каждый граф можно обрабатывать поэтапно (Фазы).
-
узлы можно отключить (Отключение узла).
Именование узлов
Каждый узел имеет имя, которое можно изменить. Поскольку в графе может быть несколько узлов одного вида, иногда может быть полезно изменить имя данное по умолчанию на более удобное.
Любой узел можно переименовать в редакторе узла, исправив значение атрибута node name.
Фазы
Каждый граф можно разделить на несколько фаз, задав номера фаз в редакторе узла. Номер фазы выводится в верхнем левом углу каждого узла.
Смысл деления графа на фазы в том, что каждый граф выполняется параллельно в пределах одной фазы; т.е. все узлы, имеющие одинаковый номер фазы, и входящие в них рёбра работают одновременно. Если процесс останавливается на какой-то фазе, более высокие фазы не начинаются. Только после того, как все процессы в рамках одной фазы успешно завершатся, начнётся следующая фаза.
Вот почему фазы должны оставаться неизменными во время работы графа. Номер следующей фазы графа всегда больше, чем номер предыдущей.
Таким образом, когда вы увеличиваете номер фазы на любом из узлов графа, принадлежащей одной фазе, все узлы с тем же номером фазы (но не узлы с более высокими номерами фаз), лежащие дальше по графу, автоматически меняют свою фазу на это новое значение.
Используйте редактор узла для настройки фазы, либо воспользуйтесь окошком на узле прямо в Рабочей области:
Установка фазы

Заметка: При назначении фаз внутри графа, можно указывать номер фазы с приращением больше, чем на 1 (например, 5, 10, 15…). Таким образом, позже вы сможете добавлять новые фазы между уже существующими фазами без необходимости корректировки нумерации всех фаз.
Включение узла
Все узлы по умолчанию включены. Чтобы включить отключенный узел, используйте контекстное меню узла и пункт Enable node.
Отключение узла
Чтобы отключить узел, выберите в контекстном меню узла пункт Disable node. Это отключит и все последующие узлы. Все отключенные узлы станут серого цвета. Любые записи, отправленные в отключенный узел, будут отброшены, как будто попали в TRASH.
Отключенные узлы помечаются серым цветом и отбрасывают все поступающие в них записи

Рёбра
Если в графе есть хотя бы два узла, их можно соединить ребром. Данные будут передаваться от одного узла к другому через это ребро. По этой причине каждому ребру должны быть назначены некоторые метаданные, описывающие структуру записей, проходящих через ребро.
При создании ребра, его концы всегда связывают исходящий порт одного узла с входящим портом другого узла. Количество портов одних узлов строго задано, а другие имеют неограниченное количество портов.
Атрибуты ребра:
| Атрибут | Обязательный | Описание | Значение |
|---|---|---|---|
| id | да | Имя ребра | id="FlatFileReader --> Map" |
| Output port id | нет | Начальный порт | fromNode="FlatFileReader0:0" |
| Input port id | нет | Конечный порт | toNode="Map0:0" |
| bufferSize | да | Размер выделенного для ребра буфера в памяти, измеряется в количестве записей. | bufferSize="256" |
| metadata | да | Имя метаданных | metadata="user_attrs" |
У ребер есть редактор, в котором можно изменить значения атрибутов bufferSize и metadata. Редактор открывается нажатием на пункт Edit контекстного меню ребра.
В инспекторе ребра можно увидеть структуру назначенных ему метаданных. Контекстное меню -> Inspect.
Чтобы удалить ребро, используйте пункт Remove.
Соединение компонентов ребром
Метаданные
Мета (метаданные) — это данные, описывающие структуру данных. Каждое ребро графа несет некоторые данные. Эти данные должны быть описаны с использованием метаданных. Метаданные описывают как запись в целом, так и все ее поля.
Записи могут быть разных типов, каждое поле может иметь разный тип данных.
Метаданные могут быть как внутренними, так и внешними (общими). Метаданные указываются в файле графа или в файле параметров.
Редактор метаданных описан в разделе "Создание и присвоение метаданных ребру".
Подробную информацию об изменении или определении разделителей в записях с разделителями или смешанных типах читайте в разделе "Определение и изменение разделителей".
Содержание главы:
- Поля и записи
- Типы данных в метаданных
- Типы метаданных
- Передача метаданных между компонентами графа
- Создание метаданных
Поля и записи
Запись можно рассматривать как строку файла данных или как строку таблицы базы данных. Запись состоит из полей. Каждое поле может иметь разный тип данных.
В записи каждые два соседних поля отделяются друг от друга разделителем полей, и вся запись также завершается разделителем записи. По умолчанию в системе OneBridge разделителем полей является запятая, а разделителем записей – символ переноса строки, то есть стандартная запись в файл будет произведена в таком виде:
<поле>,<поле>
<поле>,<поле>
Каждая запись относится к одному из следующих трех типов:
-
C разделителями. В записи с разделителями каждые два соседних поля отделяются друг от друга разделителем, и вся запись также заканчивается разделителем записи.
-
Фиксированной длины. В записи фиксированной длины каждое поле имеет определенную длину (размер). Длина измеряется в количестве символов.
-
Смешанный. В смешанной записи каждое поле может быть отделено друг от друга разделителем, а также иметь определенную длину (размер). Размер рассчитывается в количестве символов. Этот тип записи представляет собой смесь обоих типов, описанных выше. Каждое отдельное поле может иметь разные свойства. Некоторые поля могут иметь только разделитель, другие могут иметь указанный размер, остальные могут иметь как разделитель, так и размер.
Типы данных в метаданных
Каждое поле метаданных может иметь разный тип. В системе определены следующие типы данных:
| Тип | Описание | Пример |
|---|---|---|
| boolean | Логическое значение | true/false |
| date | Дата в указанном формате (format="%d.%m.%Y %H:%M:%S"). Подробнее о способах задать формат даты описано в главе "Формат даты и времени" | 01.01.2025 17:43:12 |
| integer | Целые числа | 42 |
| number | 64-битный тип с плавающей запятой | 0.0078125 |
| decimal | 96-битный тип (десятичная дробь) | -34.6523 |
| string | Строка хранит набор символов в кодировке UTF-8 | «это пример значения поля с типом string» |
Типы метаданных
Внутренние метаданные
Внутренние метаданные являются частью графа, они содержатся в файле графа и их можно увидеть на вкладке Источник.
Создание внутренних метаданных
Для создания метаданных в редакторе, откройте его из панели Outline из контекстного меню Metadata -> New metadata. Задайте имя записи, задайте имена полей метаданных, резделители полей и строк, укажите тип данных для каждого поля. Сохраните изменения кнопкой Save.
Создание метаданных в редакторе

Подробнее использование редактора метаданных описано в разделе Дизайнер.
Внешние метаданные
Внешние (общие) метаданные располагаются в отдельном файле и могут использоваться несколькими графами.
Создание внешних метаданных
Для создания внешних метаданных, выберите в контекстном меню папки, в которую хотите поместить файл метаданных, пункт New file. Задайте название и расширение .fmt для этого файла.
Затем откройте созданный файл в рабочей области и задайте его содержимое на вкладке Source.
Указание метаданных во внешнем фйле

Связывание внешних метаданных
После создания внешние метаданные должны быть связаны с каждым графом, в котором они будут использоваться. Для этого нужно щелкнуть правой кнопкой мыши группу Метаданные на панели Outline и выбрать Link metadata в контекстном меню. После этого откроется редактор матаданных, в который нужно ввести путь до файла с метаданными. Путь указывается относительно проекта.
Линкование метаданных в редакторе
Передача метаданных между компонентами графа
В данный момент реализовано назначение метаданных вручную каждому ребру. Это можно сделать двумя способами:
- Открыть редактор ребра двойным щелчком по имени ребра. Выбрать имя меты в выпадающем списке, сохранить изменения, нажав Save.
- Перетащить нужные метаданные с панели Outline на ребро методом
drag-and-drop, зажавctrl.
Формат даты и времени
Форматирование описывает, как значения даты/времени должны считываться и записываться из/в строковое представление. На форматирование и синтаксический анализ дат также влияют локаль и часовой пояс.
На данный момент пересчет времени в зависимости от локального отключен, используется только серверное время в UTC. То есть если вы хотите установить расписание на
12:35по локальному времени и для вашего местоположения акутально UTC+3ч, время выполнения расписания следует указать09:35.
В OneBridge используется указание префикса для форматирования данных. Доступны два встроенных механизма обработки данных: стандартный для языка Rust модуль (описан в таблицах ниже) и международный формат ISO 8601 (https://en.wikipedia.org/wiki/ISO_8601).
Следующие спецификаторы доступны как для форматирования, так и для синтаксического анализа.
| Спецификатор | Пример | Описание |
|---|---|---|
| %Y | 2001 |
Полный год пролептического1 григорианского календаря, дополненный нулями до 4 цифр. Поддерживаются годы от -262144 до 262143. Годы до 1 г. до н.э. или после 9999 г. н.э. требуют начального знака (+/-). |
| %C | 20 |
Год, разделенный на 100, дополненный нулями до 2 цифр2. |
| %y | 01 |
Год, по модулю 100, дополненный нулями до 2 цифр2. |
| %m | 07 | Номер месяца (01–12), дополненный нулями до 2 цифр. |
| %b | Jul | Сокращенное название месяца. Всегда 3 буквы. |
| %B | July | Полное название месяца. Также принимает соответствующую аббревиатуру при парсинге данных. |
| %h | Jul | То же, что %b |
| %d | 08 | Номер дня (01–31), дополненный нулями до 2 цифр. |
| %e | 8 | То же, что %d, но дополнено пробелами. |
| %a | Sun | Сокращенное название дня недели. Всегда 3 буквы. |
| %A | Sunday | Полное название дня недели. Также принимает соответствующую аббревиатуру при парсинге. |
| %w | 0 | Числовое обозначение дня недели. Sunday = 0, Monday = 1, …, Saturday = 6. |
| %u | 7 | Числовое обозначение дня недели. Monday = 1, Tuesday = 2, …, Sunday = 7. (ISO 8601) |
| %U | 28 |
Номер недели, начинающийся с воскресенья (00–53), дополненный нулями до 2 цифр3. |
| %W | 27 | То же, что и %U, но неделя 1 начинается с первого понедельника этого года. |
| %G | 2001 |
То же, что %Y, но использует номер года в недельном календаре ISO 86014. |
| %g | 01 |
То же, что %y, но использует номер года в недельном календаре ISO 86014. |
| %V | 27 |
То же, что и %U, но использует номер недели в недельном календаре ISO 8601 (01–53)4. |
| %j | 256 | День года (001–366), дополненный нулями до 3 цифр. |
| %D | 07/08/01 | Формат `месяц-день-год`. То же, что %m/%d/%y. |
| %x | 07/08/01 | Представление даты в локали (например, 31.12.99). |
| %F | 2001-07-08 | Формат `год-месяц-день` (ISO 8601). То же, что %Y-%m-%d. |
| %v | 8-Jul-2001 | Формат `день-месяц-год`. То же, что %e-%b-%Y. |
Пролептический григорианский календарь (предваряющий григорианский календарь, от др.-греч. πρόληψις «предвосхищение») — календарь, расширяющий григорианский календарь на период до его введения 15 октября 1582 года.
%C, %y разделяют года по группам, поэтому для 100 г. до н.э. (номер года -99) будут напечатаны -1 и 99 соответственно.
%U: Неделя 1 начинается с первого воскресенья этого года. Неделя 0 может быть указана за несколько дней до первого воскресенья.
%G, %g, %V: неделя 1 — это первая неделя, в которой в этом году содержится не менее 4 дней. Недели 0 не существует, поэтому ее следует использовать с %G или %g.
| Спецификатор | Пример | Описание |
|---|---|---|
| %H | 00 | Количество часов (00–23), дополненное нулями до 2 цифр. |
| %k | 0 | То же, что %H, но дополнено пробелами. То же, что %_H. |
| %I | 12 | Количество часов в 12-часовом формате (01–12), дополненное нулями до 2 цифр. |
| %l | 12 | То же, что %I, но дополнено пробелами. То же, что %_I. |
| %P | am | am или pm в 12-часовом формате. |
| %p | AM | AM или PM в 12-часовом формате. |
| %M | 34 | Количество минут (00–59), дополненное нулями до 2 цифр. |
| %S | 60 |
Количество секунд (00–60), дополненное нулями до двух цифр5. |
| %f |
26490000 | Количество наносекунд с последней целой секунды6. |
| %.f |
.026490 | Доля секунды. Съедает ведущую точку6. |
| %.3f | .026 | Доля секунды с фиксированной длиной 3. |
| %.6f | .026490 | Доля секунды с фиксированной длиной 6. |
| %.9f | .026490000 | Доля секунды с фиксированной длиной 9. |
| %3f | 026 | Доля секунды, как %.3f, но без начальной точки. |
| %6f | 026490 | Доля секунды, как %.6f, но без начальной точки. |
| %9f | 026490000 | Доля секунды, как %.9f, но без начальной точки. |
| %R | 00:34 | Формат `час-минута`. То же, что %H:%M. |
| %T | 00:34:60 | Формат `час-минута-секунда`. То же, что %H:%M:%S. |
| %X | 00:34:60 | Представление местного времени (например, 23:13:48). |
| %r | 12:34:60 AM | 12-часовое местное время. (например, 23:11:04). Возвращает %X, если языковой стандарт не поддерживает 12-часовой формат времени. |
%S: учитываются дополнительные секунды, поэтому возможно 60.
%f, %.f:
%f и %.f — это совершенно разные спецификаторы форматирования.
%f подсчитывает количество наносекунд, прошедших с последней целой секунды, а %.f — доли секунды. Пример: 7 мкс форматируется как 7000 с %f и форматируется как .000007 с %.f.
| Спецификатор | Пример | Описание |
|---|---|---|
| %Z | ACST |
Название местного часового пояса. Пропускает все символы без пробелов во время парсинга. Идентичен %:z при форматировании7. |
| %z | +0930 | Смещение местного времени по отношению к UTC (при этом UTC равно +0000). |
| %:z | +09:30 | То же, что %z, но с двоеточием. |
| %::z | +09:30:00 | Смещение от местного времени до UTC в секундах. |
| %:::z | +09 | Смещение от местного времени до UTC без учета минут. |
| %#z | +09 | Только при парсинге: то же, что и %z, но позволяет использовать или не использовать минуты. |
%Z: поскольку встроенный модуль не знает часовых поясов за пределами их смещений, этот спецификатор печатает смещение только при использовании для форматирования. Аббревиатура часового пояса НЕ будет напечатана.
Смещение не будет заполнено из проанализированных данных и не будет проверено. Часовой пояс полностью игнорируется.
Невозможно надежно преобразовать аббревиатуру в смещение, например, CDT может означать либо центральное летнее время (Северная Америка), либо летнее время Китая.
| Спецификатор | Пример | Описание |
|---|---|---|
| %c | Sun Jul 8 00:34:60 2001 | Дата и время региона (например, четверг, 3 марта, 23:05:25 2005 г.). |
| %+ | 2001-07-08T00:34:60.026490+09:30 |
Формат даты и времени ISO 8601/RFC 33398. |
| %s | 994518299 |
Временная метка UNIX, количество секунд, прошедших с 01.01.1970 00:00 UTC9. |
%+: То же, что %Y-%m-%dT%H:%M:%S%.f%:z, т. е. 0, 3, 6 или 9 дробных цифр для секунд после двоеточия в смещении часового пояса.
Этот формат также поддерживает использование Z или UTC вместо %:z. Они эквивалентны +00:00.
Обратите внимание, что все T, Z и UTC анализируются без учета регистра.
Типичные реализации функции для преобразования даты и времени имеют разные (и зависящие от локали) форматы этого спецификатора. Лучше избегать этого спецификатора, если вы хотите точно контролировать результат.
%s: значение может быть отрицательным. Учитываются только невисокосные секунды.
| Спецификатор | Пример | Описание |
|---|---|---|
| %t | Знак табуляции (\t). | |
| %n | Знак перевода строки (\n). | |
| %% | Знак процента. |
Разделители
Разделители определяют правила, по которым будут прочитаны данные из файла узлом FlatFileReader. А также правила, по которым будет произведена запись в файл в результате работы узла FlatFileWriter.
В системе существует два типа разделителей:
- разделители полей fieldDelimiter;
- разделители записей recordDelimiter.
Разделители назначаются в редакторе метаданных и могут быть переопределены в редакторе узла.
По умолчанию, разделителем записей является символ перевода строки fieldDelimiter=\n, а разделителем полей – запятая recordDelimiter=,.
Для чтения файла такого вида: qwe|rty|uio;asd|fgh|jkl;zxc|vbn|mko в качестве разделителя полей следует задать вертикальную линию, а в качестве разделителя записей – точку с запятой: fieldDelimiter=|, recordDelimiter=;.
Если назначить метаданные для записи, установив разделитель полей fieldDelimiter=_, а разделитель записей не задать, то выходной файл будет выглядеть таким образом:
qwe_rty_uio
asd_fgh_jkl
zxc_vbn_mko
recordDelimiter при этом будет по умолчанию равен символу переноса строки.
Во FlatFileReader и FlatFileWriter можно переопределять fieldDelimiter и recordDelimiter в атрибутах узла. Тогда, даже если в метаданных указаны одни разделители – в узлах для чтения или записи могут быть указаны другие разделители, переопределённые значения будут приоритетными при выполнении алгоритма.
Непечатаемые разделители
Если нужно использовать любой непечатаемый разделитель, его можно записать как выражение. Например, вы можете ввести следующую последовательность символов в качестве разделителя записей в метаданных: RecordDelimeter=\u0014.
Такие выражения состоят из кода Unicode \uxxxx без кавычек. Обратите внимание, что каждый символ обратной косой черты «\», содержащийся во входных данных, на самом деле будет дублироваться при просмотре. Таким образом, вы увидите «\\» в своих метаданных.
Соединения с базами данных
Соединение с базой данных позволяет получить доступ к источникам данных в виде различных баз данных. При подключении к базе вы можете считывать данные из таблиц, выполнять SQL-запросы или вставлять записи в таблицы базы данных. Эти действия выполняются узлами, использующими соединение с базой данных.
Существует два способа доступа к базе данных:
- использование клиента на компьютере, который подключается к базе данных, расположенной на сервере, с помощью клиентской утилиты. Этот подход используется в массовых загрузчиках;
- использование драйвера ODBC. Для каждого подключения к базе данных требуется драйвер ODBC. Драйверы устанавливаются отдельно и не включены в OneBridge.
В OneBridge есть два вида подключения к базам - внутренний и внешний.
-
Внутренние соединения с базой данных являются частью графа, их описание можно увидеть в xml-представлении графа. При внутреннем типе соединения все параметры подключения задаются в файле и могут быть использованы только этим графом.
-
Внешним соединением могут пользоваться другие графы. Оно задаётся в отдельном файле с расширением
.conи в графе указывается только ссылка на файл соединения.
Создание подключения
Пример создания подключения приведён в главе Установка соединения с базой данных.
Чтобы создать подключение, щелкните правой кнопкой мыши Connections на панели Outline и выберите:
- New connection - для создания внутреннего подключения
- Link connection - для указания ссылки на внешний файл с описанием подключения.
Для внутреннего подключения к базе нужно указать имя и параметры соединения:
- Для внутреннего соединения нужно заполнить атрибут
URLпо шаблону, актуальному для конкретной базы. Шаблон указывается при выборе способа соединения в редакторе соединений. - Для внешнего соединения достаточно указать путь к файлу с конфигурацией в атрибуте
dbConfig.
Для передачи паролей стоит использовать защищенные (encrypted) параметры.
Значения параметров можно указать следующим образом в графе:
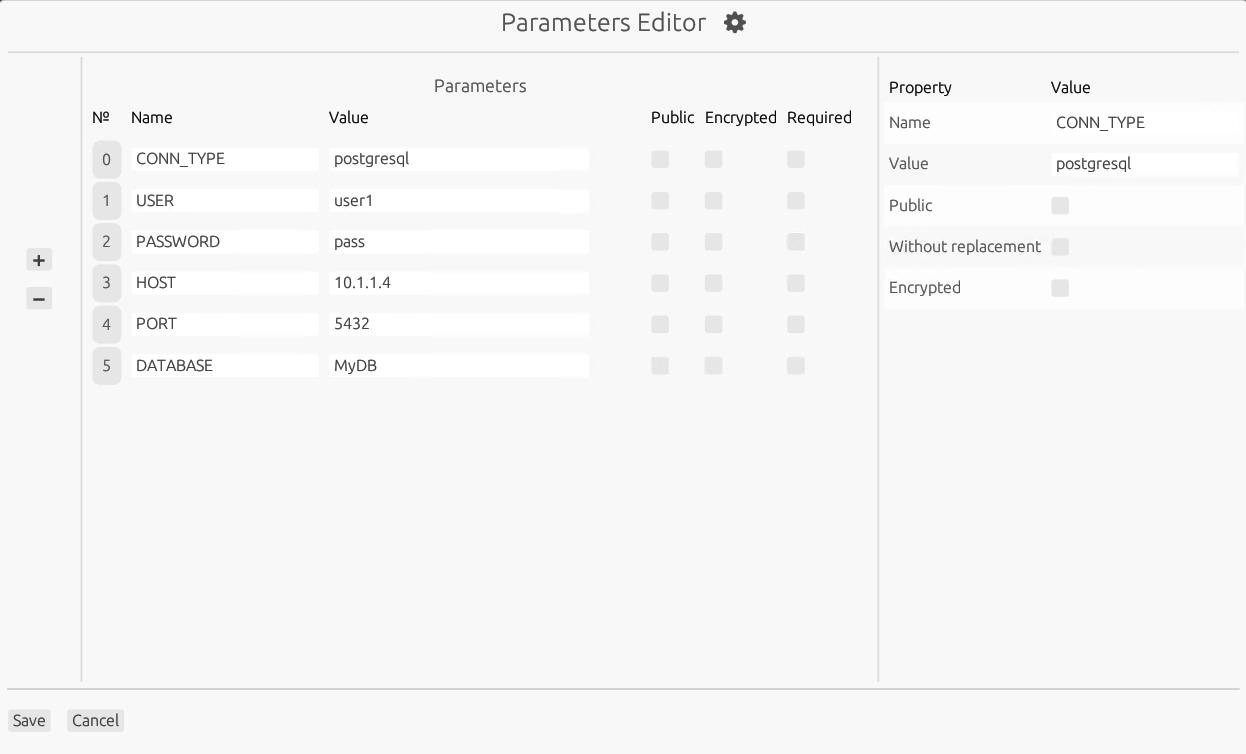
Либо в отдельном файле конфигурации соединения в виде XML:
<GraphParameters>
<!--тип соединения с базой данных-->
<GraphParameter name="CONN_TYPE" value="postgresql"/>
<!--имя пользователя в базе-->
<GraphParameter name="USER" value="user1"/>
<!--пароль пользователя в базе-->
<GraphParameter name="PASSWORD" value="pass"/>
<!--хост-->
<GraphParameter name="HOST" value="10.1.1.4"/>
<!--порт базы данных-->
<GraphParameter name="PORT" value="5432"/>
<!--имя базы данных-->
<GraphParameter name="DATABASE" value="MyDB"/>
</GraphParameters>
Типы соединения с базами данных
На данный момент подключены следующие нативные соединения с базами данных:
| Тип соединения в OneBridge | База | Шаблон строки подключения |
|---|---|---|
| postgres | PostgreSQL |
|
| oracle | Oracle |
|
| sqlserver | Microsoft SQL Server |
|
Подключение других баз возможно по запросу пользователя.
Через ODBC доступна работа со следующими базами:
- MySQL
- MariaDB
- PostgreSQL
- PostgresPRO
- Microsoft SQL Server
- Oracle Database
- IBM Db2
- Firebird
- SQLite
- Greenplum
- Vertica
- IBM Netezza
- Teradata
- SAP HANA
- Amazon Redshift
- Snowflake
- Apache Hive
- Apache Impala
- MonetDB
Для подключения через ODBC необходимо изменить строку подключения, добавив в начале строки odbc@. Например, для подключения к Firebird, строку подключения можно составить так: odbc@firebird:Driver={Firebird};User=SYSDBA;Password=2wsx2WSX;Database=sbar-dev-db03.sbar.local/3050:/opt/firebird/data/onebrige-dev.fdb.
Параметры
Параметры аналогичны константам, их можно определить один раз и использовать в различных местах графа для его настройки.
Значения параметров всегда конвертируются в строку. Каждое значение, номер, путь, имя файла, атрибут можно настроить или изменить с помощью параметров.
Основными преимуществами параметров являются возможность использовать шаблон для указания параметра и изменять его значение только в одном месте. Для подстановки значения параметра используйте шаблон "${PARAMETER_NAME}.
Параметры создаются с помощью редактора параметров или указываются в файле параметров, на который дается ссылка в графе.
Внутренние и внешние параметры
Параметры могут быть
- внутренними – указываются непосредственно в файле графа;
- внешними – указываются в отдельном файле и подключаются с помощью элемента
<GraphParameterFile>.
Внутренние параметры указываются в графе, в редакторе параметров. Они отображаются на панели Outline и их можно увидеть на вкладке Source. Внутренние параметры полезны для параметризации в рамках одного графа.
Внешние (общие) параметры хранятся вне графа в отдельном файле с расширением .prm в папке проекта. Использование внешних параметров подходят для параметров, используемых несколькими графами.
Чтобы подключить в граф внешние параметры, укажите путь к файлу в редакторе линкованных параметров в поле fileURL.
Защищенные параметры
Обычные параметры графа сохраняются либо в файлах .grf (внутренние параметры), либо в файлах .prm (внешние параметры). Это означает, что значения параметров вашего графа хранятся в обычных xml-файлах. Такое поведение абсолютно корректно для большинства вариантов использования параметров графа. Но иногда параметр графа может представлять конфиденциальную информацию, которую не следует сохранять в текстовом файле в файловой системе, например, пароль к базе данных. Для этой цели OneBridge предоставляет функцию безопасных параметров.
Для использования безопасных параметров установите чекбокс напротив значения параметра в редакторе параметров. После ввода значения оно будет отображаться в защищённом виде и чтобы изменить его, нужно будет ввести его заново и сохранить изменения. Расшифровка защищенного параметра выполняется автоматически во время выполнения графа.
Переменная
Переменная — это объект для хранения данных, связанный с каждым запуском графа в OneBridge. Его цель — обеспечить простое и типобезопасное хранение различных параметров, требуемых графом.
Он не ограничивается хранением только входных или выходных параметров, но также может использоваться как способ обмена данными между различными компонентами одного графа.
Когда граф загружается из своего определения в XML файле, переменная инициализируется на основе его определения в спецификации графа. Каждое значение инициализируется значением по умолчанию, если оно установлено, либо дефолтным для типа значением.
Между двумя последующими запусками любого графа переменная сбрасывается до исходных настроек или настроек по умолчанию, так что все изменения переменной после выполнения графа уничтожаются. По этой причине переменную нельзя использовать для передачи значений между разными прогонами одного и того же графа.
Создание переменной описано в главе Добавление переменной в описании Дизайнера.
Работа с переменной для передачи значений во внутренний граф при использовании узла ExecuteGraph описана в примере передачи параметров через переменную.
Преобразования
Преобразование — это фрагмент кода, который определяет, как входные данные преобразуются в выходные данные при прохождении через узл. Преобразование определяется в атрибуте "transform" или "normalize".
Определение преобразования задается вручную в графе с помощью внутреннего языка onelang.
Узлы, допускающие преобразования
Преобразователи можно использовать в таких узлах как HashJoin, MergeJoin, Map, Rollup. В этих узлах есть возможность задать алгоритм преобразования на своё усмотрение, в то время как для других узлов алгоритмы обработки данных чётко определены.
Возвращаемые значения преобразователей
Ниже в таблице представлены все возможные варианты возвращаемых преобразователями значений.
| Значение | Описание | Пример использования |
|---|---|---|
| ALL | В этом случае запись отправляется на все выходные порты. |
|
| SKIP | Сообщает что мы пропускаем данный выход (пропускаем цикл преобразования) |
|
| Любое целое число больше или равное 0 | Запись отправляется на выходной порт, номер которого равен этому возвращаемому значению. |
|
Методы преобразования данных
В некоторых узлах можно самостоятельно определить алгоритм обработки данных. К таким узлам относятся HashJoin, MergeJoin, HashJoin, Map, Rollup. Пользовательский алгоритм преобразования в этих узлах определяется в атрибуте с именем "transform" с помощью JavaScript:
function transform() {
//transform code
$out[0].field1 = $in[0].field1 * 3,14;
$out[0].field2 = $in[1].field2 + 'success_string';
return ALL;
}
В узлах, использующих функцию преобразования, можно применять методы для работы с записями, описанные в примере ниже:
<Node id="map" guiX="250" guiY="100" guiName="map" type="Map">
<Attr name="transform"><![CDATA[
$out[0].person = $in[0].name.toString() + "_" + $in[0].surname.toString();
$out[1].person = $in[0].name.toString().toUpperCase() + " " + $in[0].surname.toString().toUpperCase();
return ALL;
Param(param_name) возвращает значение param_name, но выдает ошибку unknown parameter 'param_name', если имя параметра не определено
0 => $out[0].obj_type = param("X"),
1 => $out[0].obj_type = param("RbISb"),
2 => $out[0].obj_type = format!("secure number is {}", param("FILE_PRM_NUM")),
Param_or(param_name, default_value) возвращает значение параметра или default_value, если параметра нет
3 => $out[0].obj_type = input.obj_type + " is not " + ¶m_or("XX", "goose") + "!",
Try_param(param_name) возвращает Some(value) (value является строкой) в случае,
если параметр есть, None, если параметра нет
4 => $out[0].obj_type = if let Some(obj_type) = try_param("X") { obj_type } else { "tuturu".to_string() },
Param_parse_or(param_name, default_value) возвращает преобразованное значение параметра, если он есть или default_value. Возвращает ошибку, если значение параметра не преобразуется к типу
5 | 6 => {
$out[0].y_coord = param_parse_or("X", 24);
$out[0].obj_type = param_parse_or("X", "tururu".to_string());
}
_ => $out[0].obj_type = input.obj_type,
index += 1;
return ALL;
Хеш-таблицы
Хеш-таблица (lookup table) — это структура данных, которая обеспечивает быстрый доступ к данным, хранящимся с использованием ключа. Она позволяет уменьшить частоту обращений к базе данных или файлам.
По умолчанию справочник позволяет хранить несколько записей с одинаковым значением ключа. Если для вашего кейса это некорректно, можно запретить хранить дублирующиеся значения, тогда будет сохранено последнее записанное значение.
Все записи такой таблицы находятся в памяти во время работы графа. Поэтому на сервере должно быть достаточно памяти для хранения всех записей из используемой таблицы. Содержимое таблицы можно записать в файл и сохранить в проекте, чтобы использовать её содержимое через время в других графах.
Заметка: В редакторе содержимого используйте обращение к справочнику через конструкцию
lookupTables.<tableName>.<lookupMethod>(<arguments>);в коде атрибутаtransformв узлах, разрешающих пользовательские преобразования, например, DATA_GENERATOR и MAP.
Создание справочника
Чтобы создать справочник, сначала нужно её определить в графе, а затем вставить в неё значения с помощью метода insert. В дизайнере для создания таблицы используйте панель Outline и редактор lookup таблиц, аналогично созданию метаданных и параметров. В веб интерфейсе OneBridge таблицу можно определить на странице Проекты в редакторе содержимого файла с помощью тега <LookupTable> и его атрибутов, описанных в таблице ниже.
Атрибуты справочника:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| name | да | Уникальное имя таблицы. | name="lt2" |
| file | нет | Путь до файла с данными таблицы. Если файла не существует, то он будет создан, но папка, в которой этот файл должен лежать, должна существовать. Если путь до файла не указан, то таблица будет жить только в памяти в течении работы графа. | file="onebridge-dev/projects/ready-check/lookupExample1" |
| metadata | да | Схема данных. | metadata="metadataName1" |
| key | да | Ключ формата fieldname1;fieldname2;...;fieldnameN. | key="person;date" |
| keyDuplicates | да | Чекбокс. Показывает, разрешается ли хранить в таблице больше одной записи с одинаковым значением ключа, по умолчанию keyDuplicates="true". | keyDuplicates="false" |
Методы справочника:
| Метод | Описание | Пример использования |
|---|---|---|
| get | Возвращает одну запись по ключу. Ключ это массив значений полей. |
|
| insert | Вставляет запись. |
|
| remove | Удаляет запись по ключу аналогично get. |
|
| numKeys | Возвращает количество уникальных ключей в таблице, аргументов нет. |
|
| clear | Очищает таблицу, аргументов нет. |
|
Правила использования справочника
Для корректной работы с таблицами такого типа, нужно соблюдать правила их использования:
-
В начале работы графа он считывает содержимое справочника и далее работает с ним в памяти. Запись в таблицу происходит в конце фазы, в которой производится обращение к таблице.
-
Необходимо избегать использования узлов для чтения таблиц и записи в таблицу в рамках одной фазы.
На данный момент алгоритм таков, что при попытке использовать сочетание узлов для чтения и записи в справочник в одной фазе результат работы графа будет некорректен.
В одной фазе можно:
- Использовать несколько LOOKUP_TABLE_READER для чтения из таблицы А.
- Использовать несколько LOOKUP_TABLE_READER для чтения из разных таблиц А, B, C.
- Использовать один LOOKUP_TABLE_WRITER для записи в таблицу А.
- Производить чтение и запись в таблицу А, но только внутри пользовательского кода узла, с помощью методов get и insert.
В одной фазе нельзя:
- Обращаться к таблице А из узлов для чтения и записи (LOOKUP_TABLE_READER и LOOKUP_TABLE_WRITER).
- Использовать несколько LOOKUP_TABLE_WRITER для записи в таблицу А.
- Обращаться к таблице А из разных узлов с пользовательским кодом.
Пример использования отдельных узлов для чтения и записи:
<Graph>
<Global>
<Metadata id="meta">
<Record>
<Field name="foo" type="integer" />
</Record>
</Metadata>
<LookupTable id="lookup_table1" key="foo" metadata="meta" name="lt1" file="1170_lt1" />
</Global>
<Phase number="0">
<!-- This shows how to insert records into lookup tables with built-in node -->
<Node id="datagen1" type="DATA_GENERATOR" recordsNumber="4">
<attr name="generate">
<![CDATA[
let i = 0;
function generate() {
$out[0].foo = i;
i++;
return ALL;
}
]]>
</attr>
</Node>
<Node id="ltwriter" type="LOOKUP_TABLE_WRITER" lookupTableName="lt1" />
<Edge id="edge1" fromNode="datagen1:0" toNode="ltwriter:0" metadata="meta" />
</Phase>
<Phase number="1">
<!-- This shows how to read all records from lookup tables with built-in node -->
<Node id="ltreader" type="LOOKUP_TABLE_READER" lookupTableName="lt1" />
<Node id="trash2" type="TRASH" debugOutput="false" />
<Edge id="edge2" fromNode="ltreader:0" toNode="trash2:0" metadata="meta" />
</Phase>
</Graph>
Пример обращения к таблице из узла с пользовательским кодом:
<Graph>
<Global>
<Metadata id="meta">
<Record>
<Field name="foo" type="integer" />
</Record>
</Metadata>
<LookupTable id="lookup_table1" key="foo" metadata="meta" name="lt1" file="1170_lt1" />
</Global>
<Phase number="0">
<!-- This shows how to insert and retrieve records to/from lookup tables in user code -->
<Node id="datagen" type="DATA_GENERATOR" recordsNumber="4" enabled="false">
<attr name="generate">
<![CDATA[
let i = 0;
function generate() {
let got = lookupTables.lt1.get([i]);
let foo = got ? got.foo : null;
$out[0].foo = foo;
lookupTables.lt1.insert({ foo: i + 1 });
i++;
return ALL;
}
]]>
</attr>
</Node>
<Node id="trash" type="TRASH" debugOutput="true" />
<Edge id="edge" fromNode="datagen:0" toNode="trash:0" metadata="meta" />
</Phase>
</Graph>
Объединение справочников
Объединение справочников возможно с помощью узлов MAP и NORMALIZER.
- MAP стоит использовать, если 1 запись мастер-потока объединяется с 1 записью слейв-потока.
- NORMALIZER стоит использовать, если записей для объединения на слейв-потоке больше, чем 1.
Пример объединения справочников с помощью MAP:
<Graph>
<Global>
<Metadata id="meta1">
<Record>
<Field name="n" type="integer"/>
<Field name="s" type="string"/>
</Record>
</Metadata>
<Metadata id="meta2">
<Record>
<Field name="n" type="integer"/>
<Field name="b" type="boolean"/>
</Record>
</Metadata>
<Metadata id="meta3">
<Record>
<Field name="num" type="integer"/>
<Field name="bool" type="boolean"/>
<Field name="str" type="string"/>
</Record>
</Metadata>
<LookupTable id="lookup_table1" key="n" metadata="meta1" name="lt1" file="1170_lt3_string" />
<LookupTable id="lookup_table2" key="n" metadata="meta2" name="lt2" file="1170_lt4_bool" />
<LookupTable id="lookup_table3" key="num" metadata="meta3" name="lt3" file="1170_lt5_joinmap" keyDuplicates="false"/>
</Global>
<Phase number="0">
<Node id="ltreader1" type="LOOKUP_TABLE_READER" lookupTableName="lt1" />
<Edge id="edge3" fromNode="ltreader1:0" toNode="map:0" metadata="meta1" />
</Phase>
<Phase number="1">
<Node id="map" type="MAP">
<attr name ="transform">
<![CDATA[
let i = 0;
function transform() {
let lt2 = lookupTables.lt2.get([i]);
let bool = lt2 ? lt2.b : null;
let str = lt2 ? lt2.s : null;
$out[0].num = $in[0].n;
$out[0].bool = bool;
$out[0].str = $in[0].s;
i++;
return ALL;
}
]]>
</attr>
</Node>
<Node id="trash2" type="TRASH" debugOutput="true" />
<Edge id="edge4" fromNode="map:0" toNode="trash2:0" metadata="meta3" />
</Phase>
</Graph>
Алгоритмы обработки данных
В этом разделе описаны запрограммированные узлы, которые пользователь может использовать для составления своего графа для обработки данных.
Каждый узел представляет собой готовый алгоритм обработки данных, например, EXT_SORT – это узел для сортировки данных.
Данные поступают в узел через входной порт, обрабатываются согласно алгоритму и выводятся через выходной порт. Входных и выходных портов у узла может быть разное количество. Например, у CONCAT может быть несколько входов, а у TRASH не бывает выходных портов.
Узлов в графе может быть сколько угодно, но обязательно должен присутствовать узел для чтения данных в начале алгоритма и для записи данных - в конце алгоритма. Между ними могут быть добавлены узлы для преобразования, объединения данных и другие.
Узлы в графе соединяются ребрами для передачи информации. Каждому ребру необходимо назначать метаданные для описания данных, передаваемых между узлами.
Подробное описание создания графа описано в главе Графы. Несколько примеров составления графов приведены в разделе Быстрый старт.
Типы данных метаданных
Каждое поле метаданных может иметь разный тип. Для метаданных в OneBridge определены следующие типы данных:
| Тип данных | Описание | Пример |
|---|---|---|
| boolean | Логическое значение | true |
| date | Дата | 01.01.2025 |
| integer | Целые числа | 42 |
| number | Дробные числа (числа с плавающей точкой) | 345.65 |
| decimal | Дробные числа (числа с плавающей точкой) | 345.65 |
| string | Строка хранит набор символов в кодировке UTF-8 | «это пример значения поля с типом string» |
Для чтения данных
Узлы для чтения (считыватели) могут считывать данные из входных файлов, получать их из подключенного дополнительного входного порта, читать из базы данных. Узел DATA_GENERATOR занимается генерацией данных и тоже относится к этой группе, поскольку является начальным узлом.
Различают следующие узлы для чтения:
- FLAT_FILE_READER - читает данные из плоского файла
- RAW_READER - читает данные из файлов во внутреннем формате OneBridge
- LOOKUP_TABLE_READER - читает данные из хеш-таблицы
- DATABASE_READER - читает данные из базы данных
- DATA_GENERATOR - генерирует данные по шаблону
- SPREADSHEET_READER - читает данные из файлов в форматах xlsx, xls
- INPUT_TABLE - преобразует данные из строки с разделителями в ytcrjkmrj pfgbctq
- CSV_READER - читает данные из файлов в формате CSV
FLAT_FILE_READER
FLAT_FILE_READER считывает данные из плоских файлов в формате CSV и TXT с разделителями, фиксированной длины или смешанных текстовых файлов. Удаленные файлы доступны для чтения через протоколы FTP и SFTP.
Порты FLAT_FILE_READER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | Для корректных записей | Любые |
| Output | 1 (в разработке) | нет | Для некорректных записей | Структура метаданных порта ошибок будет приведена в таблице ниже |
Атрибуты FLAT_FILE_READER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| fileURL | да | Путь к источнику данных (плоский файл) для чтения. Для обращения по FTP используйте шаблон ftp://username:password@hostname:port/path-to-file | ${READ_DIR}/in.txt |
| charset | нет | Кодировка файла, читаемого с помощью этого узла. | encoding="windows-1251" |
| dataPolicy | нет | Определяет обработку неправильно отформатированных или неверных данных. Может принимать значения "strict", "lenient" | dataPolicy="strict" по умолчанию |
| trim | нет | Указывает, следует ли удалять начальные и конечные пробелы из строк в момент прохождения данных через FLAT_FILE_READER. | trim="default" по умолчанию. Возможные значения: true, false, default/ |
|
quotedStrings | нет | Поля, содержащие специальные символы (запятая, новая строка или двойные кавычки), должны быть заключены в кавычки. В качестве символа кавычки принимаются только одинарные/двойные кавычки. Если установлено значение true, специальные символы не рассматриваются как разделители и удаляются при чтении компонентом. Пример: Чтобы прочитать входные данные "25"|"Джон", установите для параметра quotedStrings значение true и установите для символа кавычки значение quoteChar=""". В результате будут получены два поля: 25|Джон. | quotedStrings="false" по умолчанию |
|
quoteChar | нет | Символы, в которые будет заключено значение поля при quotedStrings="true". | quoteChar=""" |
|
fieldDelimiter | нет | Разделитель полей | fieldDelimiter="," |
|
recordDelimiter | нет | Разделитель записей | recordDelimiter="/n" |
Обрезание данных
- Входные строки обрабатываются в соответствии с типом данных поля следующим образом:
- Пробелы удаляются как из начала, так и из конца поля для типов данных
boolean,date,integer. - Входная строка остаётся полем, включающим начальные и конечные пробелы в случае типа данных
string.
- Если для атрибута trim установлено значение
true, все начальные и конечные пробельные символы удаляются. Поле, состоящее только из пробелов, преобразуется в нулевое значение (строка нулевой длины). Значениеfalseподразумевает сохранение всех начальных и конечных символов пробелов. Входная строка может содержать пробелы только если представляет строковый тип данных. В случае trim = "default", поведение зависит от типа обрабатываемых данных: для типа string, значение строки останется с начальными и конечными пробелами, если они были, для остальных типов - пробелы будут убраны. По умолчанию trim="default".
Пример. Чтение файла.
Например, нужно прочитать файл "customers.csv". Каждая запись в нем содержит три поля: "дата", "фамилия" и "имя", разделенные символом "|". Нужно считать этот файл для дальнейшей обработки в системе.
Данные в файле:
01.02.2011|Горилов|Алексей
29.12.2013|Нечаев|Илья
25.11.2016|Васькин|Николай
23.10.2019|Иванов|Григорий
19.09.2022|Горбунов|Евгений
Решение:
Для чтения простого файла используется узел FLAT_FILE_READER. В редакторе узла нужно задать значение атрибута fileURL="customers.csv".
Чтобы правильно прочитать записи, нужно описать входные метаданные. В редакторе метаданных задайте имя метаданным, например, "customers_data" и создайте поля "date", "last_name" и "first_name". Установите для них типы данных "date", "string" и "string" соответственно.
С помощью атрибута format="%Y-%m-%d" можно указать используемый формат даты для поля "date".
Данные читаемые с помощью узла FLAT_FILE_READER нужно обязательно отправить дальше. Если обработка данных не требуется, можно использовать узел TRASH для остановки потока данных.
Узлы FLAT_FILE_READER и TRASH нужно соединить ребром и присвоить этому ребру созданную мету "customers_data".
Данные из файла "customers.csv" будут считаны во внутреннюю память Onebridge:
| date | last_name | first_name |
|---|---|---|
| 01.02.2011 | Гончаров | Алексей |
| 29.12.2013 | Нечаев | Илья |
| 25.11.2016 | Васькин | Николай |
| 23.10.2019 | Серов | Григорий |
| 19.09.2022 | Глинка | Евгений |
RAW_READER
RAW_READER считывает данные, хранящиеся во внутренних файлах формата OneBridgeFile.
Порты RAW_READER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | нет | Для корректных входных записей | Поля с типом данных byte/cbyte |
| Output | 0 | да | Выходной порт для корректных данных | Любые |
| 1-n | нет | Выходной порт для корректных данных | Как на Output 0 |
Атрибуты RAW_READER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| fileURL | да | Атрибут, определяющий, какой файл данных OneBridgeFile будет считываться |
Пример. Чтение файла во внутреннем формате.
Чтобы прочитать файл ${DATAIN_DIR}/my-file.obf нужно заполнить атрибут fileURL.
| Атрибут | Значение |
|---|---|
| fileURL | ${DATAIN_DIR}/my-file.obf |
RAW_READER прочтёт все данные из этого файла.
LOOKUP_TABLE_READER
Узел LOOKUP_TABLE_READER считывает данные из хеш-таблицы (Lookup Table).
Порты LOOKUP_TABLE_READER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | для записываемых в хеш-таблицу записей. | Любые |
Атрибуты LOOKUP_TABLE_READER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| lookupTableName | да | Имя хеш-таблицы. | lookupTableName="lt1" |
DATABASE_READER
DATABASE_READER считывает данные из базы данных. Поддерживает подключение к СУБД PostgreSQL, Oracle, MySQL. Подробнее про подключение к базам данных можно прочитать в разделе Соединения с базами данных.

Порты DATABASE_READER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | Для корректных записей | Любые, но одинаковые на всех подключённых портах |
| 1-n | нет |
Атрибуты DATABASE_READER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| dbConnection | да | Идентификатор соединения с базой данных, которое будет использоваться для доступа к базе данных |
|
| sqlQuery | да | SQL-запрос к базе, определенный в графе. |
|
Пример. Чтение записей из баз данных.
С помощью DATABASE_READER нужно прочитать данные из разных баз и записать ответы в текстовые файлы.
Решение:
-
Для чтения данных понадобится три компонента DATABASE_READER и три компонента FLAT_FILE_WRITER - для записи данных в файлы.
-
Создам подключения к базам postgres, sqlserver через локального клиента и к firebird через odbc. Везде буду подключаться к схеме
onebridge, к таблицеmillion_row. -
Для создания соединений с базами нужно на панели Outline выбрать в контекстном меню элемента Connection пункт New connection - для создания нового подключения или Link connection - для вставки ссылки на уже описанное в отдельном файле подключение. В редакторе новых соединений выбрать тип подключения и заполнить атрибут
URLзначениями параметров, необходимых для подключения.
Connection для postgres:
URL = "postgres://user:password@host:port/database;"
Connection для sqlserver:
URL = "sqlserver:server=sbar-dev-db02.sbar.local,port;user=username;password=password;"
Connection для firebird:
URL = "odbc:Driver={Firebird};User=username;Password=password;Database=sbar-dev-db03.sbar.local/3050:/opt/firebird/data/onebrige-dev.fdb;Charset=;Role=;ReadOnly=No;NoWait=No;"
- SQL-запрос для чтения данных из базы будет везде примерно одинаковый, его нужно вставить в атрибут sqlQuery внутри редактора каждого из узлов DATABASE_READER:
select BigIntColumn,
BooleanColumn,
CharColumn,
DateColumn,
from onebridge.million_row
order by BigIntColumn
limit 10
Этот запрос считает значения полей BigIntColumn, BooleanColumn, CharColumn, DateColumn из таблицы million_row во внутреннюю память системы.
- С помощью метаданных, назначенных ребрам графа, данные будут переданы в FLAT_FILE_WRITER`ы, которые запишут их в текстовые файлы.
DATA_GENERATOR
DATA_GENERATOR генерирует данные по шаблону, вместо чтения данных из файла, базы данных или любого другого источника данных. Этот узел может отправлять разные записи на разные выходные порты, используя возвращаемые значения функции generate.
Порты DATA_GENERATOR:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | Для сгенерированных записей | Любые |
| 1-n | нет |
Метаданные на выходных портах могут отличаться.
Атрибуты DATA_GENERATOR:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| generate | да | Определение способа создания записей, записанное в графе на языке преобразований |
|
| recordsNumber | нет | Количество записей, которые необходимо создать. Отрицательное значение позволяет создать количество записей, ограниченное кодом в generate. | recordsNumber="1" |
SPREADSHEET_READER
SPREADSHEET_READER считывает данные с указанных листов файлов формата .xls или .xlsx. Позволяет указывать маппинг данных из таблицы и метаданных OneBridge. Удаленные файлы доступны для чтения через протоколы FTP и SFTP.
Должен иметь один выходной порт для успешно считанных записей.
Порты SPREADSHEET_READER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | Для успешно считанных записей | Любые |
| 1 | не | Для некорректных считанных записей |
Атрибуты SPREADSHEET_READER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| fileURL | да | Путь к файлу проекта, из которого читать данные. Для обращения по FTP используйте шаблон ftp://username:password@hostname:port/path-to-file | fileURL="testFile.txt" |
| sheet | нет | Название или номер листа в excel документе. Нумерация страниц начинается с 0. Можно перечислить в атрибуте sheet через запятую либо указать множество листов с помощью «*», чтобы все листы читались по порядку с использованием одного маппинга для всех. | sheet="Sheet1" |
| mapping | нет | Сопоставляет ячейки электронной таблицы с полями OneBridge. |
|
| password | нет | Пароль для расшифровки файла,если он запаролен. Актально только для формата xlsx. | password="faihfi4t9(&Yhflaieg)" |
Пример. Сопоставление полей по порядку.
Нужно прочитать из файла таблицы с количеством проданных некой компанией товаров за первый квартал года. Таблицы имеют одинаковую структуру: название товара, январь, февраль, март. Компания международная. Каждый партнер может использовать свой язык, поэтому вы не можете сопоставить поля по имени.
лист 1:
| Product | January | February | March |
|---|---|---|---|
| T1 | 620 | 600 | 700 |
| T2 | 150 | 150 | 100 |
лист 2:
| Товар | Январь | Февраль | Март |
|---|---|---|---|
| T1 | 500 | 400 | 600 |
| T2 | 300 | 400 | 500 |
Решение:
Укажите атрибуты: fileURL, sheet, mapping.
Заполните маппинг следующим образом:
<![CDATA[<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<mapping>
<globalAttributes>
<orientation>VERTICAL</orientation>
<step>1</step>
<writeHeader>true</writeHeader>
</globalAttributes>
<defaultSkip>1</defaultSkip>
<headerGroups>
<headerGroup skip="1">
<autoMappingType>ORDER</autoMappingType>
<headerRanges>
<headerRange begin="A1"/>
<headerRange begin="B1"/>
<headerRange begin="C1"/>
<headerRange begin="D1"/>
</headerRanges>
</headerGroup>
</headerGroups>
</mapping>
]]>
INPUT_TABLE
Узел INPUT_TABLE предназначен для загрузки в систему данных CSV-формата в виде строки с разделителями. Имеет единственный атрибут, в который помещается строка с перечислением значений полей.
Порты INPUT_TABLE:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | Для корректных записей | Любые |
Атрибуты INPUT_TABLE:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| data | да | Табличные данные в виде строки с разделителями | field1, field2, field3 |
CSV_READER
CSV_READER считывает данные из плоских файлов в формате CSV. Этот узел похож на FLAT_FILE_READER, но работает только с CSV-файлами.
Порты CSV_READER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | Для корректных записей | Любые |
Атрибуты CSV_READER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| fileURL | да | Путь к источнику данных (плоский файл) для чтения. Для обращения по FTP используйте шаблон ftp://username:password@hostname:port/path-to-file | ${READ_DIR}/in.txt |
| charset | нет | Кодировка файла, читаемого с помощью этого узла. | encoding="windows-1251" |
| dataPolicy | нет | Определяет обработку неправильно отформатированных или неверных данных. Может принимать значения "strict", "lenient" | dataPolicy="strict" по умолчанию |
| trim | нет | Указывает, следует ли удалять начальные и конечные пробелы из строк в момент прохождения данных через CSV_READER. | trim="default" по умолчанию. Возможные значения: true, false, default |
| header | нет | Указывает, следует ли удалять заголовок файла. | header="true" по умолчанию. Возможные значения: true, false |
|
quotedStrings | нет | Поля, содержащие специальные символы (запятая, новая строка или двойные кавычки), должны быть заключены в кавычки. В качестве символа кавычки принимаются только одинарные/двойные кавычки. Если установлено значение true, специальные символы не рассматриваются как разделители и удаляются при чтении компонентом. Пример: Чтобы прочитать входные данные "25"|"Джон", установите для параметра quotedStrings значение true и установите для символа кавычки значение quoteChar=""". В результате будут получены два поля: 25|Джон. | quotedStrings="false" по умолчанию |
|
quoteChar | нет | Символы, в которые будет заключено значение поля при quotedStrings="true". | quoteChar=""" |
|
fieldDelimiter | нет | Разделитель полей | fieldDelimiter="," |
|
recordDelimiter | нет | Разделитель записей | recordDelimiter="/n" |
Обрезание данных
- Входные строки обрабатываются в соответствии с типом данных поля следующим образом:
- Пробелы удаляются как из начала, так и из конца поля для типов данных
boolean,date,integer. - Входная строка остаётся полем, включающим начальные и конечные пробелы в случае типа данных
string.
- Если для атрибута trim установлено значение
true, все начальные и конечные пробельные символы удаляются. Поле, состоящее только из пробелов, преобразуется в нулевое значение (строка нулевой длины). Значениеfalseподразумевает сохранение всех начальных и конечных символов пробелов. Входная строка может содержать пробелы только если представляет строковый тип данных. В случае trim = "default", поведение зависит от типа обрабатываемых данных: для типа string, значение строки останется с начальными и конечными пробелами, если они были, для остальных типов - пробелы будут убраны. По умолчанию trim="default".
Для записи данных
Узлы для записи данных могут записывать данные в локальные выходные файлы, отправлять их через подключенный дополнительный выходной порт или вставлять в таблицу базы данных.
Узлы для записи — это компоненты графа, которые выполняются последними, поэтому они не имеют выходных портов.
Каждый узел для записи должен иметь хотя бы один входной порт, через который данные поступают в этот компонент графа.
Узлы для записи могут либо добавлять данные в существующий файл или таблицу базы данных, либо заменять существующее содержимое новым. Для этой цели узлы для записи в файлы имеют атрибут Append. По умолчанию для этого атрибута установлено значение false. Это означает, что данные необходимо заменить, а не добавить к имеющимся.
Данные можно записать в один и тот же файл или базу данных несколько раз в течение работы графа с помощью нескольких узлов для записи. Для этого разместите узлы для записи в разных фазах графа.
- FLAT_FILE_WRITER - запись в файл
- RAW_WRITER - записывает данные в файл во внутреннем формате OneBridge
- LOOKUP_TABLE_WRITER - записывает данные в справочник
- DATABASE_WRITER - запись в базу данных
- POSTGRESQL_DATA_WRITER - запись в базу данных Postgres с помощью утилиты
- TRASH - прерывание потока данных
Общие свойства узлов для записи
Поддерживаемые форматы URL-адресов для записывающих узлов
Запись в локальные файлы
/path/filename.out- записывает указанный файл на диск.
Просмотр записанных данных
После создания выходного файла вы можете просмотреть данные в нём в web-приложении на странице проектов на вкладке "Содержимое файла".
Добавление или перезапись
Если целевой файл существует, есть два варианта:
- существующий файл можно заменить;
- записи могут быть добавлены к существующему содержимому.
Добавление или замена настраивается с помощью атрибута Append.
- Если для параметра
Appendустановлено значение true, записи добавляются в файл. - Если для параметра
Appendустановлено значение false, файл перезаписывается.Append=falseпо умолчанию.
Функция Append доступна в следующих узлах для записи: FLAT_FILE_WRITER, TRASH.
FLAT_FILE_WRITER
FLAT_FILE_WRITER записывает данные в плоские файлы. Удаленные файлы доступны для записи через протоколы FTP или SFTP.
Порты FLAT_FILE_WRITER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входящего потока записей | Любые |
Атрибуты FLAT_FILE_WRITER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| fileURL | да | Путь к файлу, в который должен быть записан результирующий набор данных. Для обращения по FTP используйте шаблон ftp://username:password@hostname:port/path-to-file | ${WRITE_DIR}/out.txt |
| charset | нет | Кодировка файла, читаемого с помощью этого узла. charset="UTF-8" по умолчанию | encoding="windows-1251" |
| append | нет | Если записи печатаются в существующий непустой файл, они по умолчанию заменяют более старые (при append="false"). Если установлено значение "true", новые записи добавляются в конец существующего содержимого выходного файла(ов). | append="false" по умолчанию |
|
quotedStrings | нет | При quotedStrings="true" все поля заключаются в кавычки. | quotedStrings="true" |
|
quoteChar | нет | Символы, в которые будет заключено значение поля при quotedStrings="true". | quoteChar=""" |
|
fieldDelimiter | нет | Разделитель полей | fieldDelimiter="," |
|
recordDelimiter | нет | Разделитель записей | recordDelimiter="/n" |
Пример. Запись данных в файл.
Например, нужно записать обработанные системой данные в файл, используя разделитель «|».
Данные в системе:
| date | last_name | first_name |
|---|---|---|
| 01.02.2011 | Гончаров | Алексей |
| 29.12.2013 | Нечаев | Илья |
| 25.11.2016 | Васькин | Николай |
| 23.10.2019 | Серов | Григорий |
| 19.09.2022 | Глинка | Евгений |
Данные, записанные узлом FLAT_FILE_WRITER в файл:
01.02.2011|Горилов|Алексей
29.12.2013|Нечаев|Илья
25.11.2016|Васькин|Николай
23.10.2019|Иванов|Григорий
19.09.2022|Горбунов|Евгений
RAW_WRITER
RAW_WRITER записывает обрабатываемые данные во внутренние файлы формата OneBridgeFile.
Порты RAW_WRITER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для полученных записей данных | Любые |
| Output | 0 | нет | Для записи на выходной порт | с типом данных byte/cbyte |
Атрибуты RAW_WRITER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| fileURL | да | Атрибут, указывающий, куда будут записаны полученные данные. | fileURL="${DATATMP_DIR}/bl/${trgFilePath}/loadHub/${tableName}.sql" |
| append | По умолчанию новые записи перезаписывают старые. Если установлено значение true, новые записи добавляются к старым записям, хранящимся в выходном файле(ах). append="false" по умолчанию | append="true" |
Пример. Запись данных во внутренний формат.
Чтобы записать данные в файл ${DATAOUT_DIR}/my-file.obf нужно заполнить атрибут fileURL.
| Атрибут | Значение |
|---|---|
| fileURL | ${DATAOUT_DIR}/my-file.obf |
RAW_WRITER запишет данные в указанный файл.
Пример. Добавление к существующему файлу.
Добавить записи каждого запуска графа в существующий файл ${DATAOUT_DIR}/my-file.obf. Для этого нужно заполнить атрибут fileURL и append.
| Атрибут | Значение |
|---|---|
| fileURL | ${DATAOUT_DIR}/my-file.obf |
| append | true |
LOOKUP_TABLE_WRITER
Узел LOOKUP_TABLE_WRITER записывает данные в справочник (Lookup Table).
Порты LOOKUP_TABLE_WRITER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для записываемых в справочник записей. | Любые |
Атрибуты LOOKUP_TABLE_WRITER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| lookupTableName | да | Имя справочника. | lookupTableName="lt2" |
DATABASE_WRITER
DATABASE_WRITER предназначен для выгрузки обработанной информации в базу данных и совершения изменений в базе. Позволяет выполнять несколько SQL-запросов в рамках одной транзакции, для этого выражения в атрибуте sqlQuery разделяются точкой с запятой.
Поддерживает подключение к базам MySQL, Oracle, PostgreSQL.
Подробнее про подключение к базам данных можно прочитать в разделе Соединения с базами данных.
Порты DATABASE_WRITER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Записи для загрузки в базу данных | Любые |
| Output | 0 | нет | Для отклонённых записей | Такие же, как на входном порте |
| Output | 1 | нет | Для возвращаемых значений | Любые |
Атрибуты DATABASE_WRITER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| dbConnection | да | Параметры соединения с базой данных. В список параметров для подключения могут входить: database, user, password, host, port. Параметры можно указать в атрибуте конкретного узла либо в глобальных параметрах графа. |
|
| sqlQuery | нет |
Запрос к базе. Обращение по имени поля производится с помощью специального символа |
|
| batchMode | нет | Определяет режим записи в таблицу. Записывать сразу по несколько записей – true, по одной – false. Пакетный режим ускоряет загрузку данных в базу. | batchMode="true" |
| batchSize | нет | Количество записей, которое можно отправить в базу данных за одно пакетное обновление (в одном sql скрипте). Актуально если batchMode="true". | batchSize="5" |
| commit | нет | Определяет, после обработки скольких записей (без ошибок) выполняется коммит (фиксация записей в базе данных). Возможные значения -1,0,N:
| commit="10" |
| maxErrorCount | нет | Максимальное количество разрешенных ошибок. При превышении этого числа ошибок граф выходит из строя. По умолчанию ошибки не допускаются. Если установлено значение -1, все ошибки разрешены. | maxErrorCount="0" |
| actionOnError | нет | Действие при превышении допустимого количества ошибок maxErrorCount. Если установлено значение ROLLBACK, фиксация текущего пакета не выполняется (актуально только для Oracle). Commit для Postgres делает тоже, что и Rollback, MsSql автоматически делает Rollback. | actionOnError="commit" |
Пакетный режим и размер пакета
Пакетный режим ускоряет загрузку данных в базу данных.
Оператор возврата недоступен в пакетном режиме.
Помните, что некоторые базы данных возвращают как отклоненные больше записей, чем реально отклонено. Эти базы данных возвращают даже те записи, которые были успешно загружены в базу данных, и отправляют их через выходной порт 0 (если он подключен).
- batchMode
- batchSize
Пример. Загрузка записей из OneBridge в SQLite.
Нужно загрузить данные из OneBridge в базу данных SQLite в таблицу Tracking, в поля client, items, total.
Данные в системе:
| customer | product | amount_of_purch |
|---|---|---|
| JazzveCoffee | Coffea arabica | 19513 |
| Arabica Legasy LLC | Coffea canephora | 12735 |
| BlackBean Group | Excelsa | 34010 |
Решение:
Создайте соединение с базой данных через редактор соединений.
URL="${CONN_TYPE}://${DB_01_USR}:${DB_01_PWD}@${DB_01_HOST}:${DB_01_PORT}/${DB_01_DATABASE}"
Выберите имя соединения из выпадающего списка в редакторе узла DATABASE_WRITER в атрибуте dbConnection:
dbConnection="conn_name"
Пропишите в атрибут sqlQuery следующий SQL-запрос:
INSERT INTO public."Tracking" ("client", "items", "total")
VALUES ($customer, $product, $amount_of_purch)
Чтобы вставить значения полей из системы, нужно указать название полей из метаданных после знака «$».
Данные будут выгружены в базу данных, соответствующую указанному типу соединения, в таблицу Tracking.
POSTGRESQL_DATA_WRITER
POSTGRESQL_DATA_WRITER массовый загрузчик, подходящий для загрузки большого количества записей в базу данных PostgreSQL. Считывает данные через входной порт. Использует специальную утилиту Copy, которая позволяет загружать данные очень быстро. Для остальных случаев лучше использовать DATABASE_WRITER, для которого не требуется использование специальной утилиты.
Порты POSTGRESQL_DATA_WRITER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 1-n | да | Записи для загрузки в базу данных | Любые |
Атрибуты POSTGRESQL_DATA_WRITER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| dbConnection | да | Параметры соединения с базой данных. В список параметров для подключения могут входить: database, user, password, host, port. Параметры можно указать в атрибуте конкретного узла либо в глобальных параметрах графа. |
|
| table | да | Имя таблицы, в которую производится запись |
|
| parameters | нет | Параметры, которые могут использоваться в качестве параметров утилитой psql или оператором \copy. Указывается последовательность ключ=значение, отделенные друг от друга точкой с запятой, двоеточием или вертикальной чертой. Если значение какого-либо параметра содержит точку с запятой, двоеточие или вертикальную черту, такое значение должно быть заключено в двойные кавычки. Сейчас доступны к указанию columns |
|
Пример.
Необходимо загрузить записи с метаданными «Product» (string), «Amount» (int), «date» (date) и «Price» (float) в таблицу Products в базу данных postgres с именем пользователя user001.
- Cоздать подключение CONN
URL="postgres://user001:pass123@localhost:5432/postgres"
- Настроить узел, передающий данные.
- Создать метаданные.
- Заполнить атрибуты узла POSTGRESQL_DATA_WRITER
dbConnection="CONN"
table="Products"
parameters="columns=${COLUMNS}"
После запуска графа данные будут внесены в базу:

TRASH
TRASH используется для прерывания потока данных, когда не нужно передавать данные дальше. Узел не имеет выходных портов.
TRASH прерывает поток данных.
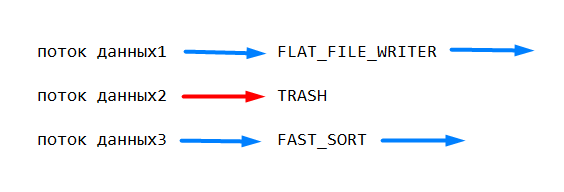
Порты TRASH:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 1-n | нет | Для входящего потока записей. | Любые |
Атрибуты TRASH:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| debugOutput | нет | По умолчанию все записи удаляются. Если установлено значение true, все записи записываются в лог на вкладку «Консоль». Этот режим поддерживается при подключении любого количества входных портов. | debugOutput="true" |
Для преобразования данных
Преобразователи — это промежуточные узлы графа. Преобразователи получают данные через подключенные входные порты, обрабатывают их указанным пользователем способом и отправляют через подключенные выходные порты в следующие узлы.
Список узлов-преобразователей данных:
- EXT_SORT - сортирует записи.
- FILTER - фильтрует записи.
- GATHER - собирает записи из разных потоков в один. Порядок выходных записей непредсказуем.
- SIMPLE_COPY - копирует записи.
- MAP - пользовательский алгоритм обработки.
- ROLLUP - создает записи с помощью преобразования.
- CONCATENATE - объединяет записи.
- NORMALIZER - создает одну или несколько выходных записей из каждой входной записи.
- AGGREGATE - вычисляет статистическую информацию о входных данных.
- DEDUP - устраняет копии по ключу.
EXT_SORT
EXT_SORT сортирует полученные записи в соответствии с указанным ключом сортировки и копирует каждую из них на все подключенные выходные порты. Позволяет использовать несколько параллельных потоков для сортировки больших данных.
Порты EXT_SORT:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входящего потока записей | Одинаковые метаданные на входных и выходных портах |
| Output | 0 | да | Для отсортированных записей | |
| 1-n | нет | Для отсортированных записей |
Атрибуты EXT_SORT:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| sortKey | да | Список полей метаданных, по которым производится сортировка и в скобках - порядок сортировки. Наивысший приоритет сортировки имеет первое поле в последовательности. Порядок сортировки выражается отдельно для каждого ключевого поля. По возрастанию - `a` (от англ. ascending - восходящий) или по убыванию - `d` (от англ. descending - нисходящий). Порядок сортировки по умолчанию — `a` — по возрастанию. |
|
| sortInMemory | нет |
При sortInMemory="true" выполняется внутренняя сортировка. По умолчанию | sortInMemory="true" |
| runSize | нет |
Количество записей, сортируемых одновременно в памяти; размер одного буфера чтения. По умолчанию | runSize="15456" |
Пример. Сортировка данных.
Входные записи содержат имена файлов и их размер. Нужно отсортировать файлы по размеру, начиная с самого большого (descending – по убыванию). Метаданные содержат поля «FileName», «FileSize».
Входящие записи:
| FileName | FileSize |
|---|---|
| file.txt | 2048 |
| file.docx | 1048576 |
| file.xml | 65536 |
Решение:
Ключ сортировки: sortKey="FileSize(d)"
Исходящие записи:
| FileName | FileSize |
|---|---|
| file.docx | 1048576 |
| file.xml | 65536 |
| file.txt | 2048 |
FILTER
FILTER фильтрует входные данные в соответствии с логическим выражением. Отправляет все записи, соответствующие выражению фильтра, в первый выходной порт и все отклоненные записи во второй выходной порт.
Порты FILTER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входящего потока записей | Одинаковые метаданные на входных и выходных портах |
| Output | 0 | да | Для отфильтрованных записей | |
| 1 | нет | Для отклонённых записей |
Атрибуты FILTER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| filterExpression | да | Выражение, по которому фильтруются записи. |
|
Пример. Фильтрация данных.
Входные данные содержат данные о продуктах, проданных в прошлом году. Нужно узнать данные только по карандашам. Метаданные содержат поля Product, Count и Location.
Входящие записи:
| Product | Count | Location |
|---|---|---|
| карандаш | 1553 | екатеринбург |
| бумага | 6475 | новгород |
| ручка | 598 | владикавказ |
| карандаш | 177 | омск |
| карандаш | 239 | волгоград |
| бумага | 19 | казань |
| ластик | 53 | ростов |
Решение:
Выражение для фильтрации: $in[0].product == "карандаш"
Исходящие записи:
| Product | Count | Location |
|---|---|---|
| карандаш | 1553 | екатеринбург |
| карандаш | 177 | омск |
| карандаш | 239 | волгоград |
GATHER
GATHER собирает записи со всех входящих портов и отправляет в порядке получения на все выходные порты. Порядок получения записей не зависит от порядка входных портов. Этот узел соблюдает порядок записей в потоках, но не соблюдает порядок потоков. На выходе получается список записей в непредсказуемом порядке. Порядок записей на разных выходах будет одинаков. Узел не имеет атрибутов.
Порты GATHER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входящего потока записей | Одинаковые метаданные на входных и выходных портах |
| 1-n | нет | Для входящего потока записей | ||
| Output | 0 | да | Для отфильтрованных записей | |
| 1-n | нет | Для отклонённых записей |
Пример. Сбор записей с нескольких входных портов.
Нужно собрать записи с нескольких потоков. Потоки содержат одно поле - "id".
Входящие записи:
Решение:
-
Создать метаданные:
имя="id", тип="integer" -
Поместить компоненты, передающие данные и GATHER на рабочую область.
-
Соединить узлы ребрами и назначить рёбрам метаданные.
-
После запуска графа записи со всех портов будут объединены:
SIMPLE_COPY
SIMPLE_COPY получает записи через один входной порт и копирует каждую из них на все подключенные выходные порты. Узел не имеет атрибутов.
Порты SIMPLE_COPY:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входящего потока записей | Любые |
| Output | 0 | да | Для скопированных записей | Как у Input 0 |
| 1-n | нет | Как у Output 0 |
Пример. Копирование данных.
Нужно скопировать записи с метаданными «carID» и «mark» в три потока.
Входящие записи:
порт 0:
| carID | mark |
|---|---|
| 145 | mercedes |
| 856 | toyota |
| 245 | chevrolet |
Решение:
Для копирования в несколько потоков нужно подключить SIMPLE_COPY несколько выходных портов. Записи на всех выходных портах будут идти в одинаковом порядке.
Исходящие записи:
порт 0:
| carID | mark |
|---|---|
| 145 | mercedes |
| 856 | toyota |
| 245 | chevrolet |
порт 1:
| carID | mark |
|---|---|
| 145 | mercedes |
| 856 | toyota |
| 245 | chevrolet |
порт 2:
| carID | mark |
|---|---|
| 145 | mercedes |
| 856 | toyota |
| 245 | chevrolet |
MAP
MAP позволяет написать пользовательский алгоритм обработки данных, используя внутренний язык системы. Можно по своему усмотрению трансформировать данные между входным и выходными портами, если предложенных узлов не хватает для выполнения необходимых преобразований данных.
Имеет единственный входной порт и как минимум один выходной. Может отправлять разные записи в разные выходные порты или даже отправлять одну и ту же запись на несколько выходных портов. Работает только с одним элементом, сохраняет порядок записей.
С помощью MAP можно:
- удалить ненужные значения полей
- проверить записи с помощью функций или регулярных выражений
- создать новые или изменить существующие поля
- преобразовать типы данных
Порты MAP:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входящего потока записей | Любые |
| Output | 0 | да | Для преобразованных записей | |
| 1-n | нет |
Атрибуты MAP:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| transform | да | Алгоритм преобразования данных |
|
Пример. Обработка данных с помощью MAP.
Нужно получить произведение и сумму полученных на вход данных и отправить результаты на разные выходные порты. Входные метаданные содержат поля a, b. Нужно отправить результат перемножения a*b на первый порт, а результат сложения a+b на второй порт.
Входящие записи:
| a | b |
|---|---|
| 5 | 6 |
| 2 | 4 |
| 1 | 2 |
Решение:
Преобразование:
function transform() {
var res_mul = $in[0].a * $in[0].b;
var res_add = $in[0].a + $in[0].b;
$out[0].res_mul = res_mul;
$out[1].res_add = res_add;
return ALL;
}
Исходящие записи:
порт 0:
| multiplied |
|---|
| 30 |
| 6 |
| 2 |
порт 1:
| added |
|---|
| 11 |
| 5 |
| 3 |
ROLLUP
ROLLUP создает одну или несколько выходных записей из одной или нескольких входных записей. Может отправлять разные записи на разные выходные порты, указанные пользователем. Записи должны быть отсортированы перед подачей в этот узел.
Метаданные на разных выходных портах могут различаться.
Порты ROLLUP:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входных записей | любые |
| Output | 0 | да | Для выходных записей | |
| 1-N | нет |
Атрибуты ROLLUP:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| groupKeyFields | да | Ключ, по которому записи считаются включенными в одну группу. Выражается в виде последовательности имен отдельных входных полей, разделенных друг от друга символом «#». | name; salary |
| groupAccumulatorMetadataId | дa | Идентификатор метаданных, которые служат для создания групповых аккумуляторов. | metadataName |
| transform | да | Алгоритм обработки данных. Функции для преобразования на узле ROLLUP описаны в таблице ниже. |
|
Схема работы узла ROLLUP

Функции узла ROLLUP
Когда приходит первая запись, срабатывает initGroup(groupAccumulatorMetadataId). Он инициализирует группу записей, объединенных групповым акумулятором groupAccumulatorMetadataId.
| Параметр | Значение |
|---|---|
| Обязательный | Да |
| Входные параметры |
|
| Возвращает | void |
| Вызов | Вызывается по одному разу для первой входной записи каждой группы. Вызывается перед updateGroup(groupAccumulatorMetadataId). |
| Описание | Обновляет информацию для конкретной группы. |
| Пример |
|
Далее для каждой записи, которая соответствует этой группе, вызывается updateGroup(groupAccumulatorMetadataId).
| Параметр | Значение |
|---|---|
| Обязательный | Да |
| Входные параметры |
|
| Возвращает |
если true, то вызывается если false, то граф завершится с ошибкой. |
| Вызов |
Вызывается многократно (по одному разу для каждой входной записи группы, включая первую и последнюю запись). Вызывается после того, как функция |
| Описание | Инициализирует информацию для конкретной группы. |
| Пример |
|
Если updateGroup вернул true, то для каждой записи еще вызывается updateTransform(counter, groupAccumulatorMetadataId) столько раз сколько указан counter внутри, пока не вернётся SKIP.
| Параметр | Значение |
|---|---|
| Обязательный | Да |
| Входные параметры |
Целочисленный счетчик (начинается с 0, указывает количество созданных записей. Должен быть завершен, как показано в примере ниже. Вызовы функций заканчиваются, когда возвращается Если |
| Возвращает | целочисленные значения |
| Вызов |
Вызывается неоднократно, как указано пользователем. Вызывается после того, как |
| Описание |
Создает выходные записи на основе информации об отдельных записях. Если |
| Пример |
|
Когда группа закончилась, отрабатывает finishGroup(groupAccumulatorMetadataId).
| Параметр | Значение |
|---|---|
| Обязательный | Да |
| Входные параметры |
Метаданные, указанные пользователем. Если |
| Возвращает |
если true, то вызывается если false, то граф завершится с ошибкой. |
| Вызов |
Вызывается повторно, один раз для последней входной записи каждой группы. Вызывается после того, как |
| Описание |
Если |
| Пример |
|
Затем выполняется transform(counter, groupAccumulatorMetadataId).
| Параметр | Значение |
|---|---|
| Обязательный | Да |
| Входные параметры |
целочисленный счетчик (начинается с 0, указывает количество созданных записей. должен быть завершен, как показано в примере ниже. Вызовы функций заканчиваются, когда возвращается SKIP.) Если |
| Возвращает | целочисленные значения |
| Вызов |
Вызывается неоднократно, как указано пользователем. Вызывается после того, как |
| Описание |
Создает выходные записи на основе всех записей всей группы. Если функция |
| Пример |
|
Входные записи или поля
Входные записи или поля доступны в функциях initGroup(), updateGroup(), finishGroup(), updateTransform(), transform().
Выходные записи или поля
Выходные записи или поля доступны в функциях updateTransform(), transform().
Групповой аккумулятор
Групповой аккумулятор доступен в функциях initGroup(), updateGroup(), finishGroup(), updateTransform(), transform().
Пример. Сгруппировать записи.
На вход в ROLLUP подаются записи, некоторые из которых имеют одинаковое значение поля "num". Нужно соединить значения всех полей, у которых одинаковое значение num и подать на выходной порт.
- Создать метаданные.
rollin:
- stra (string),
- num (integer),
- stro (string),
- Поместить компоненты на рабочую область.
- Соединить узлы ребрами и назначить им метаданные.
- Задать значения атрибутов узлу ROLLUP.
groupKeyFields = "num",
groupAccumulatorMetadataId = "rollin",
transform =
function initGroup(groupAccumulator) {
groupAccumulator.s = null;
groupAccumulator.t = 0;
groupAccumulator.r = null;
}
function updateGroup(groupAccumulator) {
groupAccumulator.s = groupAccumulator.s + $in[0].stra;
groupAccumulator.t = groupAccumulator.t + $in[0].num;
groupAccumulator.r = groupAccumulator.r + $in[0].stro;
return true;
}
function finishGroup(groupAccumulator) {
return true;
}
function updateTransform(counter, groupAccumulator) {
return SKIP;
}
function transform(counter, groupAccumulator) {
if(counter > 0) return SKIP;
$out[0].s = groupAccumulator.s;
$out[0].t = groupAccumulator.t;
$out[0].r = groupAccumulator.r;
return ALL;
}
- Результатом выполнения графа будут строки из входных записей, значения полей которых соединенны при условии наличия одинакового значения поля "num".
CONCATENATE
CONCATENATE получает записи, поступившие из первого входного порта, отправляет их на общий выходной порт и добавляет к ним записи, из остальных входных портов. Если узел имеет более двух входных портов, записи принимаются и отправляются на выход в соответствии с порядком входных портов. Если некоторые входные порты не содержат записей, такие порты пропускаются. Узел не имеет атрибутов.
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входящего потока записей | Любые |
| 1-n | нет | Как у Input 0 | ||
| Output | 0 | да | Для объединенных записей |
Пример. Объединение записей.
Нужно объединить записи. Поданные на вход метаданные имеют поля «flower», «color».
Входящие записи:
порт 0:
| flower | color |
|---|---|
| мак | красный |
| ромашка | белый |
| василек | голубой |
порт 1:
| flower | color |
|---|---|
| роза | сиреневый |
| лилия | розовый |
порт 2:
| flower | color |
|---|---|
| подсолнух | желтый |
| анемон | вишневый |
| гипсофила | зеленый |
Решение:
После конкатенации будут получены следующие записи.
Исходящие записи:
порт 0:
| flower | color |
|---|---|
| мак | красный |
| ромашка | белый |
| василек | голубой |
| роза | сиреневый |
| лилия | розовый |
| подсолнух | желтый |
| анемон | вишневый |
| гипсофила | зеленый |
NORMALIZER
NORMALIZER создает одну или несколько выходных записей из каждой отдельной входной записи. Входные записи не обязательно сортировать.
Порты NORMALIZER:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входных записей | Любые |
| Output | 0 | да | Для нормализованных записей | Любые |
Атрибуты NORMALIZER:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| normalize | да | Определение способа нормализации записей |
|
Для NORMALIZER нужно определить функцию преобразования. Преобразование должно быть определено в файле графа в артибуте normalize. Эта функция будет вызываться заданное количество раз для каждой записи, поданной на вход этому узлу.
Функции узла NORMALIZER:
integer count()
| Параметр | Значение |
|---|---|
| Обязательный | Да |
| Входные параметры | нет |
| Возвращает | Число, которое определяет количество вызовов функции Transform() для каждой записи. Если функция count() возвращает 0, то последующий вызов Transform() не производится. |
| Вызов | Вызывается по одному разу для каждой входной записи. |
| Описание | Описывает количество повторений вызова функции transform() |
| Пример |
|
integer transform()
| Параметр | Значение |
|---|---|
| Обязательный | Да |
| Входные параметры | нет |
| Возвращает | Целое число. Число соответствует возвращаемому значению преобразования. |
| Вызов | Вызывается один раз для каждой выходной записи. Количество вызовов определяется возвращаемым значением функции count(). |
| Описание | Создает выходные записи. |
| Пример |
|
Пример. Преобразование записи с многозначными полями в несколько записей.
Входные записи содержат название должности и список имён сотрудников. Нужно преобразовать записи в кортежи, содержащие название должности и одно имя сотрудника.
менеджер | [Егор, Алина]
разработчик | [Артём, Никита, Данил]
Решение
Определим преобразование, используя атрибут normalize:
function count() {
return length($in[0].users);
}
function transform() {
$out[0].group = $in[0].group;
$out[0].user = $in[0].users;
return ALL;
}
NORMALIZER вернёт следующие записи:
менеджер |Егор
менеджер |Алина
разработчик|Артём
разработчик|Никита
разработчик|Данил
AGGREGATE
Получает записи через один входной порт, вычисляет статистическую информацию о записях входных данных и отправляет их на все выходные порты. Требует сортировки входных записей.
Порты AGGREGATE:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входных записей | Любые |
| Output | 0-n | да | Для результатов подсчетов | Любые |
Атрибуты AGGREGATE:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| aggregateKey | нет | Ключ, по которому группируются записи | key1;key2 |
| mapping | да | Определяет способ присвоениея входных данных к полям выходных метаданных. Выражения внутри маппинга разделяются точкой с запятой (;), перед именем поля метадаты нужно ставить доллар ($), для присвоения использовать двоеточие и равно (:=). | $field1:=$field1;$res:=count(field2);$srznach:=avg($field3) |
| zeroCount | нет | Определяет обработку отсутствия данных для определенного в артибуте aggregateKey ключа. При zeroCount=true, в случае отсутствия записей на входе в ноду, генерируется 1 запись на выход. Если установлено значение false, ни одна запись не создается. | false (по умолчанию)/true |
Функции AGGREGATE:
| Функция | Описание | Тип входных данных | Тип выходных данных |
|---|---|---|---|
| avg | Возвращает среднее арифметическое. | любой числовой тип | number |
| count | Подсчитывает количество строк, учитывает null. | любой | number |
| countnotnull | Подсчитывает записи, если поле содержит null, оно не учитывается. | любой | number |
| countunique | Подсчитывает уникальные значения. Считает null уникальным значением. | любой | number |
| first | Возвращает первое значение группы. | любой | любой |
| firstnotnull | Возвращает первое значение, отличное от null. | любой | любой |
| last | Возвращает последнее значение группы. | любой | любой |
| lastnotnull | Возвращает последнее значение, отличное от null. | любой | любой |
| max | Возвращает максимальное значение. | любой числовой тип | любой числовой тип |
| md5 | любой | string | |
| median | Возвращает медианное значение. null значения не учитываются. | любой числовой тип | number |
| min | Возвращает минимальное значение. | любой числовой тип | любой числовой тип, соответствующий входному |
| modus | Возвращает наиболее часто используемое значение (null-значения не учитываются). Если кандидатов больше, возвращается первый. | тип | тип |
| sum | Возвращает сумму входных значений. | любой числовой тип | number |
| const | любой | string |
Пример. Заполнение атрибутов узла AGGREGATE для вызова функций avg, count, max, last и sum.
Атрибут aggregateKey: key1,key2
Атрибут mapping:
$avg:=avg($key1);
$count:=count($key1);
$countnotnull:=countnotnull($key2);
$countunique:=countunique($key2);
$first:=first($key1);
$firstnotnull:=firstnotnull($field2);
$last:=last($field2);
$lastnotnull:=lastnotnull($field2)>
DEDUP
DEDUP удаляет повторяющиеся записи по ключу. Требует сортировки входных записей.
Порты DEDUP:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входных записей | Любые |
| Output | 0 | да | Для дедуплицированных записей. | Как у Input 0 |
| Output | 1 | нет | Для дубликатов записей. | Как у Input 0 |
Атрибуты DEDUP:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| dedupKey | нет | Ключ, по которому производится дедупликация (удаление дубликатов) записей. Если ключ не установлен, весь входной поток рассматривается как одна группа и удаляются только полные дубликаты (по всем полям записи). | dedupKey="x_coord" |
| keep | нет | Определяет, какие записи будут сохранены. В случае значения Unique все записи из входного потока, где по ключу находится больше 1 записи, отбрасываются на порт output[1]. В случае значения First и Last туда идут только те записи, которые не прошли дедупликацию.
"first" (деф.) - Сохраняются записи из начала потока. | keep="unique" |
| numberOfDuplicates | нет | Максимальное количество повторяющихся записей, которые необходимо выбрать из каждой группы записей с одинаковым значением ключа или, если ключ не задан, максимальное количество записей с начала или конца всех записей. Игнорируется, если установлен keep="Unique". | numberOfDuplicates="2" |
Пример. Дедупликация несортированных записей.
Записи содержат время входов на некоторый ресурс с различных ip адресов. Нужно найти время первого входа для каждого ip адреса. Метаданные содержат поля «ip» и «time».
Входящие записи:
| ip | time |
|---|---|
| 67.249.105.118 | 11:46:12 |
| 208.25.71.88 | 05:14:15 |
| 161.100.209.235 | 23:12:32 |
| 161.100.209.235 | 23:19:34 |
| 67.249.105.118 | 15:34:09 |
| 223.78.208.184 | 15:35:43 |
| 52.151.181.4 | 21:51:17 |
| 223.78.208.184 | 15:38:49 |
| 161.100.209.235 | 23:28:16 |
Решение:
Перед передачей в DEDUP данные надо прочитать и отсортировать. Для сортировки укажем ключ sortKey="ip(a);time(a)". При дедупликации укажем ключ: dedupKey = «ip», какие записи сохранять keep="first" и допустимое количество повторяющихся записей numberOfDuplicates="1".
Исходящие записи:
| ip | time |
|---|---|
| 67.249.105.118 | 11:46:12 |
| 208.25.71.88 | 05:14:15 |
| 161.100.209.235 | 23:12:32 |
| 223.78.208.184 | 15:35:43 |
| 52.151.181.4 | 21:51:17 |
Для объединения данных
узлы этой группы называются "Соединители". Они служат для объединения записей из потоков с потенциально разными метаданными в соответствии с заданным ключом соединения и способом преобразования.
Соединители имеют как входные, так и выходные порты. Первый входной порт узла-соединителя называется "главным" или "мастером" и обозначается номером «0», остальные входные порты — "подчинённые".
Соединители всегда объединяют только записи из главного порта с записями из подчинённых портов. И не объединяют записи из ведомых портов между собой.
- HASH_JOIN - объединяет потоки данных из двух и более источников по ключу, не требует предварительной сортировки
- MERGE_JOIN - объединяет потоки данных из двух и более источников по ключу, требует предварительную сортировку
- CROSS_JOIN - создает декартово произведение записей из подключенных входных портов, не требует предварительной сортировки
- DBJOIN - объединяет по ключу два потока данных, один из которых - база данных, не требует предварительной сортировки
- DATA_INTERSECTION - объединяет отсортированные потоки данных, может применять преобразование.
HASH_JOIN
HASH_JOIN объединяет потоки данных по ключу.
Этот узел получает данные через два или более входных порта, каждый из которых может иметь различную структуру метаданных. Записи не обязательно сортировать перед передачей в этот узел.
Сначала HASH_JOIN считывает записи из всех подчинённых портов и сохраняет их в справочник.
Для каждого подчинённого порта создается отдельная хэш-таблица. Размер всех созданных хэш-таблиц не должен превышать размер оперативной памяти сервера, так как справочники хранятся в оперативной памяти и ее переполнение приведет к завершению графа с ошибкой. Поэтому имеет смысл в главный входной поток подавать большое количество записей, а в подчинённые потоки – небольшие группы записей.
Затем для каждой записи из мастера производится поиск совпадения с записями из каждого справочника по заданному ключу соединения.
Если совпадение найдено, кортеж из записи главного порта и справочника подчинённого порта трансформируется заданным образом. Полученная после преобразования запись подаётся на первый выходной порт. Метод преобразования вызывается для каждого кортежа главной и соответствующих подчинённых записей. Записи из главного порта, которые не были объединены подаются на второй выходной порт.
Порты HASH_JOIN:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Главный входной порт | Любые |
| 1 | да | Дополнительный входной порт | ||
| 2-n | нет | Опциональные дополнительные входные порты | ||
| Output | 0 | да | Исходящий порт | |
| 1 | нет | Порт для записей, которые не подошли по ключу соединения | Как у Input 0 |
Атрибуты HASH_JOIN:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| joinKey | да | Ключ, по которому объединяются входящие потоки данных. Порты отделяются друг от друга хешем #. Сопоставление полей одного порта отделяются друг от друга точкой с запятой ';'. Перед именем каждого поля нужен знак '$'. |
|
| joinType | нет | Тип объединения. Бывает "inner"(по умолчанию) и "leftOuter" | joinType="leftOuter" |
| transform | да |
Преобразование, определенное в файле графа на внутреннем языке системы |
|
| slaveDuplicates | нет | Если установлено значение true, разрешены записи с повторяющимися значениями ключей. Если false, для объединения используется только последняя запись. По умолчанию true. | slaveDuplicates="false" |
Пример.
Даны два потока записей. В одном потоке содержится информация о названии продукта в поле «Product» и его цвете на русском языке «rus_color», во втором потоке – названию цвета на русском языке соответствует название на английском «eng_color». Задача сопоставить продукт и его цвет на английском языке.
порт0:
| product | rus_color |
|---|---|
| шарф | красный |
| носок | белый |
| свитер | зеленый |
порт1:
| rus_color | eng_color |
|---|---|
| синий | blue |
| желтый | yellow |
| красный | red |
Ключ соединения: joinKey="$rus_color"
Код трансформации для объединения:
function transform() {
$out[0].product = $in[0].product;
$out[0].eng_color = $in[1].eng_color;
return ALL;
}
Исходящие записи:
порт0:
| product | eng_color |
|---|---|
| шарф | red |
порт1:
| product | rus_color |
|---|---|
| носок | белый |
| свитер | зеленый |
MERGE_JOIN
Объединяет данные из двух или более источников данных по общему ключу. Данные должны быть отсортированы перед подачей в этот узел.
MERGE_JOIN получает данные через два или более входных порта, каждый из которых может иметь различную структуру метаданных. Затем объединенные данные отправляются на первый выходной порт. Необъединенные данные можно вывести на второй выходной порт.
Порты MERGE_JOIN:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Главный входной порт | любые |
| 1 | да | Ведомый входной порт | ||
| 2-n | нет | Дополнительные ведомые входные порты | ||
| Output | 0 | да | Выходной порт для объединенных данных | |
| 1 | нет | Выходной порт для необъединённых данных | Как на Input 0 |
Типы полей метаданных на первом входном и втором выходном портах должны быть одинаковыми, имена полей при этом могут отличаться.
Атрибуты MERGE_JOIN:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| joinKey | да | Ключ, который используется для объединения входящих потоков данных. Части ключа, соответствующие определенным входным портам, отделяются друг от друга хэшем '#'. Порядок полей в ключе должен соответствовать порядку входных портов. Поля тз одного порта внутри joinKey отделяются друг от друга точкой с запятой. Каждому имени поля должен предшествовать знак доллара '$'. В скобках после полей, по которым производилась сортировка, нужно указать её направление. | joinKey="$name(a);$color(d)#$product;$tint;#$name;$tone" |
| joinType | нет | Тип объединения. | inner (по умолчанию) | leftOuter |
| transform | да | Преобразование, определенное в графе на внутреннем языке системы. |
|
| slaveDuplicates | нет | Если установлено значение true, разрешены записи с повторяющимися значениями ключей. Если false, для объединения используется только последняя запись. По умолчанию true. | slaveDuplicates="false" |
Пример. Объединить записи из двух потоков по ключу.
- Описать метаданные
- Переместить узлы на рабочую область.
- Соединить узлы ребрами и назначить им метаданные.
- Заполнить атрибуты MERGE_JOIN:
joinKey = "$s1(a);$s3#$m1(a);$m3"
joinType = "leftOuter"
transform =
function transform() {
$out[0].s = $in[0].s1 + $in[1].m1;
$out[0].m = $in[0].s3 + $in[1].m3;
return ALL;
}
slaveDuplicates = "false"
equalNull = "true"
- Данные с двух потоков будут объединены.
CROSS_JOIN
CROSS_JOIN создает декартово произведение записей из подключенных входных портов.
Каждая строка из первого порта соединяется с каждой строкой из последующих портов, в результате получаются все возможные сочетания значений со всех портов. Возможно преобразование данных с помощью атрибута transform.
CROSS_JOIN автоматически передаёт метаданные на выходной порт в соответствии с метаданными на его входных портах.
Заметка: при обработке очень большого количества записей, на жёстком диске могут быть созданы временные файлы с обрабатываемыми записями. Это предотвращает чрезмерное использование оперативной памяти.
Порты CROSS_JOIN:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Главный входной порт | любые |
| 1-n | нет | Ведомый входной порт(ы) | ||
| Output | 0 | да | Для выходных записей |
Атрибуты CROSS_JOIN:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| transform |
нет | Функция преобразования данных, определённая в графе |
|
Пример.
Создать таблицу со всеми возможными сочетаниями игроков в бильярд из двух команд:
Игроки первой команды:
Вася
Маша
Никита
Игроки второй команды:
Алёна
Петя
Лиза
Решение: Нужно только подключить источники данных к портам компонента CROSS_JOIN. Настройка атрибутов компонента не требуется.
В результате получится такой набор пар игроков в бильярд:
Вася | Алёна
Вася | Петя
Вася | Лиза
Маша | Алёна
Маша | Петя
Маша | Лиза
Никита | Алёна
Никита | Петя
Никита | Лиза
Заметка: Ребро, по которому передаётся наибольшее количество записей, должно быть подключено к первому входному порту.
DBJOIN
DBJOIN получает данные через один входной порт и объединяет их с данными из таблицы базы данных. Эти два источника данных могут иметь разную структуру метаданных.
Узел DBJOIN не требует сортировки входных данных и работает очень быстро, поскольку данные обрабатываются в памяти.
После объединения к данным применяется преобразование и результат отправляется на первый выходной порт. Второй выходной порт может использоваться для вывода несовпадающих по ключу записей из основного потока.
Поток, передающий данные через первый входной порт, называется основным, а поток данных из базы называется подчинённым. Его данные считаются поступившими через виртуальный входной порт. Каждая основная запись сопоставляется с подчинённой записью по одному или нескольким полям, называемым ключом соединения.
Порты DBJOIN:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Главный входной порт | Любые |
| 1 (виртуальный) | да | Подчинённый входной порт | ||
| Output | 0 | да | Выходной порт для объединенных данных | |
| 1 | нет | Выходной порт для необъединённых данных | Как на Input 0 |
Атрибуты DBJOIN:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| joinKey | да | Ключ, по которому объединяются входящие потоки данных. Если полей ключа несколько - они должны быть записаны через точку с запятой. Перед именем поля должен стоять знак доллара `$`. |
|
| joinType | нет | Тип объединения. Бывает "inner"(по умолчанию) и "leftOuter" | joinType="leftOuter" |
| dbConnection | да | Идентификатор соединения с БД, который будет использоваться в качестве ресурса подчинённых записей. | conn0 |
| sqlQuery | да | SQL-запрос. В условии WHERE нужно использовать плейсхолдер '?' для подстановки значения ключа (если ключ составной, используйте плейсхолдер для каждого поля в WHERE). |
|
url | да | Имя внешнего файла, включая путь, содержащий SQL-запрос. |
|
| transform | да | Функция преобразования |
|
| cacheSize | Максимальное количество записей с разными значениями ключей, которые можно сохранить в памяти. |
| |
| charset | Кодировка файла, в котором хранится алгоритм преобразования. |
|
Ключ соединения
Ключ соединения — это последовательность имен полей из основного источника данных, отделенных друг от друга точкой с запятой. Ключ можно определить в редакторе узла. Порядок имен полей должен соответствовать порядку ключевых полей таблицы базы данных (и их типам данных). Подчинённая часть ключа соединения должна быть определена в атрибуте sqlQuery.
$first_name;$last_name
Это поля, которые служат для объединения основных записей с подчинёнными записями. SQL-запрос должен содержать выражение, которое может выглядеть следующим образом:
... where fname=? and lname=?
Значение first_name будет подставлено на место первого знака вопроса в этом условии, а last_name - на место второго. Сначала будет произведён поиск совпадений по joinKey в кеш-памяти, если подходящих записей не обнаружится, то данные будут запрошены из базы данных, иначе - найденная запись сразу отправится для преобразования в функцию transform.
Преобразование
Преобразование в DBJOIN позволяет определить способ сопоставления данных, с помощью которого записи буду отправлены на первый выходной порт. Несоединенные записи из основного потока, отправляемые на второй выходной порт, не могут быть изменены в рамках преобразования DBJOIN.
Заметка: Если преобразование указано во внешнем файле, рекомендуется явно указать кодировку файла в артибуте
charset.
Заметка:
- при получении более одной записи из базы в лог будет выведено предупреждение "read more than one record".
- при автоматическом увеличении рамера кеша для обработки данных - "riched cache size".
Пример. Соединение записей из двух источников.
- Объединим записи из двух баз. Используем DB_READER для чтения из базы postgres и DBJOIN для чтения из firebird и объединения потоков по ключу.
Запрос для DB_READER:
sqlQuery = "select bigintcolumn, booleancolumn, charcolumn, smallintcolumn, textcolumn from onebridge."million_row" order by bigintcolumn limit 100"
Атрибуты для DBJOIN:
sqlQuery = "select FIRST 100 bigintcolumn, booleancolumn, charcolumn, smallintcolumn, textcolumn from MILLION_ROW WHERE bigintcolumn = ?"
Объединённые данные можно вывести на первый выходной порт DBJOIN, а не обьединенные данные с главного входного порта - на второй порт.
DATA_INTERSECTION
DATA_INTERSECTION получает отсортированные данные с двух портов, сравнивает их значения по ключу и обрабатывает записи следующим образом:
-
Входные записи с обоих входных портов, совпавшие по ключу, обрабатываются в соответствии с определённым в атрибуте
transformпреобразованием, и результат отправляется на выходной порт 1. -
Не подошедшие по ключу записи со входного порта 0, отправляются без изменений на выходной порт 0.
-
Не подошедшие по ключу записи из порта 1 - на выходной порт 2.
Записи считаются находящимися на обоих портах, если значения всех полей ключа соединения в них совпадают.
Преобразование должно быть определено, если подключён выходной порт 1.
Перед попаданием в данный узел данные должны быть отсортированы.
Порты DATA_INTERSECTION:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входных записей (поток данных A). |
Любые1 |
| 1 | да | Для входных записей (поток данных Б). |
Любые1 | |
|
Output2 | 0 | нет | Для неизмененных выходных записей (содержащихся только в потоке A). | Как на Input 0 |
| 1 | нет | Для измененных выходных записей (содержащихся в обоих входных потоках). | Любые | |
| 2 | нет | Для неизмененных выходных записей (содержащихся только в потоке Б). | Как на Input 1 |
Часть полей метаданных должна совпадать с полями ключа соединения.
Хотя бы один выходной порт из трех должен быть подключён.
Атрибуты DATA_INTERSECTION:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| joinKey | да | Ключ, для сравнения записей из входных портов. |
|
| transform |
обязательно, если порт | Определение способа пересечения записей со входных портов. |
|
| equalNull | нет |
По умолчанию записи с нулевыми значениями ключевых полей считаются равными. Если установлено значение |
|
| keyDuplicates | нет |
Разрешает дублирование ключа. По умолчанию установлено значение |
|
Ключ соединения
Выражается как последовательность отдельных подвыражений, отделенных друг от друга точкой с запятой. Каждое подвыражение представляет собой присвоение имени поля из первого входного порта (с префиксом в виде знака доллара $) слева и имени поля из второго входного порта (с префиксом $) с правой стороны.
Дублирование данных
Компонент DATA_INTERSECTION может возвращать количество записей, отличное от исходного количества входных записей.
Если для параметра keyDuplicates установлено значение false, количество выходных записей может быть меньше количества входных записей, поскольку используется только первая из записей с дубликатом ключа.
Если для параметра keyDuplicates установлено значение true, количество выходных записей может быть больше, чем количество входных записей. На выходе создается декартово произведение записей, имеющих одинаковый ключ.
Для управления графами
Узел из группы управления графами позволяют запускать другие графы, отслеживать и при необходимости прерывать граф.
Реализованы следующие узел для управления графами:
- EXECUTE_GRAPH - запускает графы и может передать в них параметры.
- GET_JOB_INPUT - извлекает значения параметров графа и отправляет их в выходной порт.
- SET_JOB_OUTPUT - заполняет значения переменной входящими данными из потока.
- SUCCESS - принудительно завершает граф успешно.
- FAIL - принудительно завершает граф с ошибкой.
- EXECUTE_SCRIPT - выполняет указанный скрипт.
EXECUTE_GRAPH
Узел EXECUTE_GRAPH запускает граф с определенными настройками, ожидает завершения графа и предоставляет результаты и детали выполнения на выходные порты.
Порты EXECUTE_GRAPH:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | нет | Входные записи с настройками выполнения графа. | Любые |
| Output | 0 | нет | Информация об успешном выполнении графа. | |
| 1 | нет | Информация о неудачном выполнении графа. |
Атрибуты EXECUTE_GRAPH:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| jobURL | да | Путь к исполняемому графу. В этом атрибуте можно указать только один граф. Значение может быть переопределено значением из входного потока, см. атрибут `inputMapping`. |
|
| orderOutput | нет | Параметр указывает, сохранится ли порядок дочерних графов на выходе потока данных из узла. При 'true' - выходные данные подаются в соответствии с порядком запуска дочерних графов. При 'false', результаты выполнения передаются на выходной порт по мере выполнения. |
|
| concurrentRunsLimit | нет | Количество исполняемых параллельно дочерних графов. |
|
| inputMapping | нет | Маппинг входных данных определяет, как данные из входящего потока переопределяют значение jobURL, значение передаваемых в вызываемый граф параметров и переменных.
порт $out[0] - для переопределения значения jobURL; |
|
| outputMapping | нет | Маппинг выходных данных сопоставляет результаты успешного выполнения графа с метаданными первого выходного порта.
порт $in[0] - для передачи записей из внутреннего графа. |
|
| errorMapping | нет | Маппинг ошибок отображает результаты неудачных запусков графов на второй выходной порт. |
|
Подробности хода выполнения
Компонент считывает входную запись, выполняет граф на основе значений входящих данных, ждет завершения графа и отправляет результаты на соответствующий порт. Результаты успешного запуска графа отправляются на первый выходной порт. Результаты неудачного запуска отправляются на второй выходной порт (порт ошибки).
Если запуск графа прошел успешно, компонент продолжает обработку следующих входных записей. В противном случае компонент прекращает выполнение других графов, и с этого момента все входящие записи игнорируются, а информация об игнорируемых записях отправляется на порт вывода ошибок.
Подключенные и отключенные порты
В случае, если входной порт не подключен, выполняется только один граф с настройками по умолчанию, указанными в атрибутах компонента.
В случае, если первый выходной порт не подключен, компонент не выводит результаты выполнения графа.
Если второй выходной порт (порт ошибки) не подключен, первый граф с ошибкой приведет к прерыванию родительского графа.
Конфигурация компонента
Для запуска графа с помощью узла EXECUTE_GRAPH необходимо указать местоположение исполняемого графа в атрибуте jobURL.
Большинство настроек выполнения можно указать в узле с помощью атрибутов компонента, описанных ниже.
Настройки выполнения графа можно изменять для каждого запуска на основе данных из входящего потока в атрибуте inputMapping.
Типы выполнения графа
EXECUTE_GRAPH поддерживает синхронное (последовательное) и асинхронное (параллельное) выполнение графов.
Для управления синхронностью выполнения используйте следующие атрибуты узла:
- concurrentRunsLimit - целое число, обозначающее сколько графов одновременно могут выполняться. По умолчанию значение равно
1и дочерние графы выполняются параллельно, но если установить большее значение, то графы смогут выполняться асинхронно. - orderOutput - указывает порядок информации о дочерних графах, выдаваемой на выходной порт узла ExecuteGraph. По-умолчанию установлено значение
trueи выходные данные подаются в соответствии с порядком запуска дочерних графов. Приfalse, результаты выполнения будут передаваться на выходной порт по мере выполнения дочерних графов.
Маппинг входных данных
Атрибут inputMapping позволяет переопределить настройки узла на основе данных из входящего потока.
Маппинг входных данных — это преобразование, которое выполняется для каждой входной записи. С помощью inputMapping можно переопределить атрибут jobURL и передать в исполняемый граф значения его атрибутов и записи переменной.
На первый выходной порт можно подать значение для переопределения атрибута jobURL, а на второй выходной порт - параметры для исполняемого графа.
Можно задавать не только явно определённые публичные параметры, но и определять новые параметры, они будут доступны внутри графа по аналогии с такими встроенными параметрами как runId.
| Тип порта | Номер | Обязательный | Описание | Пример |
|---|---|---|---|---|
| Output | 0 | нет | Для переопределения пути к исполняемому графу |
|
| 1 | Для передачи параметров в исполняемый граф |
| ||
| 2 | Для передачи записей в переменную исполняемого графа |
|
Маппинг выходных данных
outputMapping — это преобразование, которое используется для заполнения потока, передаваемого в первый выходной порт узла EXECUTE_GRAPH. Этот маппинг используется для вывода данных при успешном выполнении графа.
Данные, предоставляемые на первый выходной порт EXECUTE_GRAPH с помощью outputMapping описаны в таблице ниже. Первый выходной порт задействуется только если статус графа $in[1].status = "SUCCEEDED", в противном случае будет вызван errortMapping и данные пойдут на второй выходной порт.
| Тип порта | Номер | Обязательный | Описание | Пример |
|---|---|---|---|---|
| Output | 0 | нет | Для входящего потока записей |
|
| 1 | Уникальный идентификатор запуска графа |
| ||
| Путь к исполняемому графу |
| |||
| Время запуска графа |
| |||
| Время завершения графа |
| |||
| Окончательный статус выполнения графа, один из { SUCCEEDED, FAILED } |
| |||
| 2 | Для передачи записей из переменной исполняемого графа |
|
Маппинг ошибок
errorMapping — это тоже трансформация. Она используется для вывода ошибок. Данные, которые можно отправить через errorMapping аналогичны описанным в таблице в outputMapping.
Маппинг ошибок используется в том случае, если внутренний граф завершился неудачно - со статусом $in[1].status = "FAILED" - тогда вместо первого заполняется второй выходной порт узла EXECUTE_GRAPH.
Если маппинг ошибок не определен, а во внутреннем графе произошла ошибка - родительский граф не сможет ее обработать и упадёт.
Пример передачи параметров через переменную
Для передачи данных из основного графа во внутренний через переменную, необходимо использовать второй выходной порт в inputMapping. Для передачи значений из переменной внутреннего графа в основной - второй входной порт в outputMapping.
Задание: Передать значение в переменную внутреннего графа, изменить его, получить изменённое значение и вывести его в лог.
Решение: Чтобы запустить из графа другой граф, используйте узел EXECUTE_GRAPH. Чтобы передать значения в вызываемый граф - заполните атрибут inputMapping, присвоив начальное значение записи переменной вызываемого графа. Изменённое внутри вызываемого графа значение переменной можно получить в основном графе через outputMapping узла EXECUTE_GRAPH.
В inputMapping узла execgrf через второй выходной порт присвойте значение 11 записи переменной с именем foo, определённого во внутреннем графе. Значение переменной передаётся во внутренний граф. В outputMapping будет получено через второй входной порт изменённое значение записи этой переменной.
Для узла EXECUTE_GRAPH с jobURL="dict_inner3.grf" заполните маппинги:
inputMapping:
function transform() {
$out[2].foo = 11;
return ALL;
}
outputMapping:
function transform() {
$out[0].foo = $in[2].foo;
return ALL;
}
Объявление переменной во внутреннем графе:
name="foo"
value="1"
type="integer"
Переопределение значения записи переменной foo в узле DATA_GENERATOR внутреннего графа:
function generate() {
$out[0].foo = dictionary.foo;
dictionary.foo = 43;
return ALL;
}
GET_JOB_INPUT
Узел GET_JOB_INPUT извлекает значения параметров графа и отправляет их в выходной порт. Компонент создает одну выходную запись, которая заполняется содержимым переменной или параметрами графа.
Порты GET_JOB_INPUT:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | Для записей, содержащих входные данные для графа. | Любые |
Атрибуты GET_JOB_INPUT:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| mapping | да | Маппинг заполняет выходную запись переменной. Входные записи переменной и параметры графа являются естественными значениями для маппинга. |
|
Пример. Прочитать значения переменной и параметра.
Например, нужно прочитать значение переменной "dct1" и параметра "prm1" и передать их дальше для обработки.
Для этого понадобится узел GET_JOB_INPUT и TRASH для вывода данных и метаданные для передачи данных.
В GET_JOB_INPUT нужно заполнить значение атрибута "mapping" следующим присвоением:
function transform() {
$out[0].dct = dictionary.dct1;
$out[0].prm = "${prm1}";
return ALL;
}
Значения переменной и параметра будут поданы на выходной порт узла GET_JOB_INPUT.
SET_JOB_OUTPUT
Узел SET_JOB_OUTPUT заполняет значения переменной входящими данными из потока. Выходные записи переменной заполняются в соответствии с маппингом. Первая входная запись устанавливает значения записей переменной, а последующие входные записи переопределяют существующие значения.
Порты SET_JOB_OUTPUT:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Intput | 0 | да | Для внесения записей в переменную. | Любые |
Атрибуты SET_JOB_OUTPUT:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| mapping | да | Определяет сопоставление метаданных входной записи с выходными записями переменной. |
|
Пример. Присвоить значения из входного потока переменной.
Например, нужно прочитать значение поля "word" и присвоить его переменной "dct1".
Для этого понадобится узел FLAT_FILE_WRITER, чтобы передать значение поля, SET_JOB_OUTPUT для установки значения переменной. Для проверки можно использовать GET_GOB_INPUT и TRASH для вывода данных переменной на ребро.
В SET_JOB_OUTPUT нужно заполнить значение атрибута "mapping" следующим присвоением:
function transform() {
dictionary.dct1 = $in[0].word;
return ALL;
}
Значение поля "word" будет присвоено переменной с именем "dct1".
SUCCESS
SUCCESS — это успешная конечная точка рабочего процесса. Записи, поступающие в компонент, больше не обрабатываются — они считаются успешно обработанными в рамках текущего запуска. У узла только один входной порт. Узел не содержит атрибутов.
Порты SUCCESS:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входных записей | Любые |
FAIL
FAIL прерывает выполнение графа как только в него попадают записи. Родительский граф останавливается со статусом Не выполнено.
Порты FAIL:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | да | Для входных записей | Любые |
EXECUTE_SCRIPT
Узел EXECUTE_SCRIPT запускает указанный скрипт с помощью выбранного интерпретатора.
Если к входному порту не подключено ребро, узел запускает скрипт только один раз. В этом случае создается одна выходная запись.
Когда на входной порт поступают записи, выполняется одно выполнение скрипта для каждой записи и создается одна выходная запись для каждого выполнения скрипта.
Если скрипт выполнен успешно, узел продолжает обработку следующих входных записей. В противном случае узел прекращает выполнение скрипта и завершается с ошибкой.
Порты EXECUTE_SCRIPT:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | нет | Параметры запуска скрипта. | Любые |
| Output | 0 | нет | Результаты выполнения скрипта. | Любые |
Атрибуты EXECUTE_SCRIPT:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| script | нет | Код скрипта, который будет выполнен. | |
| scriptURL | нет | URL-адрес скрипта, который будет выполнен. | scriptURL="./folder/data/stage/script.exe" |
| scriptCharset | нет | Кодировка символов, используемая в скрипте. | scriptCharset="UTF-8 " |
| interpreter | да | Используемый интерпретатор. | interpreter="сmd" |
| workingDirectory | нет | Рабочий каталог исполняемого скрипта. Все относительные пути, используемые внутри скрипта, будут интерпретироваться относительно этого каталога. | workingDirectory="./data-tmp/stage/ftpClearHistory/" |
| inputMapping | нет | Задаёт параметры выполнения скрипта. Можно переопределить script, scriptURL, interpreter, workingDirectory. |
|
| outputMapping | нет | Сопоставляет результаты успешного выполнения скрипта с метаданными на выходном порте. |
|
Мапинг входных данных
Атрибут inputMapping позволяет переопределить настройки узла на основе данных из входящего потока.
Параметры, которые можно переопределить в inputMapping:
script,scriptURL,scriptCharset,interpreter,workingDirectory.
Маппинг выходных данных
outputMapping — это преобразование, которое используется для заполнения потока, передаваемого в нулевой выходной порт узла EXECUTE_SCRIPT. Этот маппинг используется для вывода данных при успешном выполнении графа.
Данные, которые узел может подать на выход:
std_out,err_out,exit_value,err_exception.
Пример. Выполнение скрипта, указанного в файле.
Нужно запустить скрипт и вывести результат его работы в файл. Для этого:
- Поместить узел EXECUTE_SCRIPT на рабочую панель Дизайнера.
- Заполнить атрибуты EXECUTE_SCRIPT в редакторе узла:
| Атрибут | Значение |
|---|---|
| scriptURL | some_directory_name/scriptURL.sh |
| interpreter | sh |
| outputMapping |
|
- Поместить на рабочую область узел FLAT_FILE_WRITER.
- Заполнить атрибуты FLAT_FILE_WRITER в редакторе узла:
| Атрибут | Значение |
|---|---|
| fileURL | dataout_dir/file_name.txt |
- Соединить узлы ребром с метаданными:
| Имя поля | Тип данных |
|---|---|
| stdOut | string |
| errOut | string |
| exitValue | string |
| errException | string |
Используемый скрипт:
echo 'scriptURL'
После запуска графа в файл "dataout_dir/file_name.txt" запишется следующее:
| Имя поля | Значение |
|---|---|
| stdOut | scriptURL |
| errOut | |
| exitValue | exit status: 0 |
| errException |
Другие
Узлы этой группы служат для выполнения множества разнородных задач.
- NOTE - вставляет заметку в рабочую область графа
- DB_EXECUTE - выполняет указанный SQL-запрос к базе данных
- LIST_FILES - перечисляет содержимое каталога
- INPUT_TABLE - работает с табличными данными в виде строки
- HTTP_CONNECTOR - обращается к серверу посредством HTTP-запросов
NOTE
NOTE (примечание, заметка) - позволяют пользователю вводить необходимую информацию непосредственно в граф. Примечания могут служить документацией к конкретному графу. Также заметки могут служить контейнерами для компонентов. Если вы перемещаете заметку, вы также перемещаете компоненты внутри заметки. Если вы вводите какой-либо параметр в заметке, этот параметр не заменяется его значением. У заметок нет портов и атрибутов, так как они являются не рабочей частью графа, а только вспомогательным элементом.
Вы можете поместить заметку на граф из Списка компонентов: перетащите заметку из Списка и поместите ее в Рабочую панель.
Заметка в графе

DB_EXECUTE
DB_EXECUTE выполняет указанные SQL-инструкции для базы данных, подключенной с помощью драйвера ODBC. Он может выполнять запросы, транзакции, вызывать хранимые процедуры или функции.
Входные параметры могут быть получены через первый входной порт, а выходные параметры или набор результатов отправляются в первый выходной порт. Информация об ошибке может быть отправлена на второй выходной порт.
Порты DB_EXECUTE:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | нет* | Входные записи для SQL запроса | Любые |
| Output | 0 | нет** | Результат выполнения | Любые |
| 1 | нет | Ошибки выполнения | На основе входных метаданных |
* Входной порт должен быть подключен, если указан атрибут 'inParameters' или если через входной порт принимается весь SQL-запрос.
** Выходной порт должен быть подключен, если указаны выходные параметры запроса в 'outParameters' или атрибут 'outputFields'.
Атрибуты DB_EXECUTE:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| dbConnection | да | Идентификатор соединения с БД, которое будет использоваться. |
|
| sqlQuery | да | SQL-запрос. Содержит операторы SQL, которые следует выполнить для базы данных.
Если запрос состоит из нескольких операторов, они должны быть отделены друг от друга указанным разделителем операторов SQL. Операторы будут выполняться один за другим. |
|
| inParameters | нет | Используется при вызове хранимой процедуры/функции с входными параметрами. Это последовательность следующего типа: 1:=$inputField1;…;n:=$inputFieldN. Значение каждого указанного поля ввода сопоставляется с соответствующим параметром (позиция которого в SQL-запросе равна указанному числу). | inParameters="1:=$srgKey;" |
| outParameters | нет | Используется при вызове хранимой процедуры или функции с выходными параметрами или возвращаемым значением. Это последовательность следующего типа: 1:=$outputField1;…;n:=$outputFieldN. Значение каждого выходного параметра (определяемого его позицией в SQL-запросе) будет записано в указанное поле. | outParameters="2:=$customer_name;" |
| outputFields | нет | Если хранимая процедура или функция возвращает набор данных, ее выходные данные будут сопоставлены с заданными полями вывода. Атрибут выражается как последовательность имен выходных полей, отделенных друг от друга точкой с запятой. | outputFields="1:=$square;2:=$cube" |
| inTransaction | нет | Указывает, должны ли выполняться инструкции в транзакции. Применяется в случае, если база данных поддерживает транзакции. | SET (default) | ONE | ALL | NEVER_COMMIT |
| url | нет | Содержит либо имя внешнего файла, содержащего SQL-запрос, либо строку, которая используется для чтения из входного порта. |
или |
| charset | нет | Кодировка внешнего файла, указанного в атрибуте url | charset="UTF-8" |
Пример. Очистка таблицы.
Узел DB_EXECUTE можно использовать, например, для очистки таблицы перед заполнением её с помощью другого узлаа.
- Переместите DB_EXECUTE с палитры компонентов на рабочую область дизайнера
- Заполните его атрибуты:
| Атрибут | Значение |
|---|---|
| dbConnection | conn0 (имя соединения) |
| sqlQuery |
|
Таблица services будет очищена.
LIST_FILES
LIST_FILES перечисляет содержимое каталога, включая подробную информацию об отдельных файлах, например, размер или дата модификации. Подкаталоги могут быть перечислены рекурсивно.
Порты LIST_FILES:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | нет | для входных записей. | Любые |
| Output | 0 | да | для выходных записей, по одной на каждую запись из целевого каталога. | Любые |
Атрибуты LIST_FILES:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| fileURL | нет | Путь к файлу или каталогу, который должен быть обработан. | fileURL="${GRAPH_DIR}/bl/Megapolis/dic/list.grf" |
| recursive | нет | Перечислять подкаталоги рекурсивно. По умолчанию 'false'. | recursive='true' |
| inputMapping | нет | Определяет сопоставление входных записей с атрибутами компонента. Позволяет переопределить fileURL и recursive. |
|
| outputMapping | нет | Определяет отображение результатов на выходном порте. |
|
INPUT_TABLE
Узел INPUT_TABLE позволяет работать с табличными данными в виде строки с разделителями.
Порты INPUT_TABLE:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Output | 0 | да | для распарсенных записей. | Любые |
Атрибуты INPUT_TABLE:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| data | нет | Табличные данные в виде строки с разделителями. |
|
HTTP_CONNECTOR
HTTP_CONNECTOR отправляет запросы к указанному серверу и получает ответы. Ответ может быть отправлен на выходной порт или сохранён в указанном файле.
Порты HTTP_CONNECTOR:
| Тип порта | Номер | Обязательный | Описание | Метаданные |
|---|---|---|---|---|
| Input | 0 | нет | Для установки различных атрибутов узла | Любые |
| Output | 0 | Содержимое ответа, путь к файлу ответа, код состояния, атрибуты узла | ||
| 1 | Подробности об ошибках |
Атрибуты HTTP_CONNECTOR:
| Атрибут | Обязательный | Описание | Возможные значения |
|---|---|---|---|
| url | нет | URL-адрес сервера, к которому подключается коннектор. Поддерживаются протоколы HTTP и HTTPS. | |
| requestMethod | нет | Метод запроса. | GET (по умолчанию) | POST | PUT | PATCH | DELETE | HEAD | OPTIONS | TRACE |
| additionalHttpHeaders | нет | Дополнительные свойства запроса, который будет отправлен на сервер. Представляет собой последовательность пар ключ=значение, разделенных запятой. | content-type=application/json |
| requestContent | нет | Содержимое запроса, определенное непосредственно в графе. |
|
| inputFileURL | нет | URL-адрес загружаемого файла. | |
| outputFileURL | нет | URL файла, в который записывается ответ на запрос. | |
| appendOutput | нет | По умолчанию любой новый ответ перезаписывает старый. Если вы переключите этот атрибут на true, новый ответ будет добавлен к старым. Применяется только к выходным файлам. | |
| inputMapping | нет | Сопоставление входных данных. Позволяет передавать значения атрибутов узла, сопоставляя их значения с данными из входного порта. Использование атрибута inputMapping устанавливает остальные входные атрибуты в их дефолтные значения, в связи с этим, при использовании входного маппинга стоит задавать через него сразу все значения атрибутов. |
|
| outputMapping | нет | Сопоставление выходных данных. Позволяет сопоставить данные ответа на запрос (например, содержимое тела ответа, код состояния и т.д.) с метаданными выходного порта. |
|
| errorMapping | нет | Маппинг ошибок. Позволяет сопоставить сообщения об ошибке с метаданными выходного порта. |
|
| redirectErrorOutput | нет | Позволяет перенаправить сведения об ошибке на нулевой выходной порт. | redirectErrorOutput="false" по умолчанию |
| timeout | нет | Как долго узел ждет ответа. Если он не получает ответ в течение указанного срока, выполнение узла завершается неудачей. По умолчанию HTTP_CONNECTOR имеет тайм-аут в одну минуту. Тайм-аут указывается в миллисекундах. | timeout="60000" |
| retryCount | нет | Количество раз, которое нужно повторить запрос в случае сбоя. Сбой означает то же самое, что и использование компонентом порта ошибки. Компонент считает сбой, если он не может обработать запрос/ответ. Если он обрабатывает запрос и получает ответ с кодом статуса ошибки (например, 500), это не является сбоем. | retryCount="6" |
| retryDelay | нет | Как долго узел должен ждать перед повторной попыткой запроса. Если retryCount не нулевой, узел будет ждать дополнительное время перед повторной отправкой запроса. Значение атрибута — это список целых чисел, разделенных запятой. Задержка повтора указывается в секундах. Если количество повторных попыток превышает размер списка, то используется последняя задержка в списке. | retryDelay="4,2,5" |
| dnsResolver | нет | Для явного указания адреса сервера. Установите порт ":0", чтобы использовать обычный порт для указанной меты (например, 80 для http). Порты в самом URL всегда будут использоваться вместо порта в переопределенном адресе. | dev.allbridge.ru=127.0.0.1:0,127.0.0.1:443; another.domain.ru=192.168.0.0:0 |
Маппинг входных данных
В атрибуте inputMapping можно указать, какие поля из входной записи следует сопоставить с атрибутами узла.
- URL — адрес, по которому будет отправлен запрос.
- requestMethod — метод, который будет использован при отправке запроса.
- additionalHttpHeaders - дополнительные заголовки запроса.
- requestContent — содержимое отправляемого запроса в виде строки.
- inputFileUrl — адрес файла, который нужно отправить, относительно проекта.
- outputFileURL - адрес файла в который записать ответ.
- appendOutput - применяется, если указан outputFileURL. При appendOutput=true новый ответ будет дозаписан в выходной файл без очистки файла от предыдущего содержимого.
Пример заполнения преобразования для маппинга входных данных:
function transform() {
$out[0].requestContent = $in[1].requestContent;
return ALL;
}
Маппинг выходных данных
С помощью атрибута outputMapping на первый выходной порт можно отправить такие данные:
- Результат — предоставляет данные о результате запроса. К нему относятся:
- content — содержимое HTTP-ответа (response body) в виде строки. Это поле будет иметь значение null, если ответ записывается в файл.
- outputFilePath - путь к файлу, в который записан ответ. Будет null, если ответ не записывается в файл.
- statusCode — код состояния HTTP ответа.
- rawHeaders — заголовки (response headers) ответа.
- errorMessage — сообщение об ошибке в случае, если вывод ошибки перенаправляется на стандартный порт вывода.
Пример заполнения преобразования для маппинга выходных данных:
function transform() {
$out[0].content = $in[1].content;
$out[0].outputFilePath = $in[1].outputFilePath;
$out[0].statusCode = $in[1].statusCode;
$out[0].rawHeaders = $in[1].rawHeaders;
$out[0].errorMesage = $in[1].errorMesage;
return ALL;
}
Маппинг ошибок
С помощью атрибута errorMapping можно вывести сообщение об ошибке на выходной порт HTTP_CONNECTOR. Поведение очень похоже на отображение выходных данных, но данные при этом выводятся на первый выходной порт узла, вместо нулевого.
Для того, чтобы потенциальная ошибка была выведена на порт ошибки, нужно указать для атрибута redirectErrorOutput значение false. При redirectErrorOutput=true ошибка будет выведена на нулевой выходной порт, вместе с остальными выходными данными узла.
Если в ответ на запрос приходит ошибка, а
errorMappingне заполнен иredirectErrorOutput=false, то граф не сможет её обработать и упадет.
Пример заполнения преобразования для маппинга ошибок:
function transform() {
$out[1].errorMesage = $in[1].errorMesageж;
return ALL;
}
Пример 1. Скачать Web-страницу
Загрузите содержимое веб-страницы modernsolution.ru/onebridge с помощью HTTP_CONNECTOR. Сохраните результат в файл для дальнейшей обработки.
Решение
Используйте атрибуты url, requestMethod и outputFileURL.
Загруженная страница будет сохранена в файле result.html в каталоге ${DATAOUT_DIR}.
| Атрибут | Значение |
|---|---|
| url | |
| requestMethod | get |
| outputFileURL | ${DATAOUT_DIR}/result.html |
Пример 2. Получение токенов доступа для Onebridge и запуск графа с помощью HTTP_CONNECTOR
Цель данного примера - показать схему авторизации с получением токенов через api для запуска в работу графа Onebridge.
Для того чтобы запустить граф в работу, нужно быть авторизованным пользователем с набором привилегий для запуска. Предположим, все нужные привилегии пользователю выданы, осталось получить токен для авторизованной отправки запроса на запуск графа.
Чтобы получить токены, нужно отправить запрос на аутентификацию с помощью того же HTTP_CONNECTOR:
- Переместите на рабочую область Дизайнера узел HTTP_CONNECTOR из палитры компонентов.
- Заполните атрибуты узла с помощью редактора узла:
| Атрибут | Значение |
|---|---|
| url | |
| requestMethod | POST |
| additionalHttpHeaders | content-type=application/json |
| requestContent | {"username": "${username}", "password":"${password}"} |
| outputMapping |
|
| errorMapping |
|
| redirectErrorOutput | false |
- Полученные токены нужно передать дальше в MAP через первый выходной порт. Для обработки ошибок заполните errorMapping и подключите ко второму выходному порту узел TRASH.
- В MAP можно распарсить присланный в ответе на запрос json в две отдельных переменных следующим образом:
| Атрибут | Значение |
|---|---|
| transform |
|
- Теперь нужно отправить авторизованный запрос на запуск графа, для этого используем новый HTTP_CONNECTOR, заполнив его атрибуты следующим образом:
| Атрибут | Значение |
|---|---|
| url | |
| requestMethod | POST |
| inputMapping |
|
| outputMapping |
|
| errorMapping |
|
| redirectErrorOutput | false |
- В случае успешного ответа на post-запрос для запуска графа должен прийти номер запущенного графа. Выведем его номер на первый выходной порт, например в файл с помощью FLAT_FILE_WRITER. Порт ошибок можно соединить с еще одним узлом TRASH.
- Для связи между узлами нужно описать метаданные и присвоить их соответствующим рёбрам.
Граф с распределенными метаданными будет выглядеть вот так:
Распределение метаданных на рёбрах графа
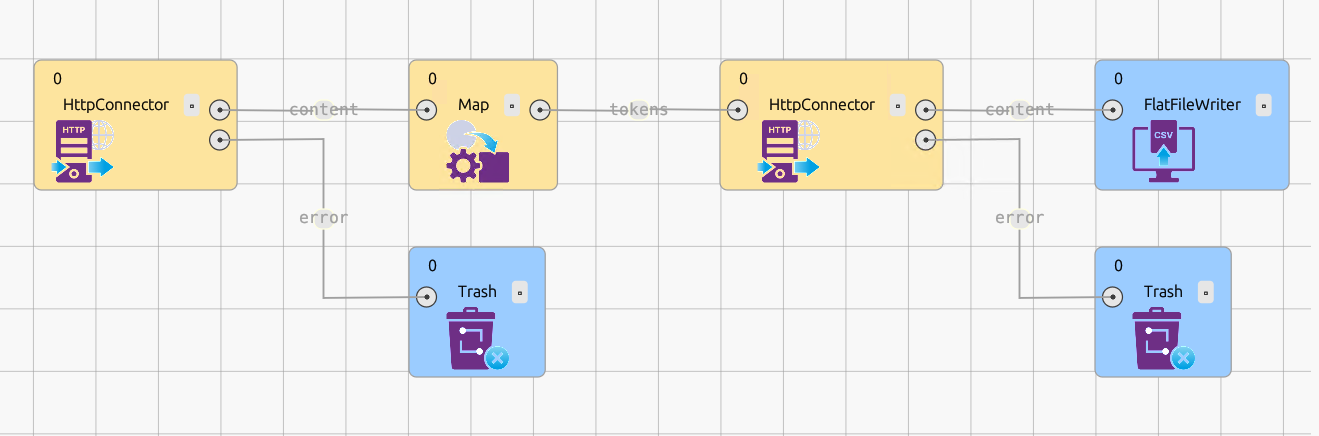
После того как граф отработает, можно просмотреть содержимое ребер в инспекторе ребра. В данном примере на последнем из ребер будет отображаться номер запущенного графа в поле "content".
Просмотр инспектора ребра отработавшего графа
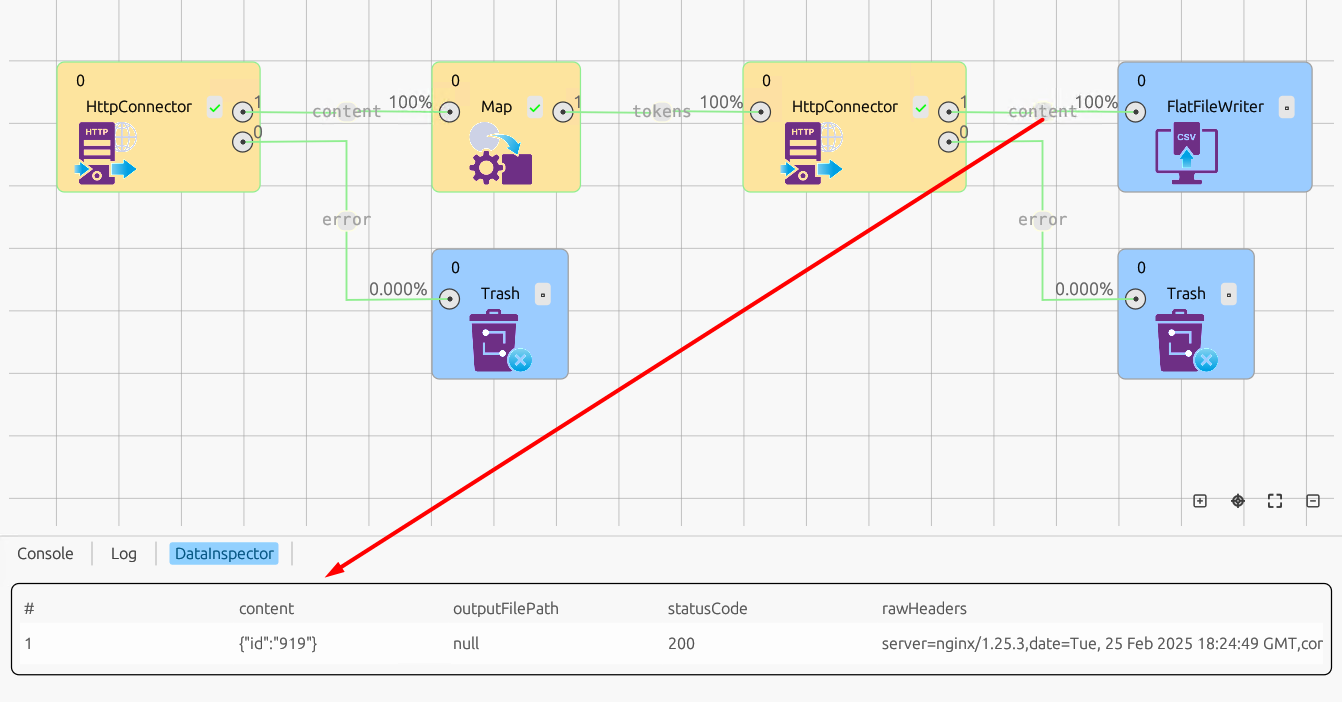
Ролевая модель
Для разграничения прав пользователей в OneBridge существует система привилегий. Каждая привилегия определяет доступный с её помощью набор функциональности. Привилегии можно присвоить напрямую пользователю, а можно - сначала присвоить привилегию роли, а роль - пользователю.
Список присвоенных пользователю привилегий и ролей определяется в момент авторизации и влияет на всю текущую сессию. В зависимости от наличия выданных ролей, части интерфейса и некоторая функциональность могут быть скрыты от пользователя, не обладающего нужными для взаимодействия привилегиями.
Ниже описаны существующие привилегии, которые делятся на 7 групп.
Ресурсы
- Просмотр - доступ к информации о сервере на странице Ресурсы: использование ресурсов, производительность, данные сервера.
Проекты
- Просмотр и скачивание файлов и папок - просмотр списка проектов и их файлов в вебе и в Дизайнере, возможность скачивать данные проектов архивом.
- Создание, изменение и удаление файлов и папок - возможность создавать, переименовывать, редактировать и удалять файлы, папки и проекты.
История выполнения
- Чтение списка запусков, информации и статистики по запускам - просмотр списка запущенных графов на странице Ресурсы и на Истории выполнения.
- Чтение логов запусков - доступ ко вкладке Журнал на панели дополнительной информации на странице История выполнения в вебе и ко вкладке Log в Дизайнере.
- Чтение данных на ребрах - доступ ко вкладке Инспектор на панели доп. информации в веб приложении и к Datainspector в Дизайнере.
- Запуск и остановка графов - просмотр параметров графа, запуск графа в работу и его остановка.
Расписания
- Просмотр - просмотр списка расписаний и информации о каждом из них на странице Расписания.
- Создание, изменение и удаление - создание и модификация расписаний на соответствующей странице веб приложения, управление их статусами и удаление.
Обработчики событий
- Просмотр - просмотр списка обработчиков событий и информации о каждом из них на странице Обработчики событий.
- Создание, изменение и удаление - создание и модификация обработчиков событий на соответствующей странице веб приложения, управление их статусами и удаление.
Пользователи
- Просмотр - просмотр списка пользователей на странице Пользователи, доступ к информации о пользователях, их привилегиях и ролях.
- Создание и изменение - создание пользователя, изменение его статуса, сброс пароля, обновление привилегий и ролей на странице Пользователи в веб приложении.
Роли
- Просмотр - просмотр списка ролей на странице Роли, информации о них, списка их привилегий и списка родительских ролей.
- Создание, изменение и удаление - управление ролями на странице Роли в веб приложении: создание роли, обновление, удаление, изменение её привилегий и родительских ролей.
Маппинг привилегий и методов api
| Группа | Привилегия | Описание метода API | Метод API |
|---|---|---|---|
| Ресурсы | Просмотр | Просмотр использования ресурсов | GET /utilization |
| Просмотр производительности | GET /performance | ||
| Просмотр информации | GET /info | ||
| Проекты | Просмотр и скачивание файлов и папок | Просмотр дерева проектов | GET /tree |
| Просмотр проекта | GET /project | ||
| Просмотр директории | GET /directory | ||
| Просмотр файла | GET /file | ||
| Скачивание архива папки | GET /download | ||
| Создание, изменение и удаление файлов и папок | Создание проекта | POST /project | |
| Переименование проекта | POST /project/rename | ||
| Удаление проекта | DELETE /project | ||
| Создание директории | POST /directory | ||
| Переименование директории/td> | POST /directory/rename | ||
| Удаление директории | DELETE /directory | ||
| Создание файла | POST /file | ||
| Переименование файла | POST /file/rename | ||
| Обновление файла | PATCH /file | ||
| Удаление файла | DELETE /file | ||
| Шифрование параметров | POST /encrypt | ||
| История выполнения | Чтение списка запусков, информации и статистики по запускам | Просмотр запуска | GET /runs/:id |
| Просмотр статистики запуска | GET /runs/:id/stats | ||
| Просмотр содержимого графа | GET /runs/:id/job_content | ||
| Просмотр количества запусков | GET /runs/num | ||
| Просмотр позиции запуска | GET /runs/position | ||
| Список запусков | GET /runs | ||
| Чтение логов запусков | Просмотр логов запуска | GET /runs/:id/log | |
| Чтение данных на ребрах | Просмотр данных на ребре | GET /runs/:id/inspect | |
| Запуск и остановка графов | Просмотр параметров графа | GET /job_params | |
| Создание запуска | POST /runs | ||
| Остановка графа | POST /runs/:id/abort | ||
| Расписания | Просмотр | Список расписаний | GET /schedules |
| Просмотр информации о расписании | GET /schedules/:id | ||
| Создание, изменение и удаление | Создание расписания | POST /schedules | |
| Переключение расписания | POST /schedules/toggle | ||
| Обновление расписания | PATCH /schedules/:id | ||
| Удаление расписания | DELETE /schedules/:id | ||
| Обработчики событий | Просмотр | Список обработчиков событий | GET /event_listeners |
| Просмотр информации об обработчике событий | GET /event_listeners/:id | ||
| Создание, изменение и удаление | Создание обработчика событий | POST /event_listeners | |
| Переключение обработчика событий | POST /event_listeners/toggle | ||
| Обновление обработчика событий | PATCH /event_listeners/:id | ||
| Удаление слушателя событий | DELETE /event_listeners/:id | ||
| Пользователи | Просмотр | Список пользователей | GET /users |
| Просмотр информации о пользователе | GET /users/:id | ||
| Просмотр привилегий пользователя | GET /users/:id/privileges | ||
| Просмотр ролей пользователя | GET /users/:id/roles | ||
| Создание и изменение | Создание пользователя | POST /users | |
| Изменение статуса пользователя | POST /users/:id/toggle_status | ||
| Сброс пароля пользователя | POST /users/:id/reset_password | ||
| Обновление пользователя | PATCH /users/:id | ||
| Обновление привилегий пользователя | PATCH /users/:id/privileges | ||
| Обновление ролей пользователя | PATCH /users/:id/roles | ||
| Роли | Просмотр | Просмотр ролей | GET /roles |
| Просмотр информации о роли | GET /roles/:id | ||
| Просмотр привилегий роли | GET /roles/:id/privileges | ||
| Просмотр родительских ролей | GET /roles/:id/parent_roles | ||
| Создание, изменение и удаление | Создание роли | POST /roles | |
| Обновление роли | PATCH /roles/:id | ||
| Обновление привилегий роли | PATCH /roles/:id/privileges | ||
| Обновление родительских ролей | PATCH /roles/:id/parent_roles | ||
| Удаление роли | DELETE /roles/:id |
Описание всех используемых методов API приведено на странице API Onebridge
API
API OneBridge поддерживает HTTPS-протоколы. В API OneBridge используются GET-, POST-, PATCH- и DELETE-запросы.
Каждый запрос начинается с URL http://<host>, за ним следует название метода и параметры, при необходимости. Например, запрос для получения информации о запуске графа может быть записан так: http://127.0.0.1:3000/api/runs/154 или https://onebridge-dev.dev.allbridge.ru/api/runs/154. В таблицах с описанием методов будут указаны относительные пути URL-запросов.
Список API-методов системы OneBridge, доступных для вызова:
Resources
get info
| Параметр | Значение |
|---|---|
| Описание | Просмотр основной информации о сервере |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
get performance
| Параметр | Значение |
|---|---|
| Описание | Просмотр данных о работе сервера для отображения графиков работы памяти, процессора и запущенных графов |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа | возвращает JSON файл со структурой, которая содержит объекты, описывающие состояние памяти, процессора и запущенных графов:
ram: объект с информацией о памяти cpu: объект с информацией о процессоре job: объект с информацией о запущенных графах |
| Пример ответа |
|
get utilization
| Параметр | Значение |
|---|---|
| Описание | Просмотр данных о количестве используемой памяти сервера |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
Execution
get job params
| Параметр | Значение |
|---|---|
| Описание | Просмотр параметров графа |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get run by id
| Параметр | Значение |
|---|---|
| Описание | Просмотр информации о запуске графа по id |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
get runs
| Параметр | Значение |
|---|---|
| Описание | Просмотр списка графов |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get runs in progress
| Параметр | Значение |
|---|---|
| Описание | Просмотр списка запущенных на данный момент графов |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | Без параметров |
| Структура ответа |
|
| Пример ответа |
|
post runs
| Параметр | Значение |
|---|---|
| Описание | Запускает граф в работу и возвращает номер запущенного графа |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Пример запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get run position
| Параметр | Значение |
|---|---|
| Описание | Просмотр позиции запуска |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get runs log
| Параметр | Значение |
|---|---|
| Описание | Просмотр логов запуска |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа | log: string |
| Пример ответа |
|
get runs num
| Параметр | Значение |
|---|---|
| Описание | Количество запусков графов. Можно добавить фильтр по статусу, дате и имени файла |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get job content
| Параметр | Значение |
|---|---|
| Описание | Просмотр содержимого графа, актуального на момент его запуска |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get run stats
| Параметр | Значение |
|---|---|
| Описание | Просмотр статистики по запуску |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
abort run
| Параметр | Значение |
|---|---|
| Описание | Прерывает выполнение графа |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
get runs inspect
| Параметр | Значение |
|---|---|
| Описание | Возвращает данные о записях, прошедших по указанному ребру. |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | edge:string (id ребра) |
| Структура ответа |
|
| Пример ответа |
|
encrypt
| Параметр | Значение |
|---|---|
| Описание | Шифрует значение параметра. |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | plaintext:string (значение параметра) |
| Структура ответа |
|
| Пример ответа |
|
Projects
get tree
| Параметр | Значение |
|---|---|
| Описание | Просмотр дерева проектов |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
get directory
| Параметр | Значение |
|---|---|
| Описание | Просмотр информации об указанной директории |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get project
| Параметр | Значение |
|---|---|
| Описание | Просмотр информации о проекте |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get file
| Параметр | Значение |
|---|---|
| Описание | Просмотр информации о выбранном файле |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post project
| Параметр | Значение |
|---|---|
| Описание | Создать проект |
| Метод | POST |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post project rename
| Параметр | Значение |
|---|---|
| Описание | Переименовать проект |
| Метод | POST |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post directory
| Параметр | Значение |
|---|---|
| Описание | Создать директорию |
| Метод | POST |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post directory rename
| Параметр | Значение |
|---|---|
| Описание | Изменить название директории |
| Метод | POST |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post file
| Параметр | Значение |
|---|---|
| Описание | Создать файл |
| Метод | POST |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post file rename
| Параметр | Значение |
|---|---|
| Описание | Переименовать файл |
| Метод | POST |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
patch file
| Параметр | Значение |
|---|---|
| Описание | Заменить контент файла |
| Метод | PATCH |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
delete directory
| Параметр | Значение |
|---|---|
| Описание | Удалить директорию |
| Метод | DELETE |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа | ничего не возвращает |
delete file
| Параметр | Значение |
|---|---|
| Описание | Удалить файл |
| Метод | DELETE |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа | ничего не возвращает |
delete project
| Параметр | Значение |
|---|---|
| Описание | Удалить проект |
| Метод | DELETE |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа | ничего не возвращает |
get download folder
| Параметр | Значение |
|---|---|
| Описание | Скачать папку |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа | Возвращает содержимое выбранной папки в виде zip-архива. |
Schedules
get schedules
| Параметр | Значение |
|---|---|
| Описание | Просмотреть список расписаний |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get schedule by id
| Параметр | Значение |
|---|---|
| Описание | Выбор расписания по id |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
get schedules num
| Параметр | Значение |
|---|---|
| Описание | Количество расписаний |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get schedules position
| Параметр | Значение |
|---|---|
| Описание | Позиция расписания по id |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
post schedules
| Параметр | Значение |
|---|---|
| Описание | Создать расписание |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post toggle schedules
| Параметр | Значение |
|---|---|
| Описание | Изменить состояние расписания (вкл/выкл) |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
delete schedules
| Параметр | Значение |
|---|---|
| Описание | Удалить расписание |
| Метод | DELETE |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа | ничего не возвращает |
patch schedules
| Параметр | Значение |
|---|---|
| Описание | Изменить атрибуты расписания |
| Метод | PATCH |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Структура ответа |
|
| Пример ответа |
|
Event listeners
get event listeners
| Параметр | Значение |
|---|---|
| Описание | Просмотр списка обработчиков событий |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get event listener by id
| Параметр | Значение |
|---|---|
| Описание | Выбор обработчика событий по id |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
get event listeners num
| Параметр | Значение |
|---|---|
| Описание | Получить количество расписаний |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get event listeners position
| Параметр | Значение |
|---|---|
| Описание | Получить позицию расписания по его id |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
post event listeners
| Параметр | Значение |
|---|---|
| Описание | Создает обработчик событий |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Структура ответа |
|
toggle event listeners
| Параметр | Значение |
|---|---|
| Описание | Изменить состояние обработчика событий (вкл/выкл) |
| Метод | POST |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
delete event listeners
| Параметр | Значение |
|---|---|
| Описание | Удалить обработчик событий |
| Метод | DELETE |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа | ничего не возвращает |
patch event listeners
| Параметр | Значение |
|---|---|
| Описание | Изменить значения атрибутов обработчика событий |
| Метод | PATCH |
| URL запроса |
|
| Тело запроса |
Все поля опциональные. Но при смене типа события event с "job" на "file" и наоборот, а так же при смене действия action с "Command" на "StartJob" и наоборот - нужно заполнить все сопутствующие атрибуты.
Например, если обработчик был настроен на event "job", и нужно заменить его на event "file", то нужно будет задать значение и для атрибутов filesystem, check, path, interval.
|
| Структура ответа |
|
| Пример ответа |
|
Auth
login
| Параметр | Значение |
|---|---|
| Описание | Авторизация пользователя в системе |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Структура ответа |
|
| Пример ответа |
|
logout
| Параметр | Значение |
|---|---|
| Описание | Завершение сеанса работы в системе |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа | ничего не возвращает |
refresh
| Параметр | Значение |
|---|---|
| Описание | Обновление токена |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
change password
| Параметр | Значение |
|---|---|
| Описание | Смена пароля |
| Метод | POST |
| URL запроса |
|
| Тело запроса |
|
| Структура ответа | ничего не возвращает |
Users
post user
| Параметр | Значение |
|---|---|
| Описание | Создание пользователя |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post toggle user status
| Параметр | Значение |
|---|---|
| Описание | Изменение статуса пользователя |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
post reset user password
| Параметр | Значение |
|---|---|
| Описание | Сброс пароля пользователя |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
patch user
| Параметр | Значение |
|---|---|
| Описание | Редактирование данных пользователя. Поменять можно полное имя (fullname) и email |
| Метод | PATCH |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Структура ответа | ничего не возвращает |
get user by id
| Параметр | Значение |
|---|---|
| Описание | Просмотр информации о пользователе |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get users
| Параметр | Значение |
|---|---|
| Описание | Просмотр списка пользователей |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
Roles
get roles
| Параметр | Значение |
|---|---|
| Описание | Просмотр списка ролей |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
get role
| Параметр | Значение |
|---|---|
| Описание | Просмотр конкретной роли по её id |
| Метод | GET |
| URL запроса |
|
| Параметры запроса |
|
| Структура ответа |
|
| Пример ответа |
|
post role
| Параметр | Значение |
|---|---|
| Описание | Создание роли |
| Метод | POST |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Пример ответа | ничего не возвращает |
patch role
| Параметр | Значение |
|---|---|
| Описание | Редактирование роли |
| Метод | PATCH |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Пример ответа | ничего не возвращает |
delete role
| Параметр | Значение |
|---|---|
| Описание | Удаление роли |
| Метод | DELETE |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа | ничего не возвращает |
get privileges
| Параметр | Значение |
|---|---|
| Описание | Просмотр списка всех существующих привилегий |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
get role privileges
| Параметр | Значение |
|---|---|
| Описание | Просмотр привилегий роли |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
patch role privileges
| Параметр | Значение |
|---|---|
| Описание | Обновление привилегий роли |
| Метод | PATCH |
| URL запроса |
|
| Параметры запроса | без параметров |
| Тело запроса |
|
| Структура ответа | ничего не возвращает |
get role subroles
| Параметр | Значение |
|---|---|
| Описание | Просмотр субролей роли по её id |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
patch role subroles
| Параметр | Значение |
|---|---|
| Описание | Изменение субролей роли |
| Метод | PATCH |
| URL запроса |
|
| Тело запроса |
|
| Структура ответа | ничего не возвращает |
get user roles
| Параметр | Значение |
|---|---|
| Описание | Просмотр ролей конкретного пользователя |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
patch user roles
| Параметр | Значение |
|---|---|
| Описание | Обновление ролей пользователя |
| Метод | PATCH |
| URL запроса |
|
| Тело запроса |
|
| Структура ответа | ничего не возвращает |
get user privileges
| Параметр | Значение |
|---|---|
| Описание | Просмотр привилегий пользователя |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
patch user privileges
| Параметр | Значение |
|---|---|
| Описание | Обновление привилегий пользователя |
| Метод | PATCH |
| URL запроса |
|
| Тело запроса |
|
| Структура ответа | ничего не возвращает |
get version
| Параметр | Значение |
|---|---|
| Описание | Возвращает актуальную версию сборки приложения |
| Метод | GET |
| URL запроса |
|
| Параметры запроса | без параметров |
| Структура ответа |
|
| Пример ответа |
|
Выпущенные версии OneBridge
| Номер версии | Дата выпуска | Описание |
|---|---|---|
| 1.22.0 | 2025-07-18 | Добавлена возможность скачивать одиночные файлы из проектов. Реализован сброс значений атрибутов графа до дефолтных при настройке расписаний и обработчиков событий. Изменена работа апи get schedules и get event_listeners, убран вывод ненужных параметров. В Dbjoin добавлена обработка null в значении ключевых полей.
В истории выполнения, на вкладке Обзор параметры графа теперь сортируются по имени параметра. Для графов, запущенных не вручную, выводится название вызвавшего их расписания или обработчика события. Исправлен поиск графов по проектам при создании\редактировании расписаний и обработчиков и налажено выравнивание столбцов в таблице обработчиков. В таблице Отслеживание в истории выполнения закреплена строка заголовка для удобства отслеживания деталей запуска графа. В дизайнере поправлена ошибка при чтении большого лога и обновлено отображение дизейблинга узлов. В Outline теперь выводится имя справочника (лукапа), а не его id. Исправлено оповещение при перемещении файла между директориями и в окно удаления объектов добавлена конкретизация объекта удаления. |
| 1.21.0 | 2025-03-21 | Доработана интеграция с LDAP, добавлен учет входов для LDAP пользователей. Проведена подготовка для внедрения нового языка преобразований. Скорректирована логика API для расписаний, обработчиков событий, пользователей и ролей. Исправлена работа поиска для пользователей, ролей, расписаний, обработчиков событий.
Переработана ролевая модель. Исправлена ошибка выхода из системы для пользователя без привилегий. Исправлены дефолтные значения для некоторых атрибутов узлов. Изменена схема копирования ребер и узлов. |
| 1.20.0 | 2025-02-03 | Добавлен узел HTTP_CONNECTOR. Проведен рефакторинг worker. Добавлена аутентификация LDAP пользователей. Добавлены проверки в узлы MergeJoin, DBReader и ExecuteGraph.
Доработаны апи для работы с запуском графов и информацией о хосте. В дизайнере исправлено наложение вкладок с файлами на панель компонентов, поправлено отображение статистики на ребрах графа, исправлен диалог удаления метаданных и вывод версии сборки. |
| 1.19.0 | 2024-12-24 | Добавлен узел CONCATENATE. Добавлены возможности: копировать и линковать справочники и переменные, перезапускать графы со старыми параметрами, возможность выбрать какое содержимое графа использовать - из истории или актуальное из проекта, принудительно запустить граф с карточки расписания и обработчика событий, запустить обработчики событий в зависимости от статуса выполненного графа. Улучшена защита при передаче зашифрованных параметров. Добавлен роутинг на странице проектов. В дизайнер добавлена возможность отключать узлы (дизейблинг) и копировать файлы.
Исправлены замечания по работе ODBC, добавлен шаблон подключения. Исправлен алгоритм расчёта статистики, работа расписаний и обработчиков событий. Скорректирована работа с дефолтными значениями для переменных и доработан вывод статистики на ребра графа. |
| 1.18.0 | 2024-11-12 | Добавлены узлы - AGGREGATE, DEDUP, INPUT_TABLE, LOOKUP_TABLE_READER, LOOKUP_TABLE_WRITER. Добавлен роутинг на все страницы. Отказались от SSE в web и в designer. Хранение и вывод всех данных теперь в локальном времени. Добавлен параметр enabled для узлов. Теперь можно отключать и включать узлы для упрощения тестирования графов. Реализованы справочники (lookup tables). Добавлена возможность шифровать параметры. В расписаниях и событиях добавлен выбор проекта и графа отдельно.
Исправлена некорректная работа обработчиков событий. Соединение PostgresODBC в узле DBExecute теперь закрывается. Больше не двоятся кавычки при попытке записать их в базу Postgres. NaN в значении поля с типом float корректно обрабатывается. Убрана проверка дефолтных значений dictionary. Устранена паника в коре при запуске невалидного графа через execute graph. Улучшен обработчик событий. Реализован новый подход подключениий к серверам. Произведена корректировка типов и дефолтных значений атрибутов. Исправлены некоторые собщения об ошибках. Скорректирована проверка на целостность при сохранении файла. |
| 1.17.0 | 2024-09-03 | Добавлен параллельный запуск графов через узел ExecuteGraph. В DBReader исправлено чрезмерное потребление памяти. Соединение odbc теперь закрывается самостоятельно. Исправлены баги в работе MergeJoin, HashJoin, DbExecute, DataIntersection.
Добавлено отображение дерева запусков на страницу Ресурсы в вебе. Исправлены сохранение и передача информации о создании и
редактировании расписаний и слушателей. Для расписаний и слушателей событий теперь отображается статус последнего
запущенного графа. |
| 1.16.0 | 2024-08-05 | Добавлена возможность использовать printdebug в трансформациях и сохранять информацию по выполнению графа в преднастроенные dictionary. В историю выполнения добавлено дерево графов и исправлен вывод статистики на ребра графа. Поправлена работа джойнов. В дизайнере добавлено копирование метаданных, сетка для автовыравнивания узлов на рабочей области. Устранён баг с дублированием id при добавлении новых узлов, при закрытии дизайнера проверяется наличие файлов с несохранёнными изменениями и выводится диалог. Исправлена работа ctrl+z. |
| 1.15.0 | 2024-07-11 | Добавлены узлы EXECUTE_SCRIPT, LIST_FILES. Исправлены ошибки в поведении DATA_INTERSECTION, DBEXECUTE, DBJOIN, HASH_JOIN, EXECUTE_GRAPH. Добавлена возможность менять порядок метаданных в редакторе, сортировать все элементы панели Outline, копировать полный путь любого файла. Исправлено отображение ролей. Улучшен механизм присвоения меты ребрам - теперь можно перетаскивать метаданные с Outline прямо на ребро. Изменён механизм управления запусками узлов. |
| 1.14.0 | 2024-06-17 | Исправлена работа dataInspector и DATA_INTERSECTION, отображение графиков в Ресурсах. Изменено поведение EXECUTE_GRAPH и POSTGRESQL_DATA_WRITER. |
| 1.13.0 | 2024-06-07 | Добавлены новые узлы: DATA_INTERSECTION, DBJOIN. Реализовано апи для dataInspector. Обновлено окно для генерации крон выражения при создании расписания. В дизайнере исправлена работа с горячими клавишами и типы некоторых полей, а также цвет теста на узлах и валидация графа перед запуском. Исправлены баги в отображении статистики и настройка расписаний при редеплое. Обновлена логика работы ребер. |
| 1.12.0 | 2024-05-20 | Реализована выгрузка проектов и папок в виде архива, импорт настроек соединений и метаданных из файлов, добавлена поддержка firebird. На страницу ресурсов добавлен новый график запущенных графов. Устранены ошибки в работе узлов DB_EXECUTE, EXECUTE_GRAPH. Внесены правки в дизайнер в части отображения соединений с базами данных, добавлена возможность перетаскивать метаданные на ребро способом 'drag-and-drop', исправлено отображение редакторов объектов. |
| 1.11.0 | 2024-04-23 | Реализованы узлы: DB_EXECUTE, EXECUTE_GRAPH, SUCCESS, FAIL, RAW_READER, RAW_WRITER. Устранены ошибки в работе узлов ROLLUP, CROSS_JOIN, FLAT_FILE_READER, SPREADSHEET_READER. Внесены правки в дизайнер в части отображения атрибутов и узлов, добавлены заметки. |
| 1.10.0 | 2024-02-29 | Улучшены сообщения об ошибках. Частично настроено использование sse для обновления данных. В дизайнер добавлена возможность подстановки параметров во все атрибуты. |
| 1.9.0 | 2024-01-25 | Добавлены новые узлы, исправлены ошибки. Доработан дизайнер. |
| 1.8.0 | 2023-12-28 | Проведён рефакторинг имеющихся API и дизайнера. |
| 1.7.0 | 2023-12-08 | Проведён рефакторинг имеющихся узлов. |
| 1.6.0 | 2023-12-01 | Добавлен сбор и вывод статистики в инспектор, добавлены узлы. В дизайнере обновлена логика заполнения атрибутов узлов, исправлены редакторы метаданных и узлов. |
| 1.5.0 | 2023-10-01 | Добавлена базовая аутентификация, добавлены узлы для обработки данных, добавлена генерация и редактирование графов в дизайнер. |
| 1.4.0 | 2023-09-01 | Проведен рефакторинг созданных узлов, разработан дизайнер. |
| 1.3.0 | 2023-08-01 | Добавлены уведомления о событиях модуля управления и реализованы новые узлы. |
| 1.2.0 | 2023-07-01 | Добавлены обработчики событий и реализованы новые узлы. |
| 1.1.0 | 2023-06-01 | Добавлена функция создания расписаний запусков графов и реализованы новые узлы. |
| 1.0.0 | 2023-05-01 | В модуле управления реализованы основные инструменты для управления графами и наблюдения за производительностью сервера. |
Дорожная карта OneBridge
3-й квартал 2025:
- Реализация компилируемого языка в трансформациях с отказом от поддержки javascript.
- Реализация новой схемы лицензирования с подтверждением через центральный сервер OneBridge.
- Внедрение обновленной структуры XML-файлов.
- Реализация узлов (нод) для работы с алгоритмами машинного обучения.
- Реализация узлов (нод) для работы с LLM.
4-й квартал 2025:
- Возможность принудительной остановки выполнения графа. "Мягкая" - с ожиданием корректного завершения графов и "жесткая" - с принудительным завершением процессов. Перезагрузка сервера через веб-интерфейс панели администрирования.
- Реализация веб-приложения для дизайнера с сохранением возможности работы в рамках отдельного приложения.
- Реализация в дизайнере возможностей табличной настройки маппингов, подсветки кода, подсветки использования в графе элементов из Outline, возможности валидации пользовательского кода.
- Разделение в рамках сервера OneBridge модулей управления и выполнения графов с взаимодействием через специализованный протокол и возможностью отдельного выделения ресурсов под каждый модуль.
- Реализация коннекторов к 1С, Kafka LDAP, Email.
1-й квартал 2026:
- Настройка и изменение параметров конфигурации через веб-интерфейс панели администрирования.
- Автоматическое создание метаданных на основе запросов к БД или заголовков файлов.
- Автоматическое "пробрасывание" (propogate) метаданных по ребрам графа.
- Реализация специализированных узлов (нод) для партиционирования данных.
- Реализация специализированных узлов (нод) для работы с XML и JSON.
- Разделение прав доступа к отдельным проектам.
2-й квартал 2026:
- Расширение возможностей просмотра данных в дизайнере (пред- и пост-фильтры, размер окна).
- Работа с локальными таймзонами в веб-интерфейсе панели администрирования.
- Настройка параметров LDAP через панель администрирования.
- Ограничение просмотра шифрованных данных в дизайнере и вывода в лог.
- Возможность использования PostgreSQL и других СУБД в качестве БД сервера OneBridge.
- Реализация работы с подграфами.
3-й квартал 2026:
- Возможность создания пользовательских нод.
- Возможность развертывания кластера серверов выполнения.
- Взаимодействие панели администрирования и дизайнера с сервером через веб-сокеты, реализация автосохранения и (в случае дизайнера) автономной работы без запуска графов.
Пример 1. Работа с простыми файлами, преобразование, запись данных в базу. Автоматизация запуска графа.
Описание задачи
Разработать граф для загрузки данных из CSV файла в таблицу. Добавить поля со временем создания и обновления записей. Изменить в поле price символ точки, на запятую.
Настроить расписание и обработчик событий, вызвать созданный граф из другого графа.
Создание графа для преобразования данных и записи в базу
- Чтобы создать новый граф, найдите в структуре своего проекта на панели Project structure папку
grapf, в которую поместите граф. Кликните правой кнопкой на папку graph, выберите в меню пунктNew grf file. Задайте имя графа, напримерload_ecommerce_behavior.grfи нажмите Создать. - Привяжите к графу внешний файл параметров:
панель Outline -> Parameters -> Link parameters ->вставьте путь к файлу параметров./workspace.prmв полеfileURL. - Привяжите также файл с описанием соединения с базой:
панель Outline -> Connections -> Link connection ->вставьте путь к файлу соединения./conn/demo2.conв полеdbConfig. - Перетащите на рабочую область с панели компонентов узлы CsvReader, Map, PostgresSqlDataWriter.
- Соедините порты узлов рёбрами. Вытягивайте ребро из выходного порта (с правой стороны) узла и отпускайте, когда довели курсор до входного порта (с левой стороны) другого узла.
- Создайте 2 меты через редактор метаданных.
- на панели Outline откройте контекстное меню раздела
Metadata ->выберите пунктNew metadata. Задайте имя метаданных -ecommerce_behavior. Создайте 8 полей типа string:event_time,event_type,product_id,category_id,category_code,brand,price,user_id,user_session/ Чтобы добавить поля в мету используйте кнопку+. Чтобы удалить ненужное поле - кнопку- - на панели Outline откройте контекстное меню метадаты
ecommerce_behavior ->выберите пунктCopy metadata. Скопируйте метуecommerce_behaviorи вставьте ее через контекстное меню разделаMetadata -> Paste metadata. Откройте редактор и смените название меты наecommerce_behavior_out. Добавьте еще два поля типа date:created_at,updated_at
- на панели Outline откройте контекстное меню раздела
- Перетащите мету
ecommerce_behaviorс панели Outline на ребро между узлами CsvReader и Map, а метуecommerce_behavior_outна ребро между Map и PostgresSqlDataWriter. - Заполните значения атрибутов узлов. Чтобы открыть редактор узла, дважды кликните по его поверхности.
- в CsvReader нужно вставить имя файла-источника данных в поле
fileURL=${DATAIN_DIR}/2019-Nov.csv - в Map заполнить поле
transformкодом трансформации на внутреннем языке Onebridge. Код приведён ниже в таблице "Атрибуты MAP". - в PostgresSqlDataWriter выберите имя нужного
dbConnectionиз списка, вставьте имя таблицы для записи в полеtable, и укажите параметры для записи вparameters
- в CsvReader нужно вставить имя файла-источника данных в поле
Полный список значений атрибутов для каждого узла приведён в следующем разделе Атрибуты используемых узлов.
На рисунке ниже представлен созданный граф для загрузки данных из CSV файла в базу:
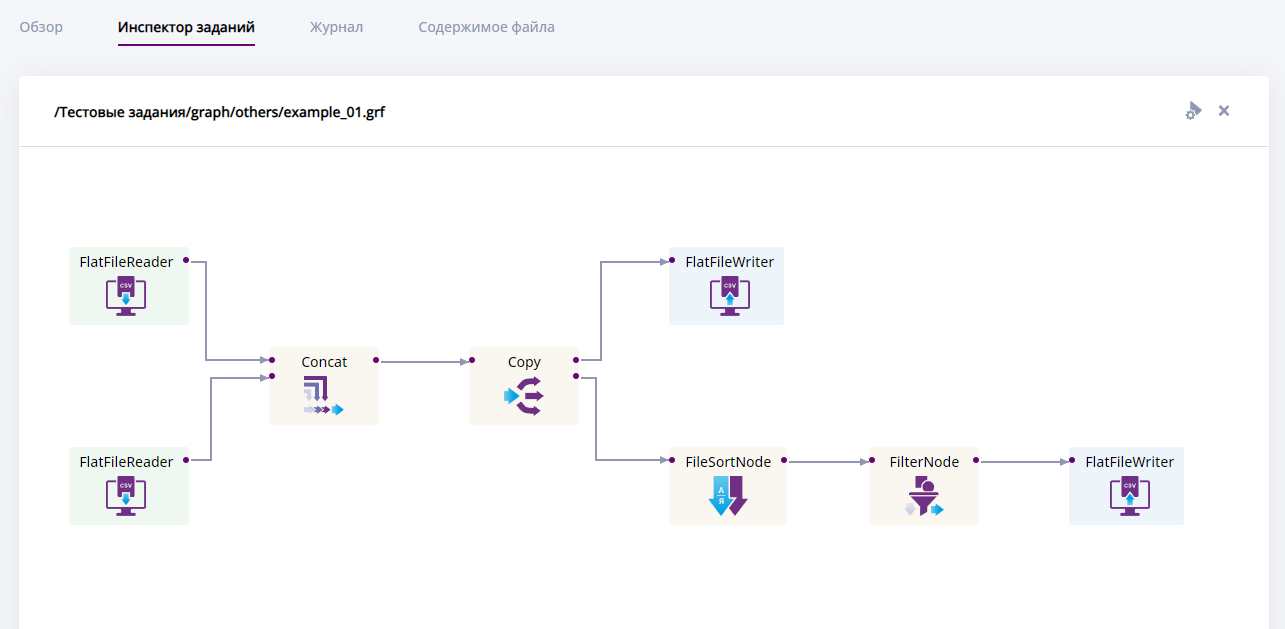
Атрибуты используемых узлов
Атрибуты CSV_READER:
| Атрибут | Значение | Описание |
|---|---|---|
| phase | 0 | Фаза узла |
| node name | CsvReader | Имя узла, отображаемое в рабочей области |
| enabled | true | Работоспособность узла |
| fileURL | ${DATAIN_DIR}/2019-Nov.csv | Путь к источнику данных |
| charset | UTF_8 | Кодировка файла-источника |
| dataPolicy | strict | Политика обработки некорректных данных при чтении |
| trim | default | Флаг удаления начальных и конечных пробелов в момент прохождения через данный узел |
| header | true | Флаг удаления заголовка файла |
| quotedStrings | false | Флаг восприятия спец. символов |
| quoteChar | both | Спец. символ для атрибута quotedStrings |
| fieldDelimiter | , | Разделитель полей |
| recordDelimiter | \n | Разделитель записей |
Атрибуты MAP:
| Атрибут | Значение | Описание |
|---|---|---|
| phase | 0 | Фаза узла |
| node name | CsvReader | Имя узла, отображаемое в рабочей области |
| enabled | true | Работоспособность узла |
| transform |
| Код для преобразования данных и присвоения значений выходным метаданным |
Атрибуты POSTGRESQL_DATA_WRITER:
| Атрибут | Значение | Описание |
|---|---|---|
| phase | 0 | Фаза узла |
| node name | CsvReader | Имя узла, отображаемое в рабочей области |
| enabled | true | Работоспособность узла |
| dbConnection | ./conn/demo2.con | Имя соединения с базой |
| table | ecommerce_behavior | Имя таблицы для записи |
| parameters |
| Параметры для утилиты psql и оператора copy, используемых узлом POSTGRESQL_DATA_WRITER |
Вызов графа из другого графа
Чтобы вызвать созданный граф из другого графа, используйте узел ExecuteGraph.
- Создайте новый граф, задайте имя, например
startLoad - На рабочую область нужно поместить единственный компонент - ExecuteGraph
- Откройте редактор атрибутов узла и задайте в поле
jobURLимя графа, который нужно запустить:jobURL = ./graph/load_ecommerce_behavior.grf - Сохраните изменения атрибутов узла, сохраните граф
CTRL+S.
Так будет выглядеть граф для вызова другого графа:
Теперь, если запустить startLoad.grf, он следом запустит внутренний граф load_ecommerce_behavior.grf.
Результат выполнения можно будет увидеть в панели администратора на странице История выполнения.
Общее время выполнения графа выводится в строку "Продолжительность" на вкладку Обзор. Затем можно перейти к просмотру данных по внутреннему графу через дерево графов в правой верхней части экрана.
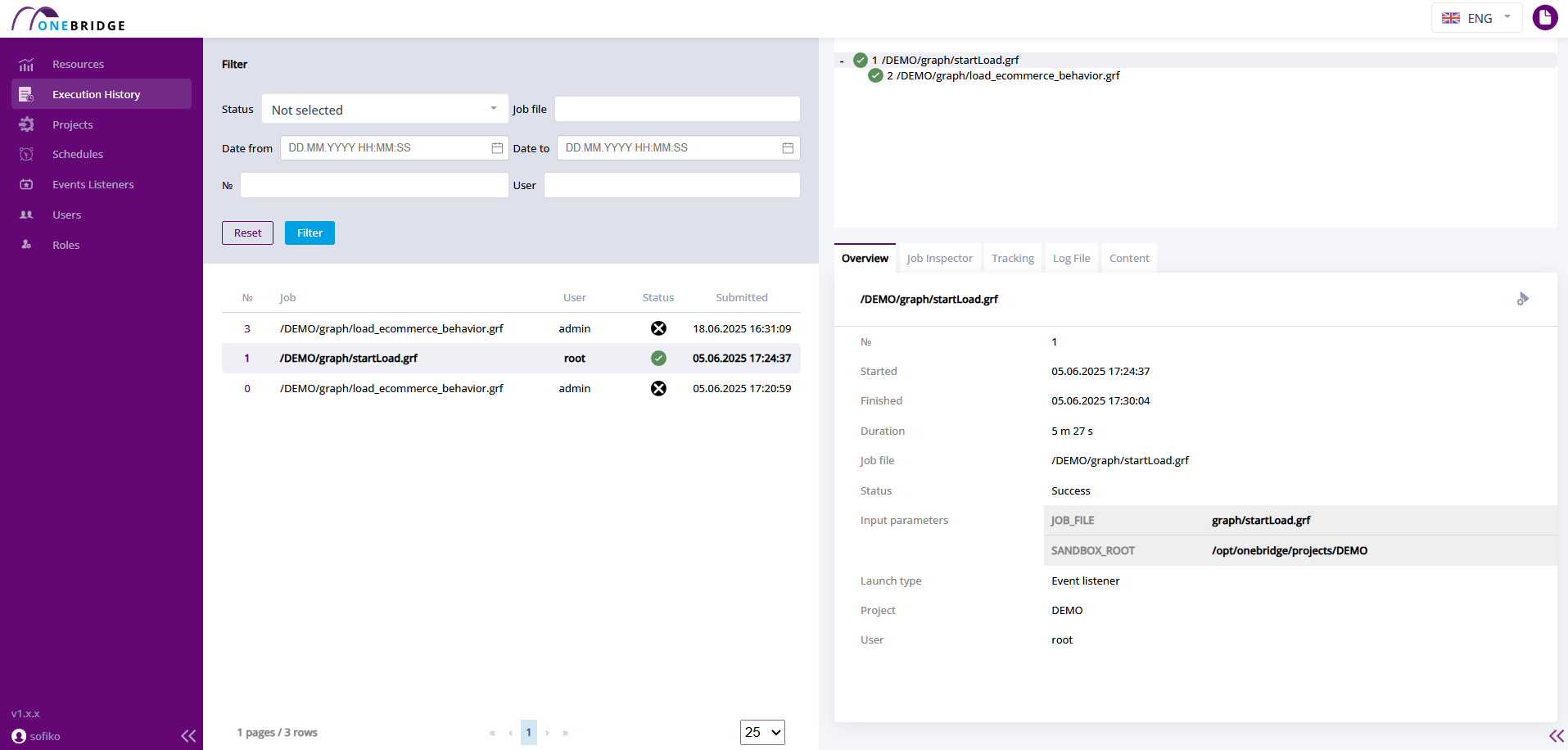
Скорость выполнения внутреннего графа можно проверить на вкладке Отслеживание. В столбец "Длительность" выводится длительность работы каждого узла в рамках фазы. На приведенном ниже примере видно, что все узлы работали одновременно одинаковое количество времени.
В столбце "ЗАПИСЕЙ" указано общее количество записей, обработанных данным узлом. В столбце "ЗАПИСЕЙ/СЕК СР" - среднее количество записей, обрабатываемых узлом за секунду.
Рассчитаем общую среднюю скорость работы фазы: Общее количество записей поделим на общее время работы всех узлов, получится, что средняя скорость обработки около 207 698 записей в секунду. Для конкретного CSV-файла это примерно 27063 Кб в секунду.
Таким образом система может обработать 100Гб данных (около 800 млн записей) за ~65 минут.
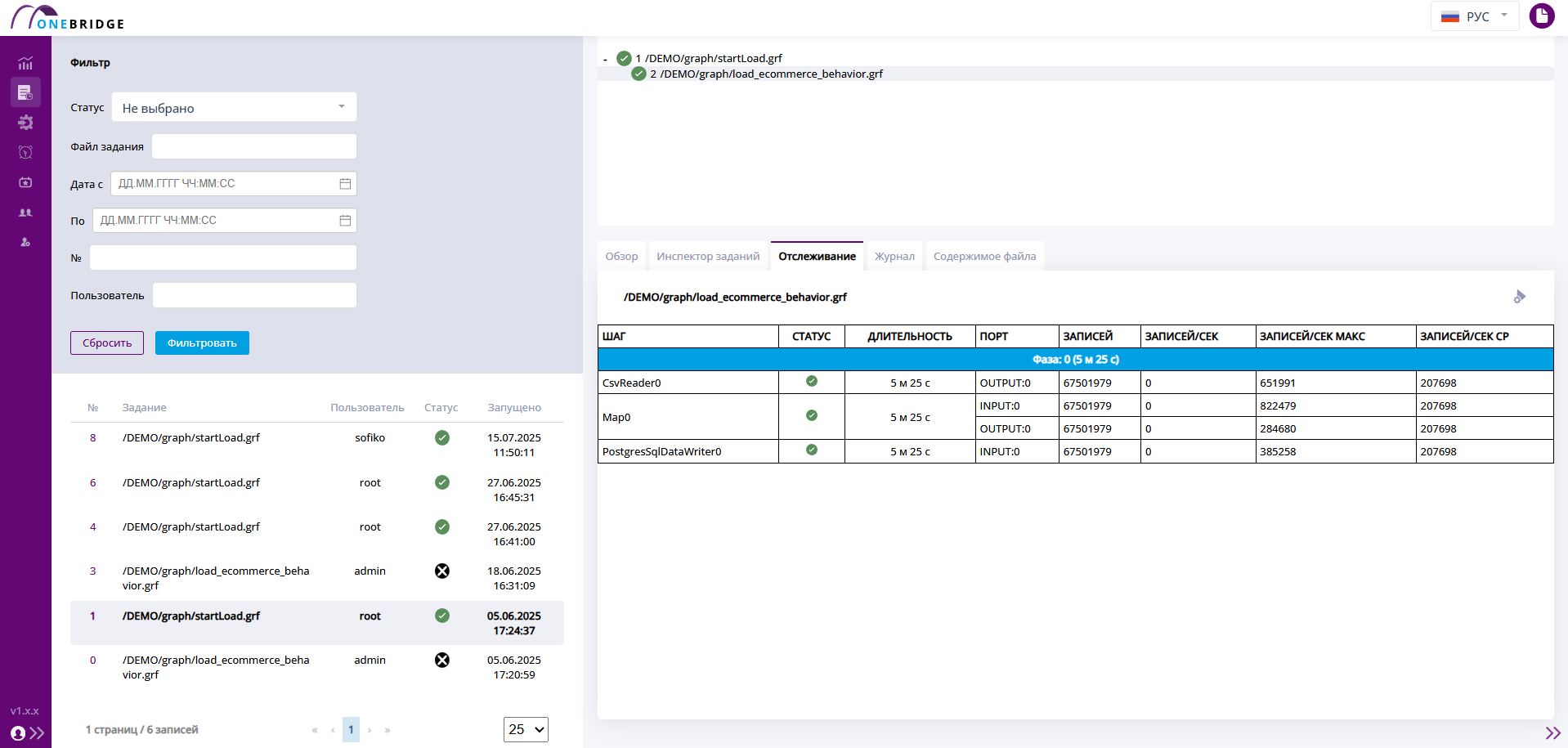
Создание расписания
Чтобы запустить граф в определенное время в автоматическом режиме, можно использовать расписание.
- Для этого в панели администратора на странице Расписания диалог создания расписаний.
- Задайте имя -
Расписание запуска startLoad.grf, периодичность -Один раз, время исполнения, выберите проект и граф. Сохраните расписание.
Граф будет запущен в назначенное время.
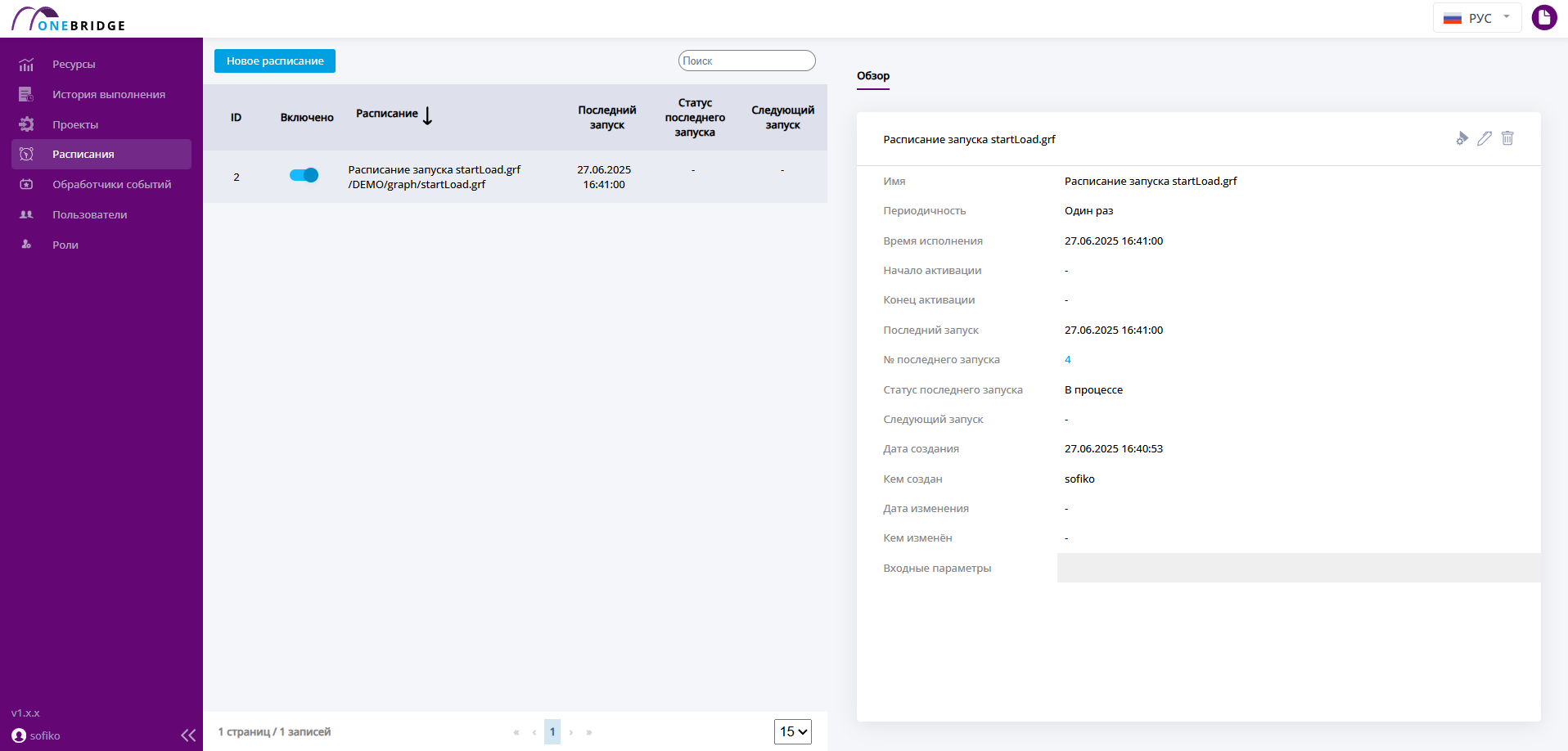
Результат выполнения графа отобразится в панели администратора на странице История выполнения. На вкладке Обзор в поле "Тип запуска" будет указано по расписанию, а в "Пользователь" - root.
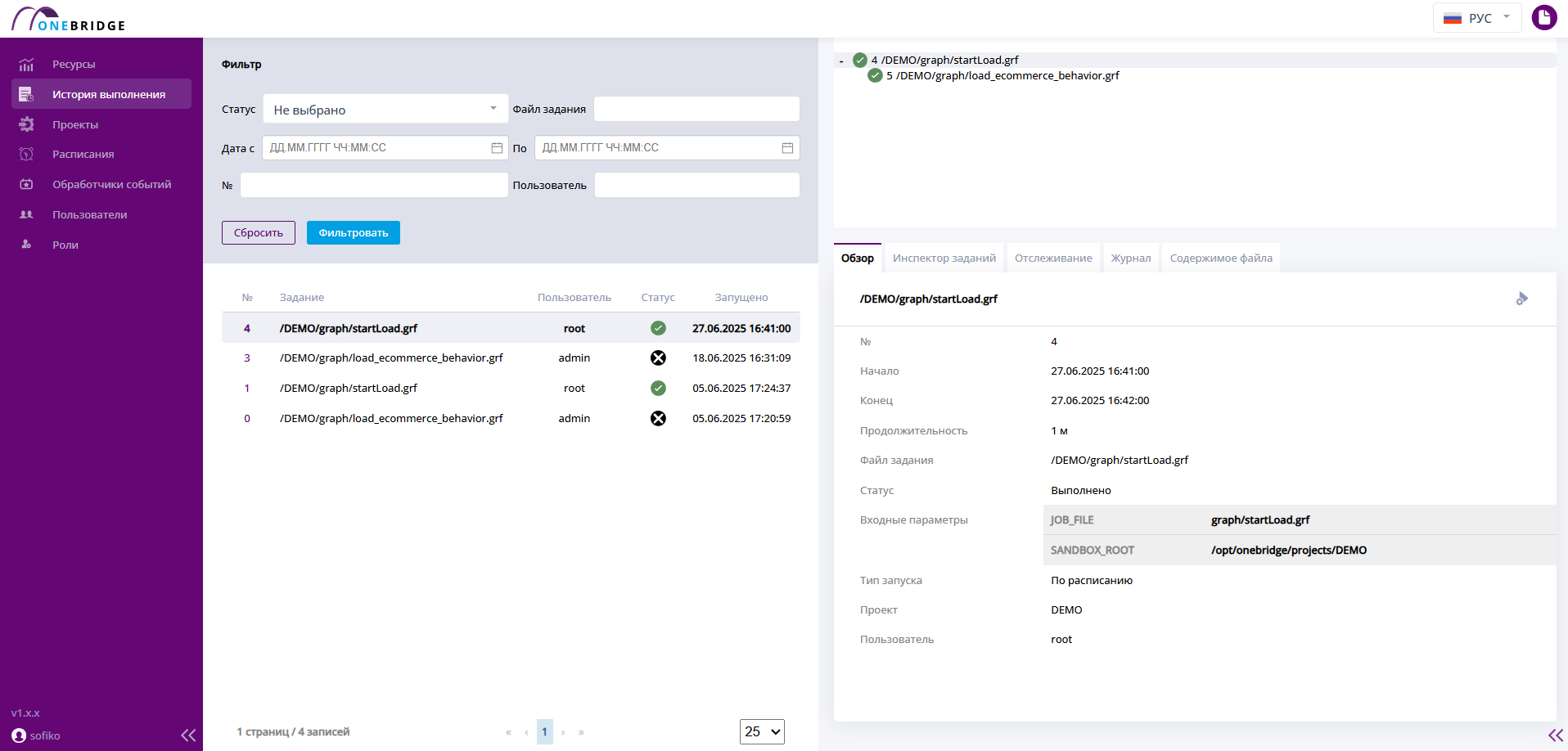
Создание обработчика событий
Если нужно, чтобы граф запускался по событию - нужно настроить обработчик для события. Триггерным событием для обработчика может быть окончание работы графа с определенным статусом либо создание/удаление файла в указанной директории.
- В панели администратора, на странице Обработчики событий, вызовите диалог создания обработчика кнопкой Новый обработчик.
- Задайте название обработчика, например,
Поступил файл. Выберите запускающее событие -Файли укажите необходимость проверить добавление файла в директорию/srv/projects/DEMO/data-in/*.csv. Задайте действие, которое надо выполнить -Запуск графаи его параметры: проект -DEMO, граф -/graph/startLoad.grf. Сохраните обработчик.
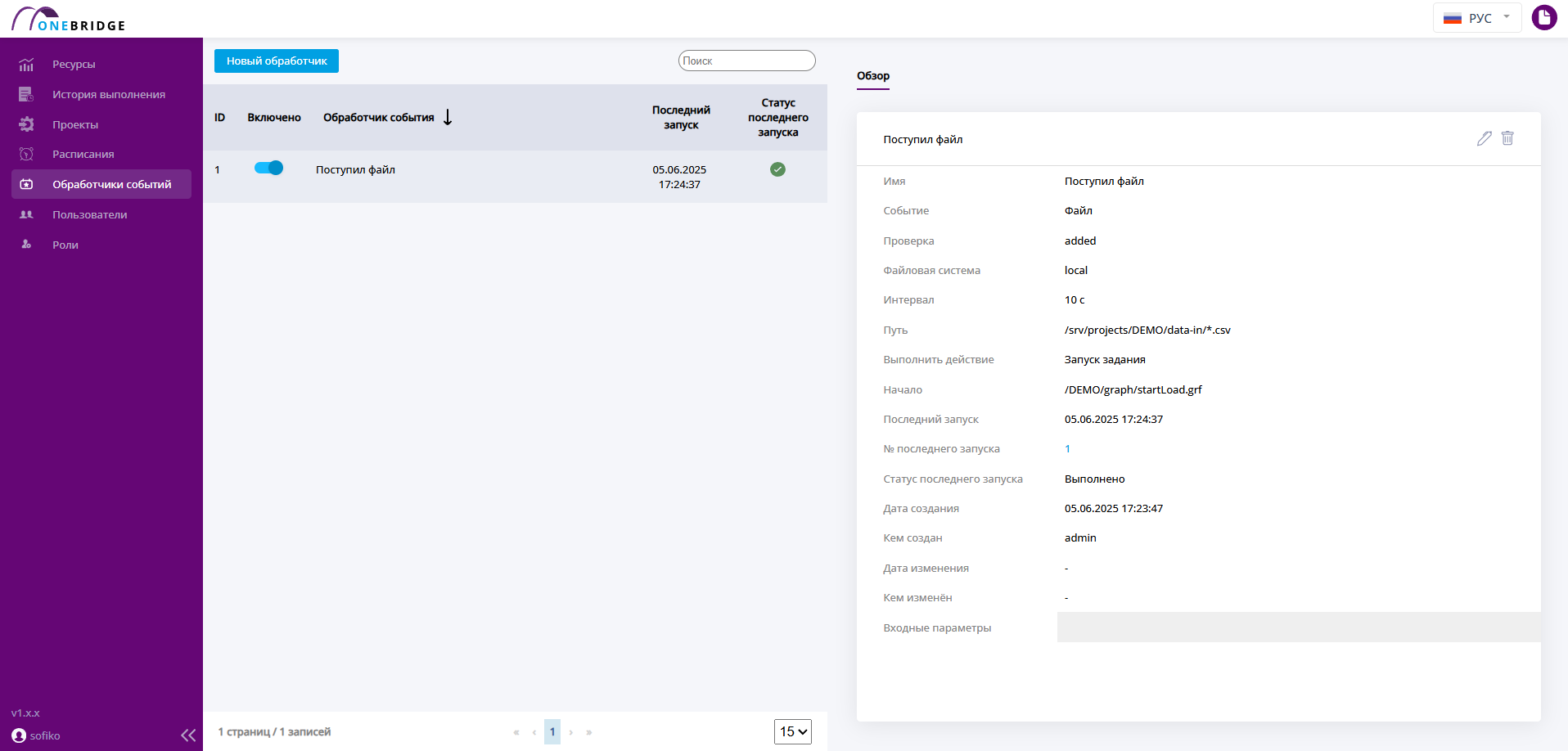
Когда триггерное событие случится, указанный в поле "Начало" граф будет запущен. Проверить выполнение графа можно на истории выполнения. На вкладке Обзор в поле "Пользователь" будет root, а в поле "Тип запуска" будет указано по какому событию запущен этот граф.